
Point-in-Time Tabellen erfüllen zwei Zwecke:
Point-in-Time Tabellen sind hilfreich, wenn im Raw Vault Daten aus Hubs oder Links mit mehreren Satelliten abgefragt werden sollen:
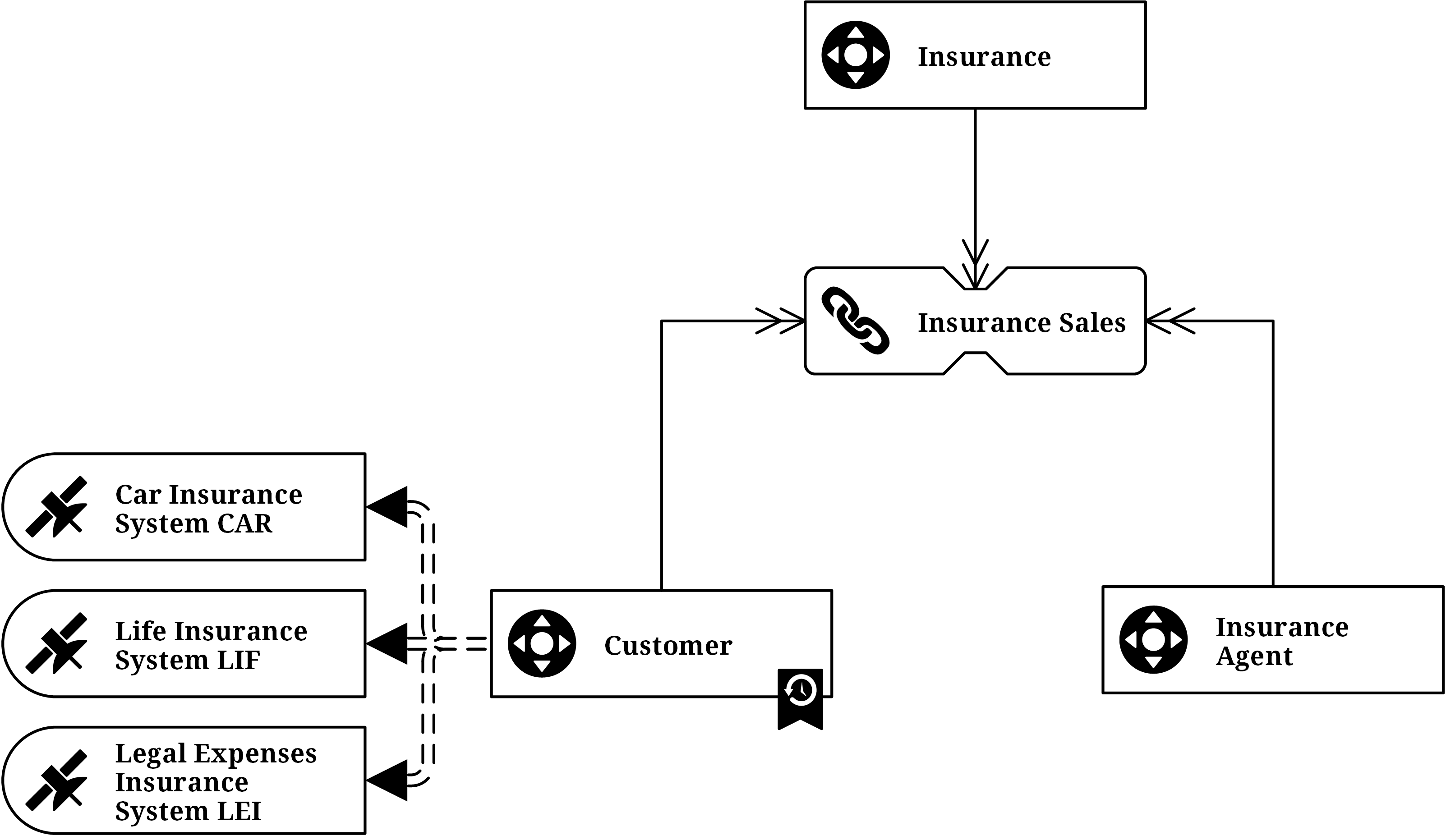
Über Point-In-Time Tabellen
Im obigen Beispiel sind mehrere Satelliten an den Hub Customer und den dargestellten Link angebunden. Das ist eine sehr typische Situation in Data-Warehouse-Lösungen, da sie Daten aus verschiedenen Quellsystemen integrieren. Allerdings erhöht genau diese Situation die Komplexität bei Abfragen aus dem Raw Data Vault. Der Grund: Änderungen an den Geschäftsobjekten in den Quellsystemen erfolgen nicht gleichzeitig. Ein Geschäftsobjekt – zum Beispiel ein Kunde (eine versicherte Person) – wird zu einem bestimmten Zeitpunkt in einem System aktualisiert, später in einem anderen, und so weiter. Hinweis: Die Point-in-Time Tabelle (PIT) ist im Diagramm bereits mit dem Hub verbunden, erkennbar am dargestellten Symbol.
