Hybrid Architecture in Data Vault 2.0
Business users expect their data warehouse systems to load and prepare more and more data, regarding the variety, volume, and velocity of data. Also, the workload that is put on typical data warehouse environments is increasing more and more, especially if the initial version of the warehouse has become a success with its first users. Therefore, scalability has multiple dimensions. Last month we talked about Satellites, which play an important role in scalability. Now we explain how to combine structured and unstructured data with a hybrid architecture.
In this article:
Logical Data Vault 2.0 Architecture
The Data Vault 2.0 architecture is based on three layers: the staging area which collects the raw data from the source systems, the enterprise data warehouse layer, modeled as a Data Vault 2.0 model, and the information delivery layer with information marts as star schemas and other structures. The architecture supports both batch loading of source systems and real-time loading from the enterprise service bus (ESB) or any other service-oriented architecture (SOA).
The following diagram shows the most basic logical Data Vault 2.0 architecture:
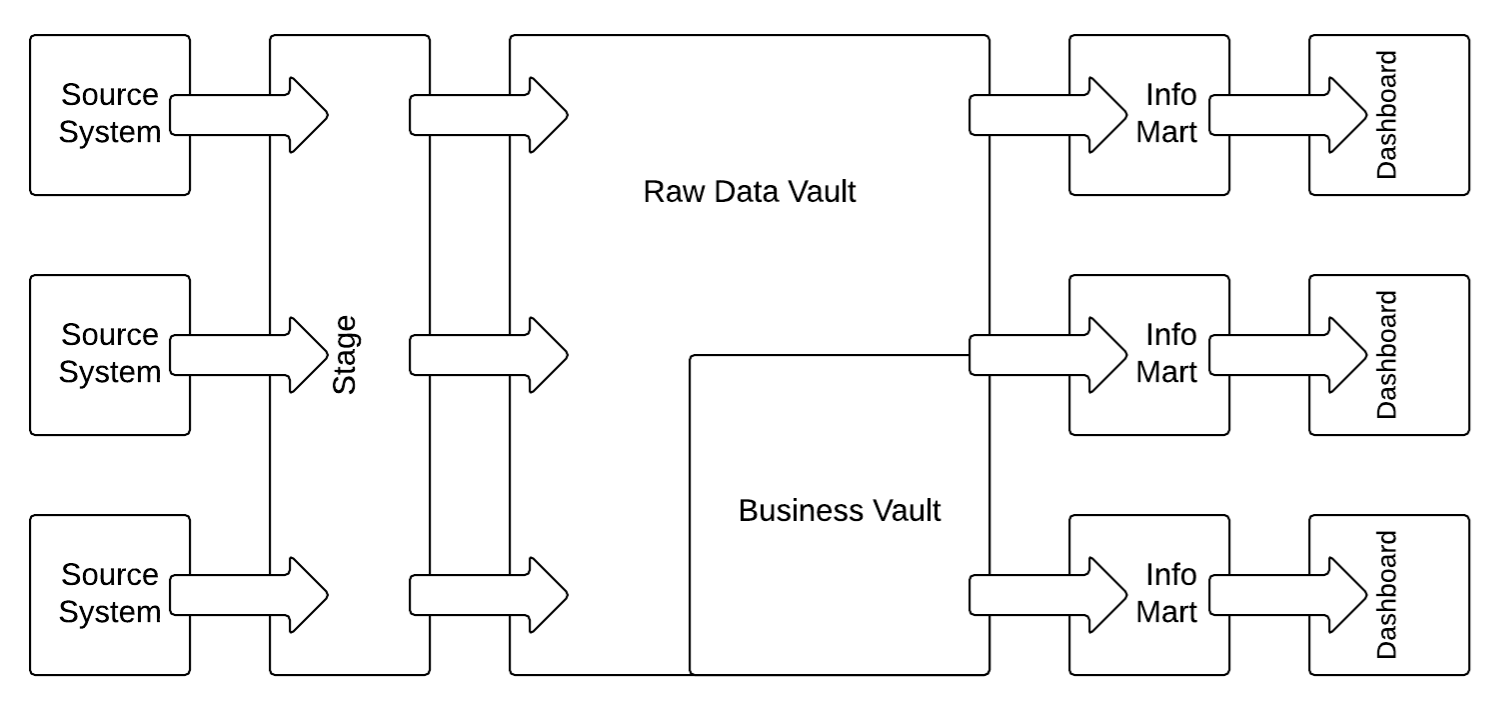
In this case, structured data from source systems is first loaded into the staging area to reduce the operational / performance burden from the operational source systems. It is then loaded unmodified into the Raw Data Vault which represents the Enterprise Data Warehouse layer. After the data has been loaded into this Data Vault model (with hubs, links, and satellites), business rules are applied in the Business Vault on top of the data in the Raw Data Vault. Once the business logic is applied, both, the Raw Data Vault and the Business Vault are joined and restructured into the business model for information delivery in the information marts. The business user is using dashboard applications (or reporting applications) to access the information in the information marts.
The architecture allows implementation of the business rules in the Business Vault using a mix of various technologies, such as SQL-based virtualization (typically using SQL views), and external tools, such as business rule management systems (BRMS).
However, it is also possible to integrate unstructured NoSQL database systems using a hybrid architecture. Due to the platform independence of Data Vault 2.0, NoSQL can be used for every data warehouse layer, including the stage area, the enterprise data warehouse layer, and information delivery. Therefore, the NoSQL database could be used as a staging area and load data into the relational Data Vault layer. However, it could also be integrated both ways with the Data Vault layer via a hashed business key. In this case, it would become a hybrid architecture solution and information marts would consume data from both environments.
