Alternative zum Driving Key
Es gibt einen Sonderfall, in dem sich ein Teil der in einem Link gespeicherten Hub-Referenzen ändern kann, ohne dass eine andere Beziehung beschrieben wird. Dies hat einen großen Einfluss auf die Link-Satelliten. Außerdem haben wir 2017 die Linkstruktur mit einem Beispiel für ein Data Vault-Modell im Bankensektor vorgestellt. Wir haben gezeigt, wie das Modell aussieht, wenn eine Verbindung entweder eine Beziehung oder eine Transaktion zwischen zwei Geschäftsobjekten darstellt. Ein Link kann auch mehr als zwei Hubs miteinander verbinden. Was ist die Alternative zur Implementierung des Driving Key in Data Vault 2.0?
In diesem Artikel:
Der Driving Key
Eine Beziehung oder Transaktion wird oft durch eine Kombination von Geschäftsschlüsseln in einem Quellsystem identifiziert. In Data Vault 2.0 wird dies als normaler Link modelliert, der mehrere Hubs verbindet, die jeweils einen Geschäftsschlüssel enthalten. Ein Link enthält auch seinen eigenen Hash Key, der über die Kombination der Geschäftsschlüssel aller Elternentitäten berechnet wird. Wenn also die Verknüpfung vier Hubs verbindet und sich ein Geschäftsschlüssel ändert, hat der neue Datensatz einen neuen Link-Hash Key. Es gibt ein Problem, wenn vier Geschäftsschlüssel die Beziehung beschreiben, aber nur drei von ihnen sie als eindeutig identifizieren. Wir können das Geschäftsobjekt nicht identifizieren, indem wir nur den Link-Hash Key verwenden. Das Problem ist kein Modellierungsfehler, sondern wir müssen bei der Abfrage der Daten den richtigen Datensatz im verbundenen Satelliten identifizieren. In Data Vault 2.0 nennt man dies den Driving Key oder den treibenden Schlüssel. Es handelt sich um einen konsistenten Schlüssel in der Beziehung und oft um den Primärschlüssel im Quellsystem.
Die folgenden Tabellen zeigen die Beziehung zwischen einem Mitarbeiter und einer Abteilung aus einem Quellsystem.

Das folgende Data Vault-Modell kann aus dieser Ausgangsstruktur abgeleitet werden.
Die Verknüpfungstabelle "Empl_Dep" wird von der Tabelle "Employee" im Quellsystem abgeleitet. Der Driving Key in diesem Beispiel ist die Mitarbeiternummer, da sie der Primärschlüssel in der Quelltabelle ist und ein Mitarbeiter nur in einer Abteilung zur gleichen Zeit arbeiten kann. Das bedeutet, dass der Driving Key im Satelliten des Mitarbeiters "lebt". Wenn die Abteilung eines Mitarbeiters wechselt, gibt es keinen zusätzlichen Datensatz in der Satellitentabelle des Mitarbeiters, sondern einen neuen in der Link-Tabelle, was legitim ist.

Um das neueste Delta abzufragen, müssen Sie es in der Link-Tabelle abfragen, gruppiert nach dem Driving Key.
Zusammenfassend lässt sich sagen, dass Sie immer einen neuen Link-Hash Key haben werden, wenn sich ein Geschäftsschlüssel in einer Beziehung ändert. Die Herausforderung besteht darin, den Driving Key zu identifizieren, der ein eindeutiger Geschäftsschlüssel (oder eine Kombination von Geschäftsschlüsseln) für die Beziehung zwischen den verbundenen Hubs ist. Manchmal muss man ein zusätzliches Attribut hinzufügen, um einen eindeutigen Identifikator zu erhalten.
Beides stellt ein Problem für Power-User mit Zugriff auf das Data Vault-Modell dar. Ohne Namenskonventionen besteht die Gefahr, dass eine Gruppierung nach mehr Attributen als nur dem Driving Key durchgeführt wird, was zu unerwarteten und falschen Gesamtwerten führen würde - auch wenn die Daten selbst korrekt modelliert sind.
