Organizations often struggle in managing their data efficiently. Data is usually spread across many separate systems, constantly growing in size and complexity, and required for an increasing number of uses. Even seasoned experts struggle with these challenges. To address this, approaches like Data Fabric, Data Vault, and Data Mesh have become important for building robust and flexible data platforms and ensuring efficient processes.
However, these new approaches also add further complexity for data platform management. This article explores how to combine these three concepts to create a strong and efficient data architecture that data architects can use as a foundational guide.
Data Vault & Data Mesh in a Data Fabric: A Modern Architecture Guide
This webinar will provide a brief overview of Data Fabric, Data Vault, and Data Mesh, and then delve into the advantages that can be realized by combining these approaches. Register for our free webinar May 13th, 2025!
The Data Fabric: Unifying Distributed Data Ecosystems
To address the challenges of managing data scattered across diverse and distributed environments, the Data Fabric has emerged as an architectural approach. It leverages metadata-driven automation and intelligent capabilities to create a unified and consistent data management layer. This framework facilitates seamless data access and delivery, ultimately enhancing organizational agility.
Key characteristics of a Data Fabric include:
- Unified Data Access: Providing integrated data access for diverse user needs.
- Centralized Metadata: Utilizing an AI-augmented data catalog for data discovery and comprehension.
- Enhanced and Metadata-Driven Automation: Promoting efficiency and scalability through automated processes. Intelligent automation powered by comprehensive metadata management.
- Strengthened Governance and Security: Standardizing procedures to improve governance and security.
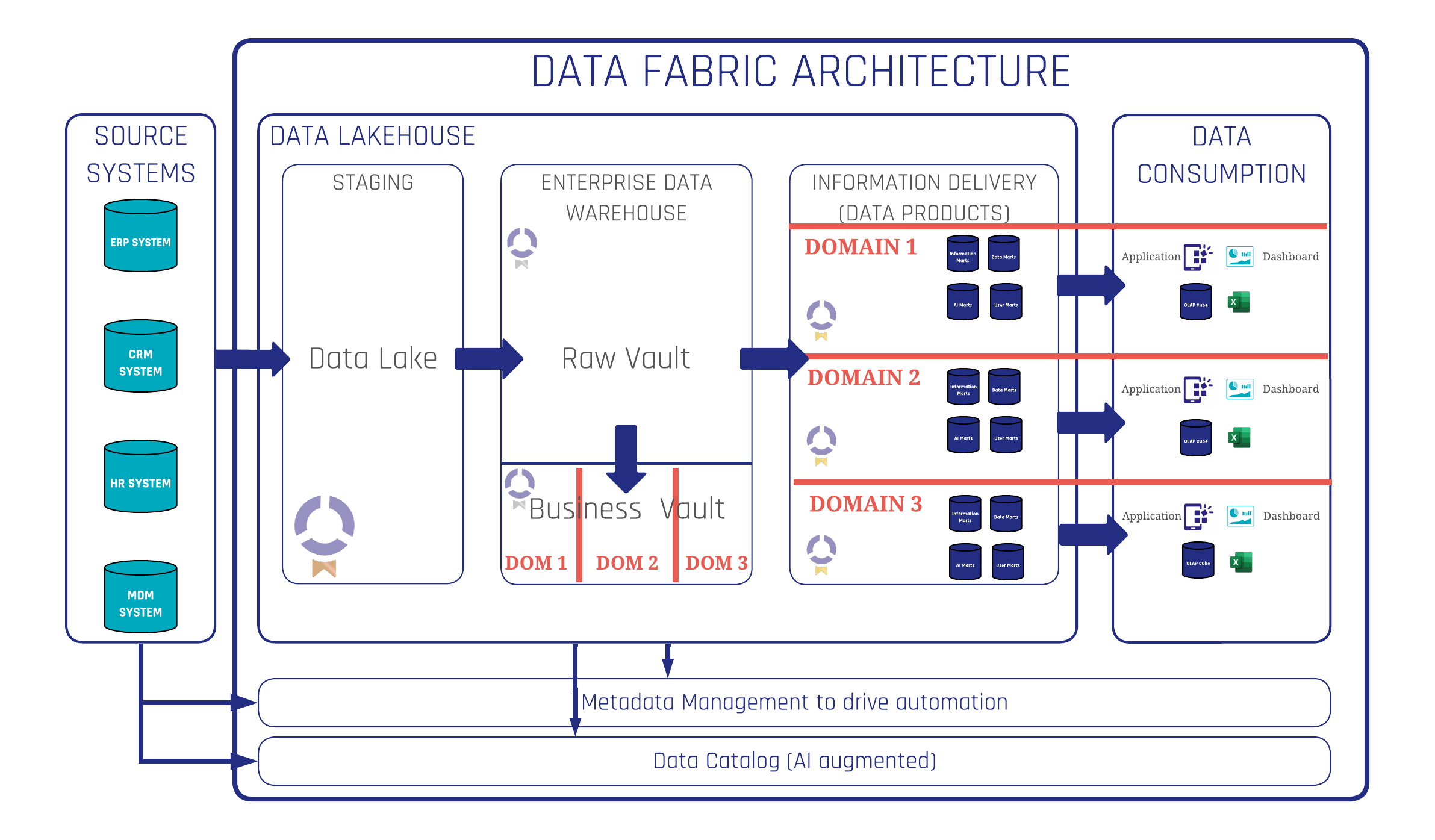
A modern Data Fabric platform integrates a spectrum of systems and processes to streamline data management. This evolution begins with the incorporation of data from diverse source systems, such as ERP, CRM, HR, and MDM. Subsequently, a Data Lakehouse is integrated, featuring a staging area for data preparation.