Die Änderungen erfolgten zu unterschiedlichen Zeitpunkten und standen nicht in direktem Zusammenhang. Die meisten Aktualisierungen wurden nach Abschluss der Versicherung vorgenommen, betrafen jedoch nicht alle operativen Systeme gleichzeitig. In der Folge wirkten sich diese Änderungen auch nicht auf alle Satelliten aus, sondern nur den Satelliten, der für die jeweilige Änderung zuständig war (was ein Vorteil ist).
Beim Aufbau eines Data Marts aus diesen Rohdaten wird die Abfrage von Kundendaten zu einem bestimmten Stichtag schnell komplex: Die Abfrage soll den Kundenstand so zurückgeben, wie er laut Delta-Verarbeitung des Data Warehouses am gewählten Datum gültig war. Dafür sind Outer Joins mit aufwendiger Zeitbereichslogik notwendig. Sobald mehr als drei Satelliten an einem Hub oder Link hängen, wird das Ganze nicht nur kompliziert, sondern auch langsam. Ein besserer Ansatz ist die Nutzung von Equal Joins zur Abfrage der Daten im Raw Data Vault. Um das zu ermöglichen, kommt in der Data Vault 2.0 Modellierung ein spezieller Entitätstyp zum Einsatz: die Point-in-Time Tabelle (PIT). Diese wird dann ins Modell aufgenommen, wenn die Abfrageperformance für einen bestimmten Hub oder Link mit den zugehörigen Satelliten zu gering ist.

Da die Daten in einer PIT Tabelle vom System berechnet werden und nicht aus einem Quellsystem stammen, unterliegen sie keiner Auditpflicht und gehören nicht zum Raw Vault. Daher kann die Struktur angepasst werden, um berechnete Spalten zu enthalten.
Point-in-Time Tabellen erfüllen zwei Zwecke:
Erleichtert die Kombination mehrerer Deltas zu verschiedenen "Point-in-Times" (Zeitpunkten)
Eine Point-in-Time Tabelle erstellt Snapshots von Daten auf Basis der Zeitpunkte, die von den vorgelagerten Datenkonsumenten vorgegeben werden. So ist es beispielsweise üblich, täglich den aktuellen Stand der Daten zu berichten. Um diese Anforderungen zu erfüllen, enthält die PIT-Tabelle das Datum und die Uhrzeit des Snapshots – kombiniert mit dem Business Key – als eindeutigen Schlüssel der Entität (ein Hash Key der beide Attribute enthält, in Abbildung 2 als CustomerKey bezeichnet). Für jede dieser Kombinationen speichert die PIT-Tabelle die Load Dates sowie die zugehörigen Hash Keys der Satelliten, die am besten mit dem Snapshot-Datum übereinstimmen.