Beim Umgang mit Beziehungen zwischen Daten gibt es eine bessere Lösung als den Driving Key: Wir bevorzugen in der Regel die Modellierung solcher Daten als non-historized Link und fügen den Daten technische Gegentransaktionen ein, wenn sich eine Hub-Referenz ändert.
Im Falle eines geänderten Datensatzes in der Quelle fügen wir zwei Datensätze in den non-historized Link ein: einen für die neue Version des geänderten Datensatzes in der Quelle und einen für die alte Version, die noch im Ziel existiert (non-historized Link), aber jetzt gekontert werden muss - den technischen Gegendatensatz. Zur Unterscheidung der Datensätze aus der Quelle und der Gegendatensätze wird eine neue Spalte eingefügt, die oft "Counter" oder "Zähler" genannt wird.
Der Standardwert für dieses Zählerattribut ist 1 für Datensätze aus der Quelle und -1 für die technischen Gegentransaktionen. Wichtig: Wir führen keine Update-Statements durch, sondern fügen nur die neuen Datensätze ein. Wenn Sie die Kennzahlen aus dem Link abfragen, multiplizieren Sie die Kennzahlen einfach mit dem Zählerwert.
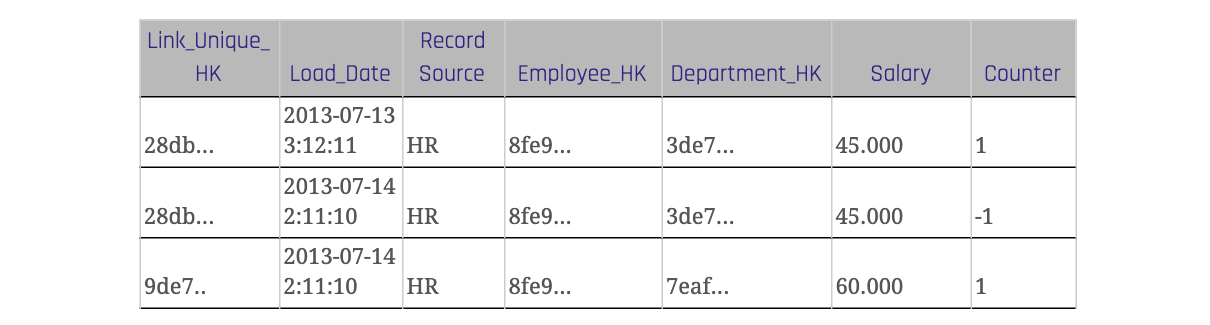
Die Tabelle 3 zeigt einen Link mit einem Zählerattribut. Wenn sich ein Datensatz im Quellsystem ändert, wird er mit dem ursprünglichen Wert und einem Zählerwert von -1 in die Link-Tabelle des Data Warehouses eingefügt. Für den geänderten Wert gibt es einen neuen Link-Hash Key, der ebenfalls über das beschreibende Attribut "Salary" berechnet wird. Der Zählerwert des neuen Satzes ist 1.
Fazit
Da die Identifizierung des Driving Keys einer Beziehung in manchen Situationen ein Problem darstellen kann, können Sie eine alternative Lösung verwenden, um den Driving Key zu vermeiden. Alle Änderungen und Löschungen werden mit Hilfe eines Zählerattributs in einem non-historized Link aufgezeichnet. Sie speichert auch die beschreibenden Attribute, und der Link-Hash Key wird über alle Attribute berechnet.
Hi all, if I understand correctly the concept of updating data in the link, there should be exactly the load dates in the second and third record of that example in Table 3. Because when a record changes in the source system, this new information is loaded and the previous one is “invalidated” at the same time. Am I right?
Hello Tomas,
first, we do not perform any “physical” updates in the link, but we create new records which are “counter records”. The precision of the load date depends on the frequency of data loads. For daily batch loads, the day as most detailed value might work. For mini-batches, you should include at least seconds. And yes, the insert of new records and the insert of the counters can run in parallel.
Best regards,
Scalefree Team
Hello scalefree team,
Could you, please, provide a real-life example, where the explained approach was beneficial?