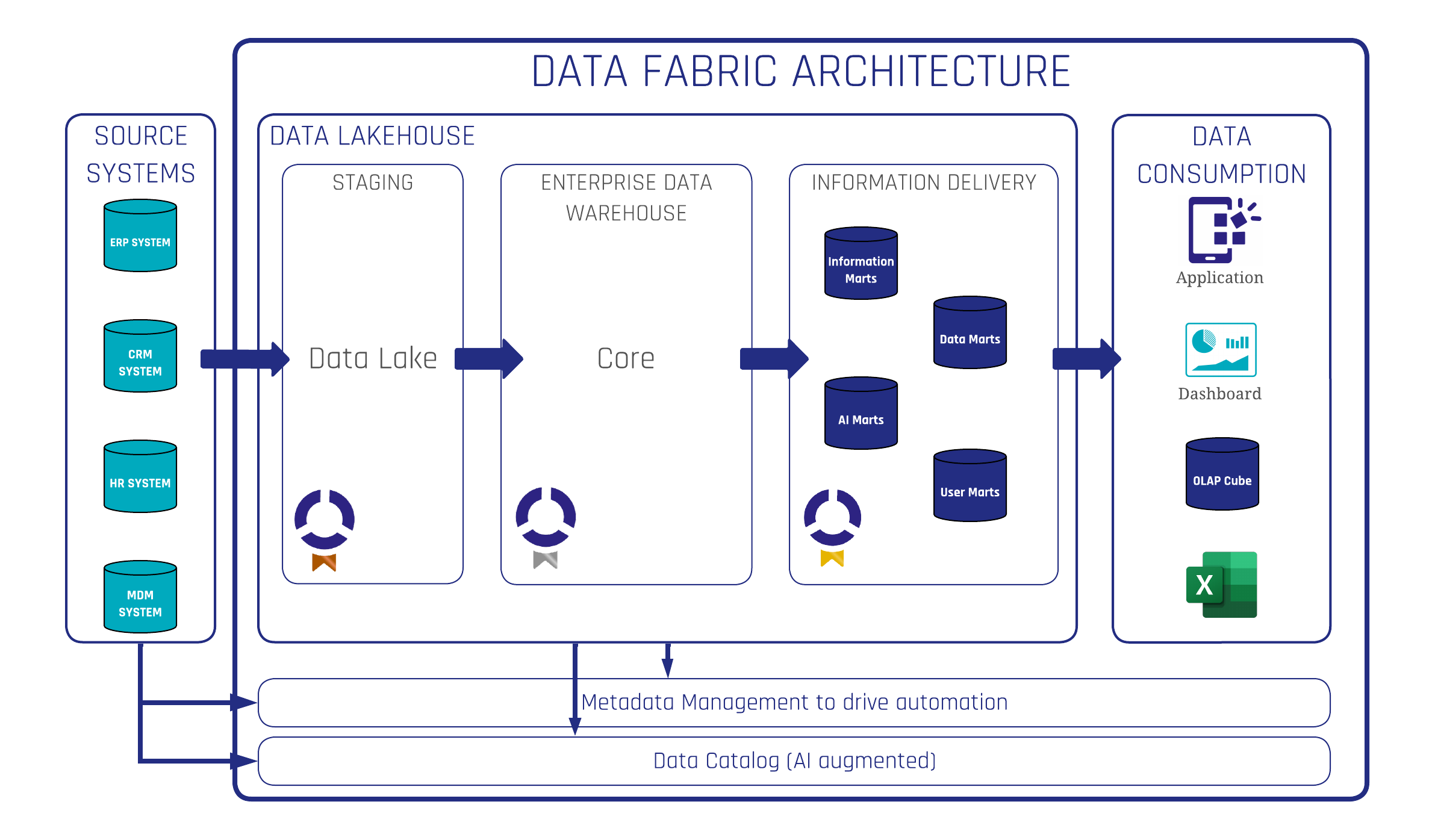
The architecture further encompasses an Enterprise Data Warehouse for core data storage, followed by the implementation of information marts, AI marts, and user marts for tailored information delivery. At last, the platform supports various data consumption methods, including applications, dashboards, and OLAP cubes.