Reduzierung der Join-Komplexität zur Performance-Optimierung mit Point-in-Time Tabellen
Die Point-in-Time Tabelle funktioniert wie ein Index, der von der Abfrage genutzt wird und Informationen über die jeweils aktiven Satelliteneinträge zum Snapshot-Datum liefert. Ziel ist es, möglichst viel der Join-Logik vorab zu materialisieren – sodass am Ende ein Inner Join mit reinen Equi-Join-Bedingungen entsteht. Diese Join-Variante ist auf den meisten (wenn nicht allen) relationalen Datenbankservern die performanteste. Um die Performance der PIT-Tabelle zu maximieren und gleichzeitig den Speicherbedarf gering zu halten, wird pro genutztem Satellite genau ein Ghost Record benötigt. Dieser Ghost Record wird verwendet, wenn zum jeweiligen Zeitpunkt kein aktiver Eintrag im referenzierten Satellite vorhanden ist, und steht für den unknown oder NULL-Fall. Durch den Einsatz des Ghost Records lassen sich allgemeine NULL-Prüfungen vermeiden, da die Join-Bedingung stets auf einen vorhandenen Eintrag in der Satellitentabelle verweist – entweder auf einen tatsächlich aktiven Datensatz zum Snapshot-Datum oder auf den Ghost Record.

Wenn Kundendaten nur für ein bestimmtes Geschäftssegment gelöscht werden müssen und dabei PII-Informationen als Business Key verwendet werden, reicht es aus, den entsprechenden Link-Eintrag sowie die beschreibenden Attribute im zugehörigen Satellite zu löschen. Die Aktivitätshistorie bleibt dabei erhalten, kann weiterhin für analytische Zwecke genutzt werden und ist nicht mehr auf den ursprünglichen Kunden zurückzuführen. Ein zusätzlicher Vorteil dieser „Business-Trennung“ ist, dass im Falle einer Löschung nur das betroffene Geschäft betroffen ist – zum Beispiel, wenn verschiedene Geschäftsbereiche von unterschiedlichen Tochtergesellschaften betrieben werden und lediglich die Daten zur Kfz-Versicherung entfernt werden müssen. Wichtig: Allein das Löschen des Business Keys (und das Beibehalten des Hash Keys) genügt nicht für eine
Wenn Kundendaten nur für ein bestimmtes Geschäftssegment gelöscht werden müssen und dabei personenbezogene Daten (PII) als Business Key verwendet werden, reicht es aus, den entsprechenden Link-Eintrag sowie die beschreibenden Attribute im zugehörigen Satellite zu löschen. Die Aktivitätshistorie bleibt dabei erhalten, kann weiterhin für analytische Zwecke genutzt werden und ist nicht mehr auf den ursprünglichen Kunden zurückzuführen. Ein zusätzlicher Vorteil dieser „Business-Trennung“ besteht darin, dass bei einer Löschung nur das betroffene Geschäft beeinträchtigt wird – etwa wenn die Geschäftsbereiche von unterschiedlichen Tochtergesellschaften stammen und lediglich die Daten zur Kfz-Versicherung entfernt werden müssen. Wichtig: Allein das Löschen des Business Keys (bei gleichzeitigem Beibehalten des Hash Keys) erfüllt nicht die Anforderungen der DSGVO und entspricht zudem nicht dem Data Vault 2.0, -Standard, da der Business Key in Link-Tabellen verwendet wird. Der Hash Key im Data Vault 2.0 dient nicht der Verschlüsselung, sondern ausschließlich Performance-Zwecken. Der Schlüssel in Links und geschäftsorientierten Hubs – wie in diesem Fall – ist ein vollständiger Technischer Schlüssel (surrogate key) und lässt sich nicht zurückrechnen. Sobald ein Kunde vollständig gelöscht werden soll – also kein aktiver Kunde mehr in irgendeinem Geschäftsbereich ist – muss auch der entsprechende Eintrag im zentralen Hub entfernt werden.
