Enterprise Data Warehouses with Data Vault 2.0
While Enterprise Data Warehouses (EDWs) are traditionally used for reporting and dashboarding, with Data Vault, their true potential lies far beyond these basic applications. Data Vault 2.0 introduces unparalleled flexibility and scalability, enabling organizations to unlock new use cases such as data cleansing, operational process automation, and predictive analytics. This article explores how Data Vault 2.0 empowers businesses to apply centralized data cleansing rules, enhance data quality at its source, and embrace Total Quality Management (TQM). By leveraging the full capabilities of their EDWs, organizations can move beyond simple analytics to create sustainable, agile, and impactful data strategies.
Going beyond standard reporting with Data Vault 2.0
Reporting and dashboarding have become the standards in business when it comes to identifying KPIs and other measurements. As such, Enterprise Data Warehouses have emerged to support the reporting process. Though, due to the large quantity and variety of data, a demand has developed for a method of utilizing this existing data in a manner in which it can add additional business value towards a company’s needs. Data Vault 2.0 offers a wide range of methods to provide decision support beyond standard reporting as well as critical information regarding the future. To see for yourself, join us as we present different approaches and solutions as to fully leverage the potential of your data.
Flexibility and Scalability
To put it simply, an Enterprise Data Warehouse (EDW) collects data from your company’s internal as well as external data sources, to be used for simple reporting and dashboarding purposes. Often, some analytical transformations are applied to that data as to create the reports and dashboards in a way that is both more useful and valuable. That said, there exist additional valuable use cases which are often missed by organizations when building a data warehouse. The truth being, EDWs can access untapped potential beyond simply reporting statistics of the past. To enable these opportunities, Data Vault brings a high grade of flexibility and scalability to make this possible in an agile manner.
Data Vault Use Cases
To begin, the data warehouse is often used to collect data as well as preprocess the information for reporting and dashboarding purposes only. When only utilizing this single aspect of an EDW, users are missing opportunities to take advantage of their data by limiting the EDW to such basic use cases.
A whole variety of use cases can be realized by using the data warehouse, e.g. to optimize and automate operational processes, predict the future, push data back to operational systems as a new input or to trigger events outside the data warehouse, to simply explore but a few new opportunities available.
Data Cleansing (within an operational system)
In Data Vault, we differ between raw and business data. Thus raw data is stored within the Raw Data Vault and similarly business data within the Business Vault. Though, within Data Vault 2.0, the Raw Data Vault is used to store the good, bad, and ugly data as it is delivered from the source system. On the other side, the Business Vault can create any truth, for example calculating a KPI such as profit, according to a business rule defined by the information subscriber.
For reporting and dashboarding purposes, data cleansing rules are typically applied to make the data more useful for the task and therefore, in turn, process the raw data into useful information. Though, these business rules for data cleansing can also be used to write the cleansed data back into the operational system. In the best-case scenario, the business rules are applied by using virtualized tables and views within the Business Vault. This cleansed data then can be pushed back into the operational system to implement the concept of Total Quality Management, or TQM, where in which errors would be fixed at the root cause which is often within the source system itself.
Thus, using the EDW for data cleansing can have several advantages. In the case of data cleansing tools for example, it is not always possible to perform complex scripts. As most tools have predefined lists of countries, etc. to clean some selected attributes. Also, most tools are created for the purpose of cleansing data from one operational source system, ignoring inconsistencies between multiple operational systems.
From the Data Vault perspective, data cleansing rules are ordinary business rules. That means, they are implemented using business satellites, often with the help of reference tables. The following figure shows an example for data cleansing using a Data Vault 2.0 architecture, as it is utilized internally at Scalefree.
