Data Vault 2.0 on Microsoft Azure
In this newsletter, you’re going to get an overview of what real-time processing is and what possibilities it can provide your Data Vault 2.0 implementation.
Real-Time Processing with Data Vault 2.0 on Azure
In this webinar, we’ll discuss the new data warehouse requirements for data and explore
Real-Time processing. We’ll cover various Real-Time processing architectures for an initial overview. The second part focuses on Real-Time data architecture with Data Vault 2.0 and includes a brief overview of Microsoft Azure. You’ll also see a Real-Time processing implementation of Data Vault 2.0 in Azure. This webinar is for anyone new to Real-Time Data with Data Vault 2.0 and interested in an overview and implementation in Azure.
What to expect
You will learn that real-time processing gives you the ability to create value out of data quicker, have the most up-to-date data in your reporting tools and allow more accurate decisions regarding data.
With that, your company will be able to adapt to changes in the market quicker by seeing developments right away with the most recent data.
Additionally, you can save costs by moving away from batch loading because the peak of computing power normally required for that gets reduced and is more evenly distributed throughout the day. That is especially the case when using cloud environments, because then it’s possible to replace promised environments and contribute the needed computing power perfectly.
The traditional way – batch-loading
Batch loading is a traditional method used to load data into a data warehouse system in large batches, mostly overnight. The data from data sources is delivered up to a certain time in the night to be transformed and loaded into the core data warehouse layer.
This method leads to a peak of data processing overnight, and organizations have to adjust their infrastructure needs to be able to deal with the expected maximum peak of required computing power.
The new way – real-time data
Real-time data is processed and made available immediately as it is generated, instead of being loaded in batches overnight. When using real-time approaches, the loading window is extended to 24 hours. So the overnight peak and its disadvantages are gone.
When using real-time data, it’s always modeled as a non-historized link or as a satellite.
Possible use cases for real-time data are vital monitoring in the healthcare industry, inventory tracking, user behavior on social media or production line monitoring.
Different types of real-time data
There are different types of real-time data based on how frequently the data is loaded and the degree of urgency or immediacy of the data.