Hybrid Architecture
The standard Data Vault 2.0 architecture in Figure 1 focuses on structured data. Because more and more enterprise data is semi-structured or unstructured, the recommended best practice for a new enterprise data warehouse is to use a hybrid architecture based on a Hadoop cluster, as shown in the next figure:
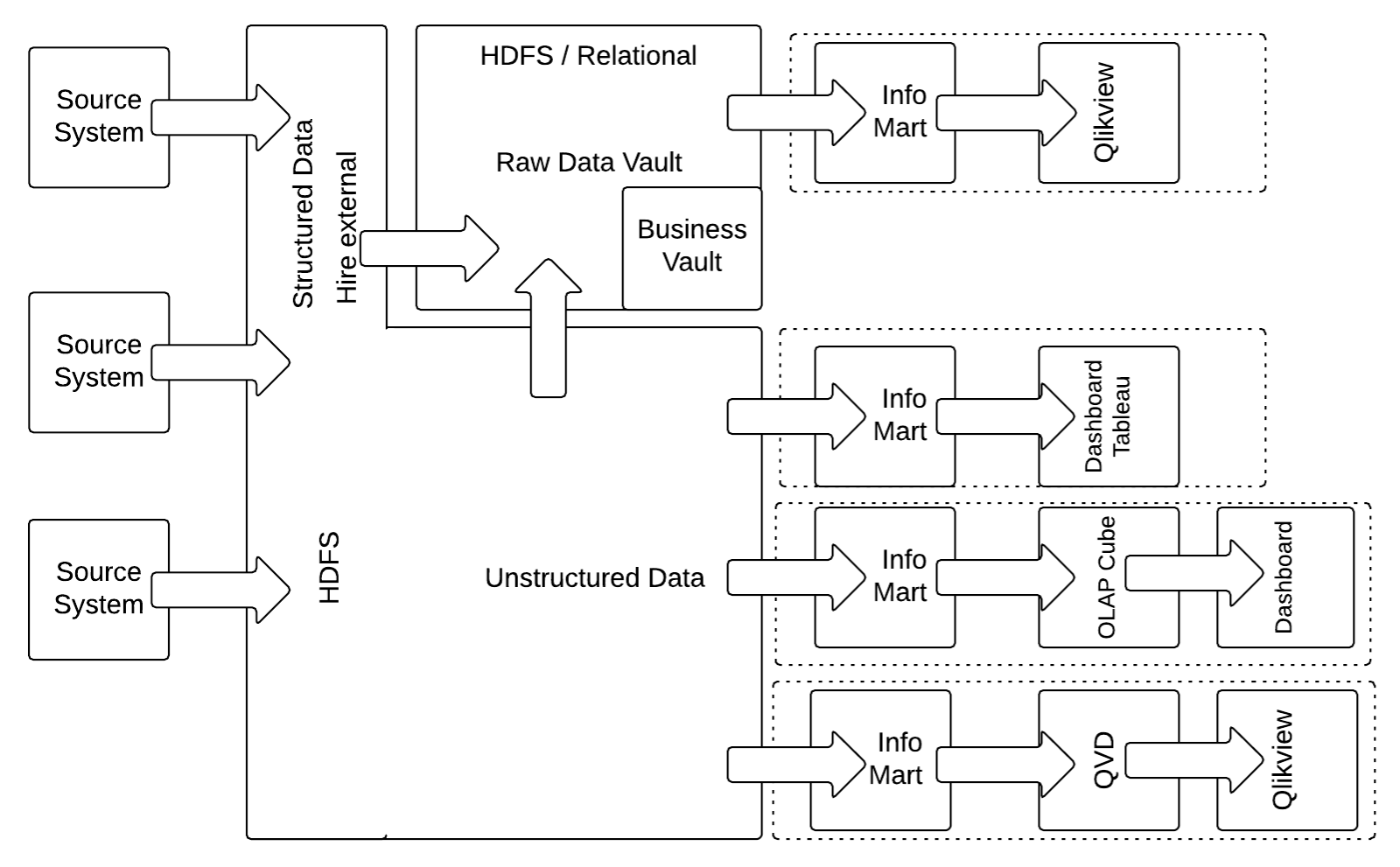
In this hybrid architecture modification, the relational staging area is replaced by a HDFS based staging area that captures all unstructured and structured data. While capturing structured data on the HDFS appears as overhead at first glance, this strategy actually reduces the burden of the source system by making sure that the source data is always being extracted, regardless of any structural changes. The data is then extracted using Apache Drill, Hive External, or similar technologies.
It is also possible to store the Raw Data Vault and the Business Vault (the structured data in the Data Vault model) on Hive Internal.
Build Better Data Platforms
Practical architecture insights for modern data teams. Join 8,000+ data professionals.
Get Free InsightsConclusion
Integrating a hybrid architecture within Data Vault 2.0 enables organizations to effectively manage both structured and unstructured data by leveraging platforms like Hadoop. This approach enhances scalability and flexibility, allowing for efficient data processing and storage. By replacing traditional relational staging areas with HDFS-based systems, businesses can reduce the burden on source systems and ensure seamless data extraction

I found the article on hybrid architecture in Data Vault 2.0 to be quite insightful! It really highlights the need for flexibility in data management and how hybrid approaches can enhance data warehousing capabilities. Looking forward to implementing some of these strategies at work!
Great insights on hybrid architecture! I appreciate the clarity on how to optimize data loading in Data Vault 2.0. It’s fascinating to see how businesses can adapt to increasing data demands with innovative solutions. Looking forward to implementing some of these strategies!
Great insights on the hybrid architecture! It’s fascinating how this approach can streamline data processing and enhance efficiency in data warehousing. Looking forward to seeing more developments in this area!
This article provides great insights into how hybrid architecture can enhance data warehouse systems. It’s fascinating to see how it can handle increasing data loads!