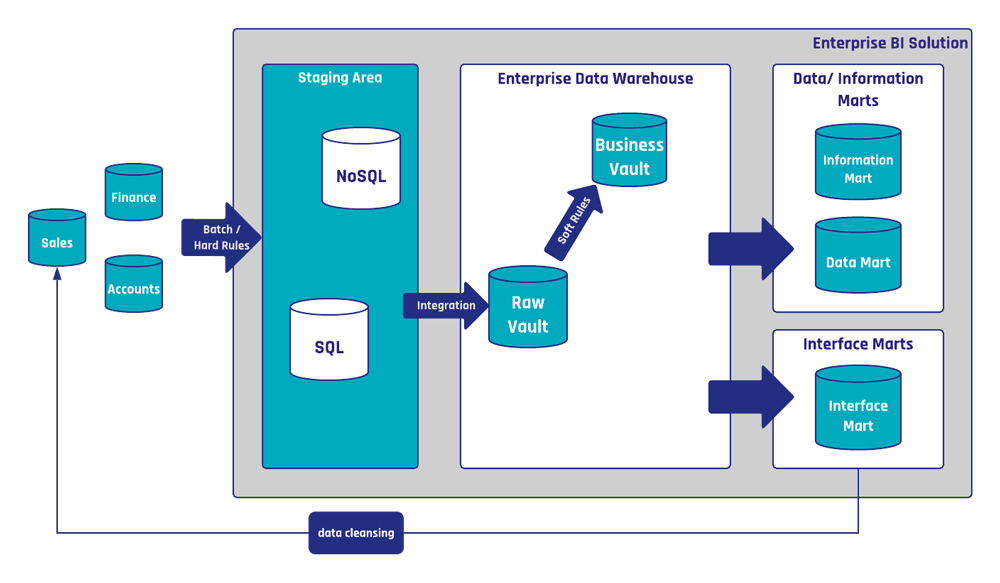
The Scalefree EDW is the central library of data cleansing rules which can be used in multiple systems such as those of the EDW and operational systems. The shown data cleansing process is used among others to cleanse customer records and standardize phone numbers as well as the accompanying addresses. Besides the Information Marts, there is also the Interface Mart ‘Sales Interface’, which implements the API of the sales source system and applies data cleansing rules from the business data vault. A scheduled interface script loads the data from the interface mart into the source systems API. In this particular case, the script is written in python.
A critical aspect of this process is the proper documentation of data cleansing rules. An internal knowledge platform is used to store the documentation of every single data cleansing rule. This way, every employee accessing the documentation understands what data cleansing rule is applicable towards the operational data. This can also have value for business users, as they can then understand as to why their data was corrected overnight.
Conclusion
With the flexibility of Data Vault, organizations can apply new capabilities, which go beyond just the standard reporting and dashboarding. Thus, the data warehouse can be used to apply data cleansing within the operational systems by following centralized cleansing rule standards.
If you would like to learn more about Data Vault Use Cases and the latest technologies from the market, a good opportunity to do such is found within the World Wide Data Vault Consortium (WWDVC). Here you will be able to interact with the most experienced experts within the field. This year, from the 9th to the 13th of September, the conference will be held in Hanover, Germany for the first time.
There, Ivan Schotsmans will talk about Information Quality in the Data Warehouse. In which, he will present how to handle current and future challenges regarding Data Warehouse architecture, how to move to an agile approach in the manner of implementing a new data warehouse, and how to increase business involvement. To not miss out on the opportunity, register today as to not miss his and other interesting presentations that will be held by Wherescape, Vaultspeed and many other vendors and speakers!

Hi,
interesting approach, thanks for the post. I have a question on where those data cleansing rules are being applied…
1) Between the source systems and staging systems –> I assume not as we want the staging area to be a loading-only to offload the source system asap. No? What are the ‘hard rules’ between the source and staging?
2) the data cleansing between the interface marts and source systems seems to be outside the vault? Does this mean you do not keep the ‘cleaned’ up data in the vault directly? (but it would automatically come in after a next load from source)
Thank you
Thank you for your comment!
Under the term “hard business rules” we classify technical rules that enforces correct data format while loading data from source systems into the staging layer. For instance, if an attribute provides information about points in time, then it should be of data type TIMESTAMP or equivalent. However source systems sometimes don’t deliver the correct type. In this case, the attribute should be remapped to the correct data type. Additionally, hard business rules can be normalization rules that handle complex data structures, e.g. to flatten nested JSON objects.
About your question regarding data cleansing: in our example, the data cleansing operation takes place both inside and outside the Data Vault. To clarify the idea behind this operation, the process starts with sourcing data from the Raw Vault, then soft rules that correct phone number and address formats would be applied onto the raw data and the results are written in Business Vault structures. The Interface Mart only selects cleansed records from the Business Vault, which haven’t yet been written back into the source operational system. And from there, an external script loads the data from the Interface Mart into the source system’s API – to update the original records with the correct, standardized format for phone numbers and addresses.
And you are correct – this external script doesn’t load the data from the Interface Mart into the Raw Vault, since the updated records in the source system should show up in the next staging operation and will be picked up into the Raw Vault then.
I hope that answers your questions.
Thank you kindly,
Trung Ta