
Non-Historized Links in Data Vault 2.0
Non-historized links in Data Vault 2.0 simplify data modeling by focusing on current relationships instead of historical changes. This improves efficiency, reduces complexity, and enhances query performance for more agile analytics.
Introduction to Non-Historized Links
Non-historized links, also known as Transaction Links, are one of the nuts and bolts of the Data Vault 2.0 framework, but how do they work within a model? When Dan Linstedt, co-founder of Scalefree, invented the Data Vault, he had several goals in mind. One of the goals was to load data as fast as possible from the source into a data warehouse model, process it into information, and present it to the business analyst in any desired target structure.
For Data Warehouse automation and simplicity, the Data Vault 2.0 model exists only of three basic entity types:
- Hubs: a distinct list of business keys
- Links: a distinct list of relationships between business keys
- Satellites: descriptive data, that describe the parent (business key or relationship) from a specific context, versioned over time.
Now, as we always teach (and sometimes preach): you can model all enterprise data using these three entity types alone. However, a model using only these entity types would have multiple disadvantages. Many complex joins, storage consumption, ingestion performance, and missed opportunities for virtualization.
The solution? Adding a little more nuts and bolts to the core entity types of the Data Vault to cope with these issues. One of the nuts and bolts is the use of non-historized links, also known as Transaction Links:

In this example, Sales can be modeled with non-historized links that capture sales transactions of a customer, related to a store. The goal of the non-historized link is to ensure high performance on the way into the data warehouse and on the way out. Don’t forget, that the ultimate goal of data warehousing is to build a data warehouse not just model it. And building a data warehouse involves much more than just the model: it requires people, processes, and technology.
Key Characteristics of Non-Historized Links
So, how do non-historized links meet these goals? Think about your business analysts. What are their goals? In the end, to be honest, they don’t care about a Data Vault model. Instead, they would like to see dimensional models, such as star schema’s and snowflake models or flat-and-wide models for data mining. Or, once in a while, they want to see the ugly-looking tables from the mainframe, sometimes linked, sometimes not, and not a lot of people fully understand the relationships anymore…but for backward compatibility, that’s just great.
Having defined the target, the next question comes into mind: what is the target granularity? For example, in a dimensional model, the target granularity of fact tables often reflects the transactions to be analyzed (think about call records in the telecommunications industry or banking transactions).
Interestingly, this desired target granularity can often be found directly in the source systems. Because a telecommunications provider has an operational system in place that records each phone call. Or a banking application that records every account transaction. These records are typically loaded to the data warehouse without aggregation (at least in Data Vault where we are interested in the finest granularity for auditing and delivery purposes).
And here comes the problem with the standard Data Vault entity types. While they are very simple and patternized, they have one problem. It’s the fact that the standard link “stores a distinct list of relationships”, as stated above. That means the link is only interested in relationships from the source that are unknown to the target link. If a customer walks into a store multiple times and purchases the same product, the relationship between the customer (number), store (number), and product (number) is already known and no additional link entry is added.
As a result, the granularity of the incoming data is changed when loading the target link. If the transaction’s underlying relationship is already known, the transaction would be omitted (and instead captured by a satellite).
The next problem is that the link granularity now differs from the target granularity because the business analyst wanted one record per transaction and not per distinct business key relationship. Another grain shift is required that typically involves joining the satellite of the link to the link itself to recover the original grain.
As we explained in our book “Building a Scalable Data Warehouse with Data Vault 2.0” a grain shift is relatively costly in terms of performance. This is because the operation requires costly GROUP BY statements or LEFT and RIGHT JOINS.
And for what? The end result of both operations often results in the original granularity from the source system. Two expensive grain shifts for nothing sounds like a bad deal.

And it is.
That is where non-historized links come into play: the link is a simple variation of the standard link with the goal of capturing the source transactions and events at the original granularity.