Andernfalls, wenn kein zusätzlicher technischer Schlüssel für den Kunden existiert, ist nach dem Löschen der personenbezogenen Daten keine Zuordnung zu einem Objekt (Ankerpunkt) mehr möglich – was die verbleibenden Daten in vielen Fällen unbrauchbar macht.
Fazit
Point-in-Time Tabellen dienen in erster Linie dazu, die Abfrageperformance zu verbessern: Sie vermeiden Outer Joins und ermöglichen stattdessen Inner Joins mit Equi-Join-Bedingungen – was die bestmögliche Performance bietet. Darüber hinaus unterstützen Point-in-Time Tabellen die Partitionierung und ermöglichen die vollständige Skalierbarkeit von Sternschemata, die idealerweise vollständig virtualisiert auf dem Data Vault aufbauen. Ein weiterer Vorteil: Endanwender müssen nicht mehr alle Satellitentabellen verknüpfen, sondern nur noch eine einzige Tabelle pro Geschäftsobjekt – was die Komplexität bei Ad-hoc-Abfragen deutlich reduziert.
Hi @Michael,
Amazing and Important insight.
But as the systems are becoming more and more heterogeneous where DWH is on 1 environment and MART is on another, I think its time to grow the Data Vault objects too.
So PIT is essentially storing the Load Dates for each BK from all the SATs.
How about having a PIT_SAT where we have all the Attributes from SATs. This will be child table of PIT.
Advantage:
1. My Virtual Dimension (in Mart) is simply inner join from PIT and PIT_SAT.
2. If my DWH is HIVE (managed) and MART is on Teradata or Exasol or Oracle, then I only have to sync PIT and PIT_SAT (2 tables) and not all the DWH SATs.
Please let me know if this sounds good?
Angad
Hi Angad,
thanks for your comment.
Actually, as the PIT is not part of the Raw Data Vault, you can extend the table to your own advantages, what also means to either create an additional PIT (PIT_SAT) table where the descriptive attributes are part of, or hanging these attributes directly in the main PIT table. As soon as the business keys and the load dates from the satellites are in, it’s up to you to extend the PIT.
Best regards,
Marc (Solution Manager)
Hi,
Very good article! 🙂
Could you please share the idea behind having additional hash key columns in the PIT table?
For example, CustomerCAR_HashKey has the same value as the Customer_HashKey for the corresponding line.
When joining PIT with CustomerCAR_SAT, couldn’t we use PIT.Customer_HashKey = CustomerCAR_SAT.Customer_HashKey (+ join on LDTS) ?
Thank you,
Hi Slavon,
this would work from logical perspective, but for performance reasons we don’t recommend this approach (and this is why we use PIT tables). Searching Hash Keys in satellites will reduce query performance as the query would try to search a value which not exists. Additionally, an outer join has to be used what reduces the performance.
You have to add a ghost record in the satellite. This is the first entry in a satellite table where the PIT points to by using an inner join with equi condition, if the Hash Key does not exist in one of the satellites. This is the best way from performance perspective.
Best regards,
Your Scalefree Team
Hi Slavon,
the Customer HashKey is the same in the Hub/Link and its Satellites WHEN the customer exists in a Satellite.
If you put in the PIT only the Cust_HKey from the Hub/Link and the LDTS for each satellite, then when you use the results from the PIT to join on a satellite (on Cust_HKey and LDTS) you have two choices: (1) to use outer join to handle the null OR (2) to “post process” the PIT data entering the join to replace BOTH the Cust_HKey and LDTS with the ones for a ghost record whenever you get a null LDTS from the PIT.
It looks to me way simpler and more performant to put this substitution logic in one place only (when creating the PIT) where the result of the substitution is stored, instead having to add this logic in every query that will ever use the PIT and having to re-evaluate the substitution logic ad every query.
Ciao, Roberto
Hi Roberto
Yes, I agree! We actually go with the second choice here at Scalefree, and use ghost records for null values.
Cheers
Obaid