CI/CD
CI/CD pipelines are becoming increasingly important for ensuring that software updates can be released cost-effectively while maintaining high quality. But how exactly do CI/CD pipelines work, and how can a project benefit from using one?
This newsletter aims to answer these questions through a practical example of a CI/CD pipeline. The example focuses on a CI/CD pipeline for a GitHub repository that includes a package for implementing Data Vault 2.0 in dbt across various databases. Therefore, this newsletter will also cover the basics of dbt and GitHub Actions.
From Continuous Integration To Data Vaults: A Comprehensive Workflow
This webinar will cover what CI/CD pipelines are and the advantages they offer. We will present parts of the CI/CD pipeline for the public datavault4dbt package to demonstrate how a CI/CD pipeline can be used. The webinar will introduce the key features of GitHub Actions and explain them through examples. This will show how each feature can be utilized in practice and highlight the various possibilities GitHub Actions offers. The webinar aims to explain the benefits of CI/CD pipelines and illustrate what such a pipeline can look like through a practical example.
What is CI/CD?
CI stands for Continuous Integration, and CD stands for Continuous Delivery or Continuous Deployment. But what exactly do these terms mean?
Continuous Integration refers to the regular merging of code changes, where automated tests are conducted to detect potential errors early and ensure that the software remains in a functional state.
Continuous Delivery involves making the validated code available in a repository. CI tests should already be conducted in the pipeline for this purpose. It also includes further automation needed to enable rapid deployment, such as creating a production-ready build. The difference between Continuous Delivery and Continuous Deployment is that with Continuous Deployment, the successfully tested software is released directly to production, while Continuous Delivery prepares everything for release without automatically deploying it.
Continuous Deployment allows changes to be implemented quickly through many small releases rather than one large release. However, the tests must be well-configured, as there is no manual gate for transitioning to production.
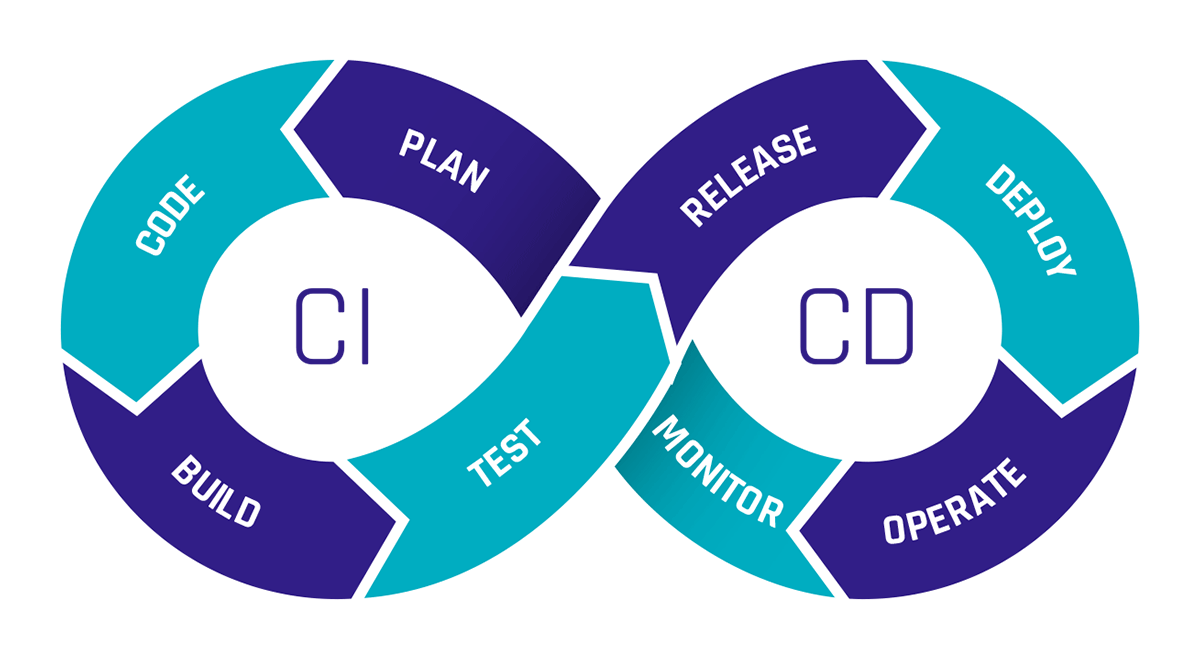
CI/CD pipelines provide immense time savings through automation. The costs of resources needed for manual testing are also lower with CI/CD pipelines, as they can be configured to spin up resources only for testing and then shut them down afterward. Since permanent resources aren’t required, you only pay for the resources needed during the test runtime.
Introduction to dbt
The abbreviation dbt stands for “data build tool.” dbt is a tool that enables data transformation directly within a data warehouse. It uses SQL-based transformations that can be defined, tested, and documented directly in the dbt environment.
This makes dbt an excellent choice for implementing Data Vault 2.0 as dbt can be used to create and manage the hubs, links, and satellites required by Data Vault.
To facilitate this process, we at Scalefree have developed the datavault4dbt package. Datavault4dbt offers many useful features, such as predefined macros for hubs, links, satellites, the staging area, and much more.

For a deeper understanding of dbt or datavault4dbt, feel free to read one of our articles on the topic.
The Capabilities of GitHub Actions
GitHub Actions is a feature of GitHub that allows you to create and execute workflows directly within GitHub repositories. You can define various triggers for workflows, such as pull requests, commits, schedules, manual triggers, and more.
This makes GitHub Actions ideal for building CI/CD pipelines for both private and public repositories. The workflows are divided into multiple jobs, each consisting of several steps. Each job runs on a different virtual machine.