Near real-time data refers to data that is loaded in mini-batches at least every fifteen minutes, with the data stored in a cache until it is loaded into the data analytics platform.
Actual real-time data, also called message streaming, involves loading every single message directly into the data analytics platform without any cache.
This type of real-time data is useful when it is important to have data available as soon as it is generated for dashboards or further analytics.
The acceptable processing delay for real-time data is typically defined by the consequences of missing a deadline. Additionally, there are three types of real-time systems: hard real-time, soft real-time, and firm real-time.

Implementing real-time processing
So, how do you implement real-time data processing into your data warehouse solution? There are many architectures for that, but we will focus on the Lambda and Data Vault 2.0 architecture.
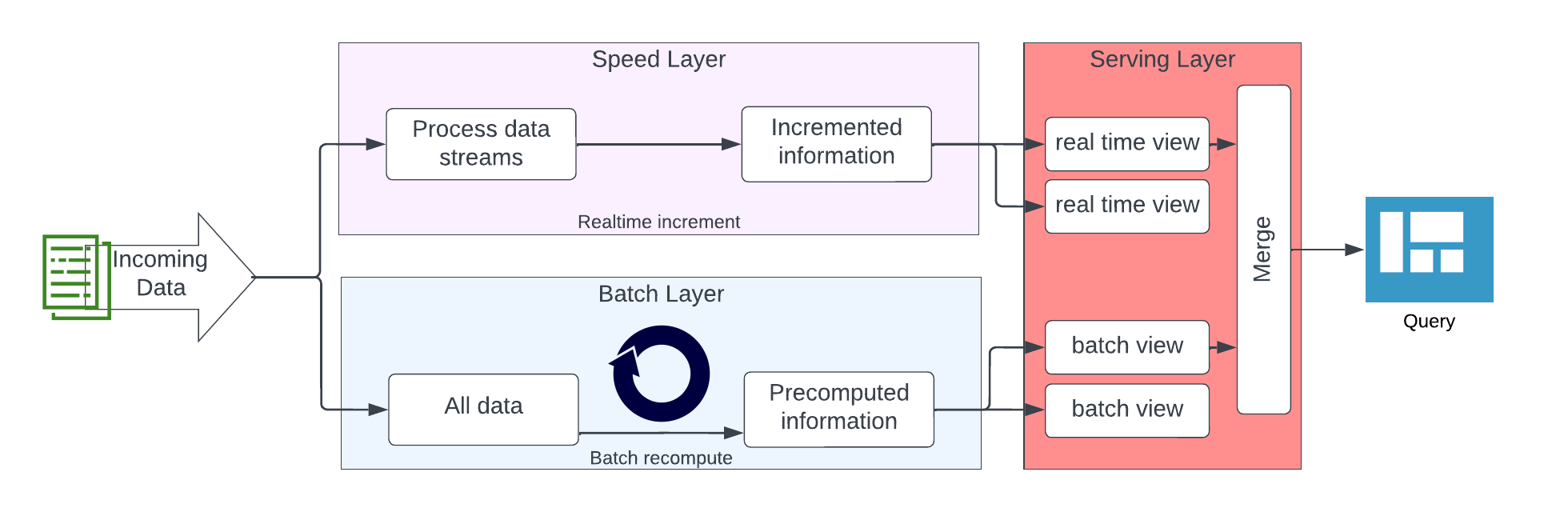
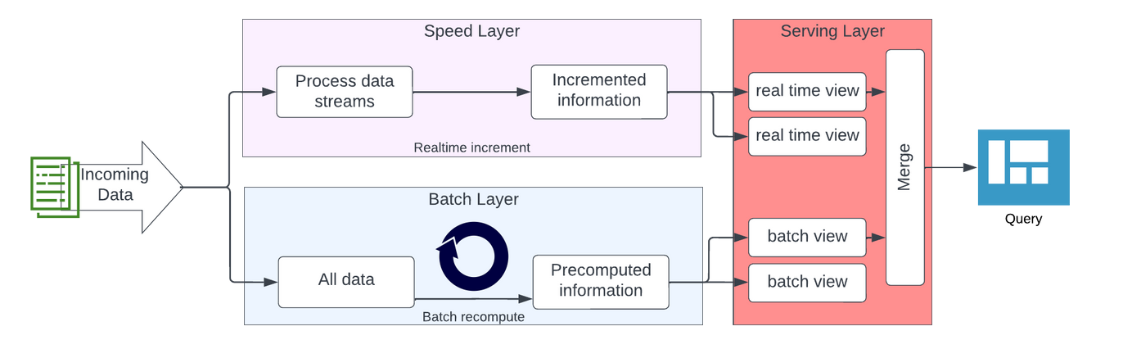
The lambda architecture separates data processing into a speed layer and a batch layer. The speed layer processes real-time messages with a focus on speed and throughput, while the batch layer provides accuracy and completeness by processing high volumes of data in regular batches. The serving layer integrates data from both layers for presentation purposes.
At first, the Data Vault 2.0 architecture seems to be similar to the lambda architecture, but it treats some aspects differently. The lambda architecture has issues from a Data Vault 2.0 perspective, such as implementing a single layer in each data flow and lacking a defined layer for capturing raw, unmodified data for auditing purposes.
The Data Vault 2.0 architecture adds a real-time part called “message streaming” to the existing batch-driven architecture, with multiple layers implemented for capturing and processing real-time data, integrating it with the batch-driven flow at multiple points. Messages are pushed downstream from the publisher to the subscriber, loaded into the Raw Data Vault and forked off into the data lake. But the main process is the push inside the message streaming area. The architecture is able to integrate data from batch feeds or to stream the real-time data directly into the dashboard.
Using Microsoft Azure for real-time processing
Microsoft Azure is a cloud computing platform and set of services offered by Microsoft. It provides a variety of services, including virtual machines, databases, analytics, storage, and networking. These services can be used to create web and mobile applications, run large-scale data processing tasks, store and manage data, host websites and much more.