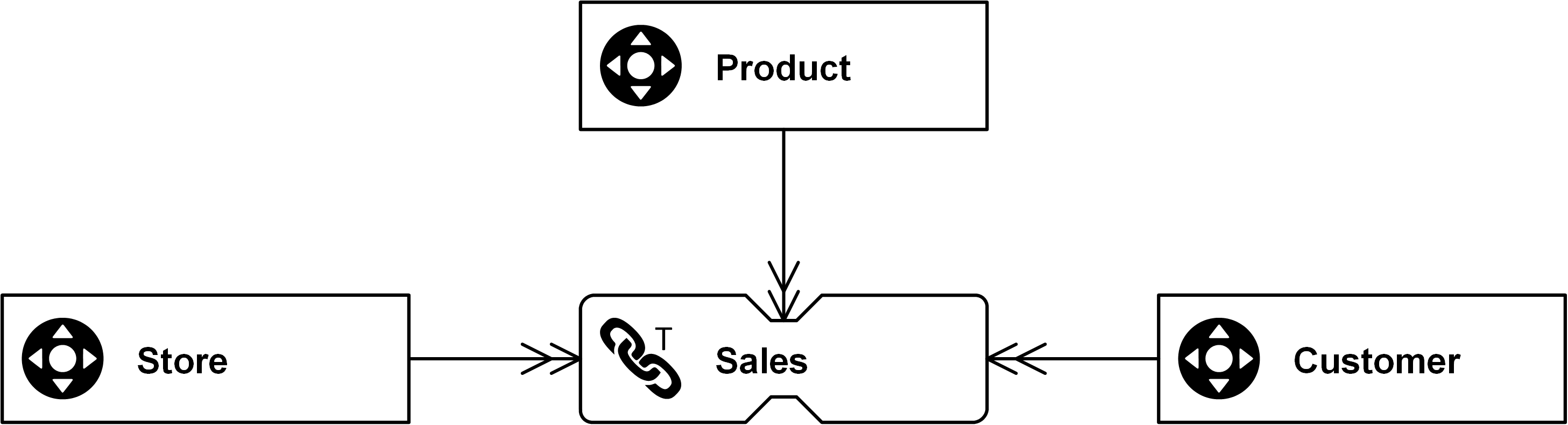

Figure: Non-Historized Link with Sales ID as an additional key
One deeper scenario would be, if the same product (in that case the highest granularity) emerges twice in a sale, because of different discounts for example. In that case, the line item number would be an additional key (Dependent Child Key) to make every data set unique.
For performance reasons, avoid grain shifts on the way out. If a different target granularity is required, and it is not possible to load this granularity from the source system or from the Data Vault model, consider a bridge table. The purpose of this entity type is to materialize the grain shift while keeping the advantage of customizing the target according to the individual requirements set for the dimensional target.
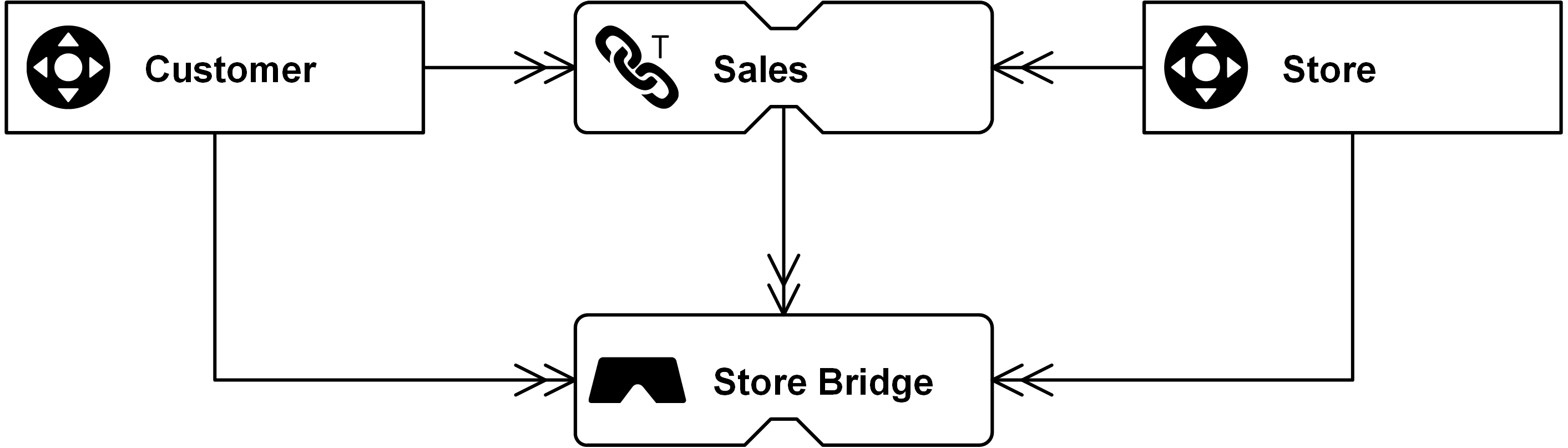
Figure: Virtual Bridge Table as Fact Table with GROUP BY Store Hash Key
Conclusion
Non-historized links offer a streamlined approach to Data Vault modeling, optimizing performance and simplifying data structures. By focusing on current relationships rather than historical changes, they enhance efficiency, reduce storage needs, and improve query speed. Incorporating them into your data architecture can lead to a more agile and scalable analytics environment.