Within these steps, you can define custom tasks or utilize external or internal workflows. This offers the significant advantage of not having to develop everything from scratch in a workflow; instead, you can leverage public workflows created by others.
The seamless integration of Docker also provides numerous possibilities, such as quickly setting up different test environments, which greatly simplifies the creation of a CI/CD pipeline.
GitHub Actions is the key tool in the following example of a CI/CD pipeline.
Practical Example: CI/CD Pipeline for datavault4dbt
For the public repository of the datavault4dbt package, we have built a CI/CD pipeline to ensure that all features continue to function across all supported databases with every pull request (PR). When a PR is submitted by an external user, someone from our developer team must approve the start of the pipeline. In contrast, a PR from an internal user can be automated by adding a specific label to initiate the pipeline.
Once the pipeline is triggered, GitHub Actions automatically starts a separate virtual machine (VM) for each database. Currently, the datavault4dbt package supports AWS Redshift, Microsoft Azure Synapse, Snowflake, Google BigQuery, PostgreSQL, and Exasol, so a total of six VMs will be launched. Since GitHub Actions operates in a serverless manner, these VMs do not need to be manually set up or managed.
The VMs then connect to the required cloud systems. For instance, the VM for Google BigQuery connects to Google Cloud, while the VM for AWS Redshift connects to AWS. Subsequently, the necessary resources for each database are generated, which can be done via API calls or using tools like Terraform.
After the resources are created, additional files required for testing are generated and loaded onto the VM. In our example pipeline, these include files such as profiles.yml, which contains information needed by dbt to connect to the databases.
Next, a Dockerfile is used on each VM to build an image that automatically installs all dependencies for the respective database. At this stage, Git is also installed on each image so that tests stored in a separate Git repository can be loaded onto the image.
Loading the tests from a repository allows for centralized management of the tests, ensuring any changes are executed for each database during the next pipeline run. Once the images are built, containers are created using these images, where tests are conducted with various parameters. After all tests are completed, the containers are shut down, and by default, the resources on the respective cloud providers are deleted.
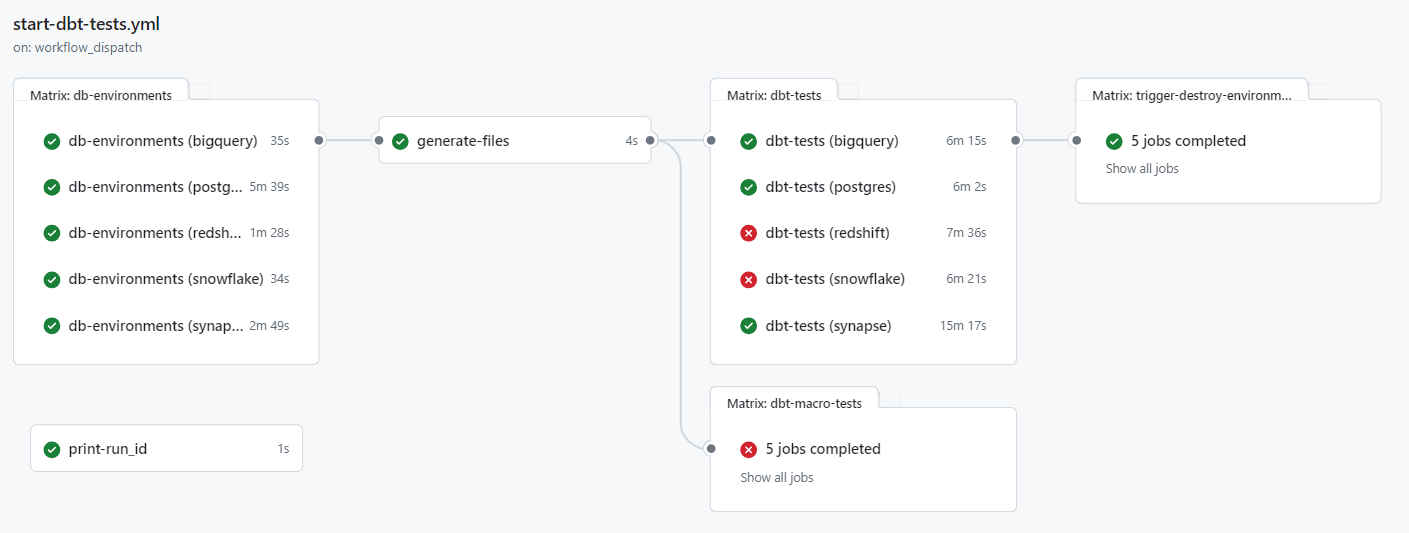
The test results are fully visible in GitHub Actions, with successful and failed tests clearly marked.

If the pipeline is started manually, there is an additional option to specify whether only certain selected databases should be tested and whether the resources on the cloud systems should not be deleted after the tests. This allows developers to examine the data on the databases more closely in case of an error.
This pipeline offers numerous advantages for the development of the datavault4dbt package. It allows testing for errors on any of the supported databases with each change, without spending much time creating test resources. At the same time, it saves costs because all resources run only as long as necessary and are immediately shut down after the tests.
Managing the pipeline is also simplified through GitHub, as all variables and secrets can be stored directly in GitHub, providing a centralized location for everything. Once the pipeline is set up, it can be easily extended to include additional databases that may be supported in the future.
Ultimately, this is just one example of what a CI/CD pipeline can look like. Such pipelines are as diverse as the software for which they are designed. If we have piqued your interest and you have further questions about a possible pipeline for your company, please feel free to contact us.
Conclusion
This newsletter explores the benefits and workings of CI/CD pipelines in agile software development, illustrated through a practical example involving a GitHub repository and a dbt package for implementing Data Vault 2.0, highlighting tools like GitHub Actions for automation and efficiency in deployment processes.
– Damian Hinz (Scalefree)