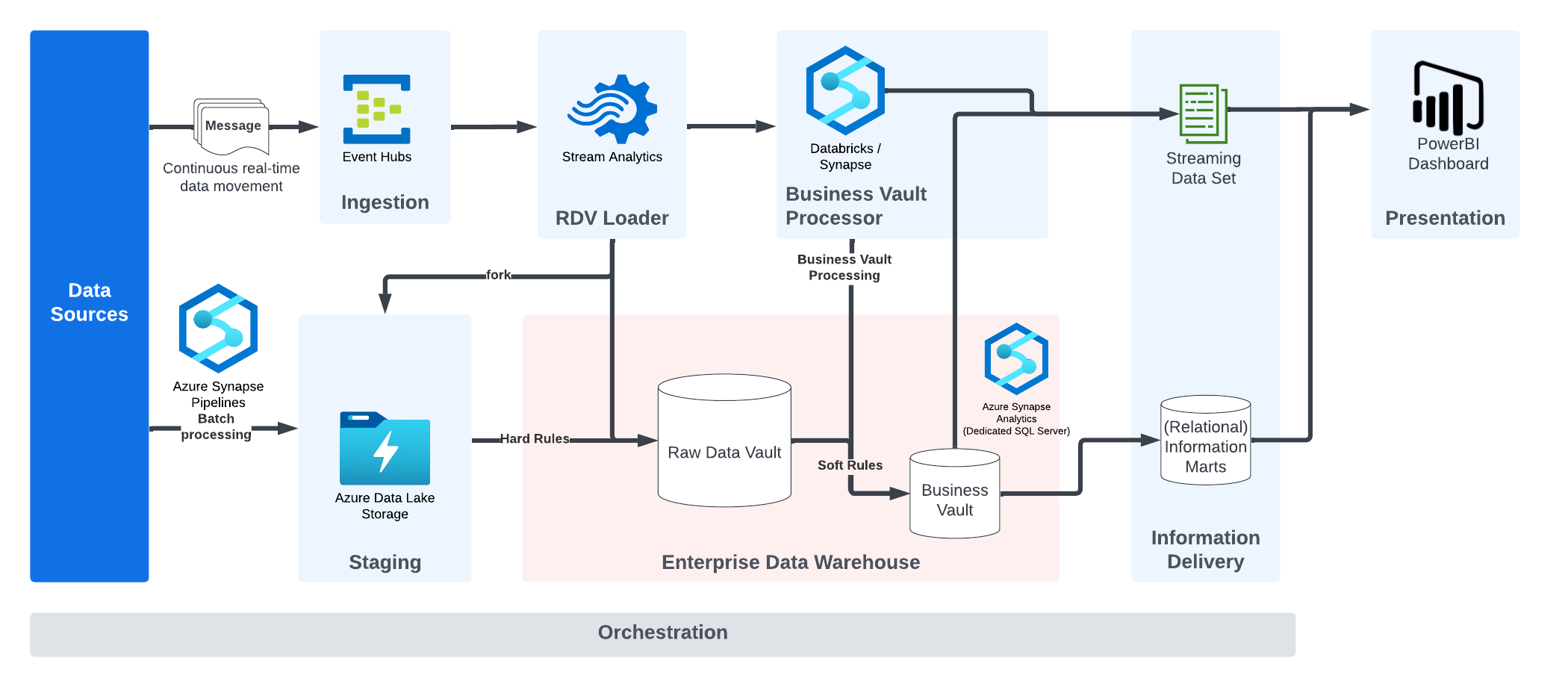
The illustration describes a typical real-time architecture used by Scalefree consultants, which follows the conceptual Data Vault 2.0 architecture.
Data sources deliver data either in batches or real-time. This is loaded into the Azure Data Lake or accepted by the Event Hub beforehand. The Raw Data Vault Loader separates business keys, relationships and descriptive data using Stream Analytics and forwards the message to the Business Vault processor. The Business Vault processor applies transformation and other business rules to produce the target message structure for consumption by the (dashboarding) application. The results can be loaded into physical tables in the Business Vault on Synapse or be delivered in real-time without further materialization in the database. The target message is generated and sent to the real-time information mart layer implemented by a streaming dataset, which is consumed by PowerBI. The cache of the dashboard service will expire quickly, but the Synapse database has all data available for other uses, including strategic, long-term reporting.
Conclusion
In conclusion, real-time data processing offers numerous benefits over traditional batch loading methods, including the ability to create value out of data quicker, have the most up-to-date information in reporting tools, and make more accurate decisions. By adapting to changes in the market quicker, companies can stay ahead of the competition. Moving away from batch loading can also save costs by reducing the peak of computing power required.
As mentioned before, the last illustration shows an architecture that the Scalefree Consultants implemented to make use of real-time data.
Read more on our recently released Microsoft Blog Article.
How is your current experience with real-time data processing?
Are you thinking about kick-starting your Data Vault by also using real-time data?
Or are you already using it and thinking about improving it further?
Let us know your thoughts in the comment section!
– Deniz Polat (Scalefree)