The Data Lakehouse also shows the three medallion layers, which represent the raw data (bronze layer), integrated data layer (Silver) and information delivery layer (Gold) with its data products ready for consumption.
Critical to this architecture is robust metadata management and an AI-augmented data catalog, which together drive automation and facilitate data discovery.
Data Vault: Establishing a Single Source of Facts
Data Vault as a data modeling methodology is designed for the construction and maintenance of enterprise data warehouses. Renowned for its flexibility, scalability, and emphasis on historical data, Data Vault aligns seamlessly with the goal of a unified and consisting data management layer of a Data Fabric and its automation focus.
Key benefits of a Data Vault include:
- Scalability: Adapting to growing data volumes and complexity.
- Flexibility: Accommodating evolving business requirements.
- Consistency: Ensuring data integrity across the enterprise.
- Pattern based modeling: Perfect foundation for data automation.
- Auditability: Providing a clear and traceable data history.
- Agility: enabling faster responses to change business needs.
Within a modern Data Fabric platform, a Data Vault model is implemented within the Enterprise Data Warehouse component. The Raw Data Vault integrates all source systems into business objects and its relationships. The sparsely built Business Vault on top of the Raw Data Vault adds advanced Data Vault entities for e.g. query assistants to ease the creation and increase the performance of the information delivery layer.

This approach delivers all advantages listed above and enables a high level of automation due to its pattern based modeling method.
Data Mesh: Decentralizing Data Ownership and Access
Data Mesh is a decentralized approach to data management that prioritizes domain ownership, data as a product, self-service data platforms, and federated governance. This approach shifts data management responsibilities to domain-specific teams, fostering greater accountability and agility.
Key principles include:
- Domain Ownership: Decentralized management of analytical and operational data.
- Data as a Product: Treating analytical data as a valuable and managed asset.
- Self-Service Data Platform: Providing tools for independent data sharing and management.
- Federated Governance: Enabling collaborative governance across domains.
- Decentralized data domains: Each domain managing its own data products.
Implementing a Data Mesh on a Data Fabric platform requires several essential components like standardized DevOps processes and modeling guides, as well as a comprehensive data catalog.
Although fully distributing the data pipeline via a Data Mesh presents certain attractions, our experience indicates that a more effective strategy involves selectively integrating key Data Mesh principles within a Data Fabric architecture, thereby utilizing decentralized ownership while keeping the advantages of an automated centralized core leveraging the Data Vault approach.
Best Practices for Data Mesh Implementation
- Centralized Staging and Raw Vault: This promotes high-level automation.
- Decentralized Business Vault and Beyond: This facilitates business knowledge integration and efficient use of cross-functional teams.
For optimal implementation, a centralized staging and Raw Vault approach promotes high-level automation and ensures that all data products refer to a single source of facts. In contrast, a decentralized Business Vault and beyond strategy allows for necessary business knowledge integration, clear data product ownership, and efficient scaling. This level of decentralization is crucial for a successful Data Mesh implementation leveraging cross-functional domain teams.
Recommended Architectural Synthesis
The recommended architecture integrates Data Fabric with Data Mesh and Data Vault, capitalizing on the strengths of each approach. This synthesis yields a metadata-driven, flexible, automated, transparent, efficient, and governed data environment.
Use Cases and Applications
This modern data architecture supports a broad spectrum of use cases, including:
- Efficient & Trusted Reporting and Analytics
- Regulation Compliance through an auditable core
- Various AI Applications
Conclusion
The integration of Data Fabric, Data Vault, and Data Mesh enables organizations to construct a modern data architecture characterized by flexibility, scalability, and efficiency. This holistic approach enhances data management, improves data access, and accelerates the delivery of data products, ultimately driving superior business outcomes with a high level of automation, governance and transparency.
– Marc Winkelmann & Christof Wenzeritt(Scalefree)