What should I do if there is no useful additional key like the sales_id in the example.
The source only provides the load timestamp?
Hello Oliver,
with the assumption that the transaction itself is not related to a business process (like a sale), but comes in real-time from a machine, sensor or similar, you can use a sequence in the NH-Link.
Best regards,
Your Scalefree Team
As there are no satellites for NH-Link and descriptive data is part of it, what if any attributes need to be added or removed as per source data changes ? Will it not impact/compromise the flexibility ?
Hi Siva,
in order to add descriptive data to a non-historized link, you have two options:
1. Have the descriptive attributes denormalized to the link entity
2. Have a “non-historized satellite” (PK = HK of parent, no LDTS) attached to the link with a 1:1 relationship
If your descriptive data changes, turn it into a standard satellite. If the attributes in the link change over time, use counter-transactions.
Hope that clarifies it a bit. We discuss these topics in training in much more detail (hope to see you there 😉 )
Cheers,
Mike
a non-historized link supports the use of “non-historized satellites” bes
If a source system holds counter-transactions with a reference back to the original transaction being reversed and we load both original and counter transactions into a non-historized link; what would be the preferred approach to preserving that reference between the original and counter transactions received from the source system?
The only options I can think of are:
1) Is this one of the rare cases for using a Link against another Link, with, say, a dedicated ‘Reversal’ Link joining together the two non-historized link records for original and counter transactions – should not slow down the loading of the actual transactions into the non-historized link if it is just loaded where it occurs in an independent process, but does introduce additional change dependencies on the non-historized link, albeit pretty focused as the additional link only joins to the same non-historized link twice.
2) Document the id of the original transaction in a non-historized satellite against the non-historized link record for the counter transaction – feels like a bit of a cop-out as there is a genuine relationship between the two non-historized transactions, it is not really just descriptive information and would make any attempt to navigate between the original and counter transactions by consumption processes very inefficient.
Hi Richard,
the recommendation here is to use one Non-Historized Link for both transactions, and the audit trail is kept in a Same-As-Link. When your source system delivers counter transactions with relation to the original one, this is the best-case scenario you can have to make the loading as easy as possible while having an audit trail in place. The assumption here is that each transaction has a consistent singular ID (e.g. transaction ID) in addition to the original reference. Use this attribute as the “dependent child key” (part of the Link Hash Key but no own Hub) and load the counter transaction into the same Non-Historized Link as they come from the source. The assumption here is that the values are multiplied with (-1) by source system, or any other recognition that this is a counter transaction. Additionally, load both, the Link Hash Key from the original record and the Link Hash Key from the counter record into a Same-as-Link to keep the audit trail with the effective date.
Kind regards,
Your Scalefree Team
The SAL should refer to the transaction ID in this example to avoid link-to-link models.
I have case where there is no unique key in source data. Certain batch corrections create multiple identical rows that are counter actions for rows that were not identical to begin with. To oversimplify a bit there could be salary paid on April and March and then at May salary correction that create 2 rows saying like: “person A got paid incorrect amount X” and another 2 rows saying like: “person A should have been paid amount X”. The problem is, that the stamp goes on basis on the time of the correction, not the time of the corrected event, which makes these rows as two pair of rows that each are identical to every column data has within pair, including milliseconds of the stamp. So the case differs from customer – product – purchase example and the first question in that sense that there is no distinction of time between the legal multiples. As said, this is oversimplification. Actual data has in worst cases tens of identical rows that need to be considered as different instances of data.
My question is. Is there any salvation in situation like this provided that no changes are done at the source system?
Hi Jarmo,
You need to identify that a record is a “counter” to an original record (there is no way around). When you have this information you can add the counter records into the Non-Historized Link. You have to add/change 2 things: 1. Add a counter column with the value “1” for original records and a “-1” for counter records. 2. The counter value (1 or -1) as well as the load date timestamp needs to be added to the Link Hash Key calculation (alternative is to add only the counter column and make the load date timestamp as additional PK). Here you can see another blog post where we handle this situation: https://www.scalefree.com/scalefree-newsletter/delete-and-change-handling-approaches-in-data-vault-without-a-trial/
Hope this helps.
Marc
I have a case where the transactions (roster entries) can go through corrections over time. You suggest in such a case to convert the link into a standard satellite to capture history. I wonder though if you mean actually a link-sat instead of a hub-satellite, I can’t see the point of a hub-sat when the roster entries have as a composite key other hub entries. Thanks in advance.
Hi Edwina,
Depends on what the data is describing. If it’s the relationship of all related Hubs, then it’s a Link-Satellite, if you created a Hub (i.e. roster_hub) where the data fits to, then a Hub-Satellite makes more sense. This is also discussed in our Boot Camp btw. 😉
Kind regards,
Marc
NHL use cases are mostly to deal with transactions as a whole. If business needs to analyze transactions as a whole after some data transformation business rules, the option suggested is having a Satellite. Since transactions as a whole cannot be under a single hub, they will belong under a link in most cases. Since these are business vault satellites, they do need to allow for business rule changes and hence mutable. This is fairly straight forward as long as transactions can be uniquely identified with a combination of hubs that will make the normalized link.
If the transactions cannot be identified with a combination of hubs (even degenerate keys combined) and whole set of columns of NHL is needed to identify uniquely, the business vault link will end up being the NHL itself. In which case, this Business vault NHL will have to be updateable to allow for business rule changes .
Hello!
I have a use case, where I don’t have a descriptive attributes for the link but I want to track a history of relationship of that link.
Should I use Satellite without descriptive attributes, which tracks only inserts and deletes?
Hi Daniil,
You should use an Effectivity Satellite for this, tracking which relationship is/was valid at which point in time (based on the ldts). I think this is what you need: https://www.scalefree.com/scalefree-newsletter/handling-validation-of-relationships-in-data-vault-2-0/. Hope this helps.
-Marc
Hi all,
I’m facing with the below use case where I want to use DataVault as design methodology:
I have a message broker source (Solace) system that send messages via broker into PPMP protocol (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
I have stored the incoming data into a staging area having roughly the following structure:
message_id——–queue———–message (storing the message in json )—–load_date——–source_system———some_audit_cols
1 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619010000 SRC1 audit vals
2 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619010000 SRC1 audit vals
1 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619020000 SRC1 audit vals
The business wants to have a start schema in information marts some similar with the model from PPMP protocol (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
It is a good approach to design this data messages in raw vault using only non-historized link? The link will have: lnk_hk , hub_device_hk, hub_part_hk, message_id, message etc.
Namely, all data will be stored in this link including the descriptive fields too (message, queue, etc). No required any link satellites due there is not history for incoming messages.
The identified hubs are: hub_device, hub_part (having their own satellites)
Afterward, I should also create some business vault entities that can help other information marts to calculate easy and quickly the KPIs.
I’m looking forward your feedback.
Regards,
Laurentiu
Hi Laurentiu,
all of the above sounds good 🙂
-Marc
I have a case where source system is sending 2 datasets. First dataset contains the Key and its attribute. Second dataset contains different transactions for a particular key. Second data set may or may not contain key. For e.g. first dataset contains account no and second dataset contains txns associated with a particular account no. Now, there can be a scenario where the second dataset may not contain an account no because no txn has occurred. Lastly, the existing txns can also be updated from source. Second dataset also has bunch of attributes along with txn id. Now, i have created a hub (hub account) but, facing challenge how to model the second dataset.
– As per my understanding the second dataset cannot be a direct sat attached to hub as the grain will differ
– Another approach I am thinking of having a transaction link (with Account number and txn id ) and then a txn link sat (but this sat will act as a normal sat to the link because a particualar txn can be updated later on. So, the sat will have multiple records for a txn but only one will be active or latest)
Can you please let me know if this approach is ok to follow or is there any better approach? Thanks in advance
Hi Kapil,
Different grain means different Hub, or in your case, a different Non-Historized Link including the transaction number as additional Key. Your second approach sounds valid. Another one could be to model transaction as an own Hub and hang the standard Satellite on it.
Hope this helps.