Kind regards,
Mike
Hello Mike,
we use this approach in situations where we need full auditability while maintaining simplicity. We have successfully used this approach at Berenberg on the bank’s booking transactions. In this case, the bank was able to scroll back and forth in the history of all transactions to retrieve the current state of all bank accounts at any time. More details: Success Story Berenberg & Scalefree
Kind regards,
Your Scalefree Team
Note: The article was revised on the 14th of January 2019 to improve quality.
There is still error in the Table 3. The second (correction) record should have 2013-07-14 2:11:10 Load_Date value.
Also, I must recommend to multiply the Salary value directly by -1 to simple sum.
Hello Richard,
we want to reverse the original record, that’s why we use exactly the same values from the first one (the counter value is part of the LinkHashKey). In queries, you have to multiply with the counter attribute, yes.
Best regards,
Your Scalefree Team
Hi,
I feel like the only place you would get this from is a CDC… I don’t see how you would know to create the -1 with out knowing that the relationship changed from Dept. A to Dept. B???
If so, what happens on the change to Dept. C…
I can see being able to do this from a change trigger, where I can now create two Insert Statements into the Link… but not in a Batch Load or from a CDC change, as I wouldn’t know where I left off in the CDC…
Thanks,
Hello John,
yes, if possible, CDC audit trails are definitely the way to go. When CDC/audit trails are implemented in the source, you should go with standard link and its satellites. Our solution depends on full data delivery. The intention is to create a complete counter record of the original record for every change.
We use two different patterns for the whole process. The first is an insert statement which inserts new or changed records (identified by the Link_Unique_HK).
The second pattern inserts the counter booking when records in the link don’t exist in the transient staging area (or latest batch load in a persistent staging area). Both processes can run in parallel.
Best regards,
Your Scalefree Team
Hi,
Based on table 3, how would one retrieve the stuation as on 2013-07-04 02:00:00 ?
Don’t you require the Load_Date of the change as well to do this?
Regards,
Tjomme
Hello Tjomme,
the Load_Date and the Record Source are not part of the unique hash key. Recognition is done via full table scan into the staging area (where you have the full data load from the source system) by comparing the unique hash key. The Load_Date in this case is not the load date for the counter record as it never truly exists. The counter record is the original first record and inserted again at the same time/in the same batch when the load for new records happen, just with the counter -1. On 2013-07-04 02:00:00, the counter record does not exist yet. It will be inserted when the third records is inserted.
Remember, that this method should be used if you don’t receive CDC data, but full data delivery only.
Kind regards,
Your Scalefree Team
Hi Karina,
A purpose of the Data Vault is auditability. This means that today we should be able to reproduce the status of the source system as it was on 2013-07-14 02:00:00.
When only working with the table 3 above, this will be a challenge. Or am I missing something?
This will become a lot easier when the Load_Date of the record causing the counter record to be created is captured on the counter record as well. In this case that would be 2013-07-14 02:11:10. By filtering on this field, we would be able to set the table to any point in time easily.
Or is this information maintained in a (not mentioned) status satellite?
The same technique could be used when processing CDC logs as well.
Regards,
Tjomme
Hi Tjomme,
yes, you’re right.
You can only reproduce the original data delivery when you set the load date for the counter record to the date from the current data load where you actually recognize it is missing. We changed that accordingly.
Thanks for your eagle eye and best regards,
Your Scalefree Team
I have 2 questions:
1) I assume Link_Unique_HK in given example has to be calculated based on Employee BK, Department BK, Counter and Load_date. It has to be unique, and the employee may enter same department multiple times, right?
2) If we can mix relationship and contextual data in transactional link, could we also mix relationship and contextual data in sattelite? For given example the table structure would be the same, just the table would represent sattelite of employee hub. So primary key would be employee_hk and load_date. We could also calculate Link_unique_hk just based on Employee_hk and department_hk like in standard empl_dep link. I believe we could even create view for virtualizing that link on top of such satellite, so there will be physical representation of empl_dep link in database. We would need just one new row per change. Regarding loading full dumps as well as CDC can be leveraged. Power users and ETL for datamarts would retrieve current records like from standard satellite and few joins may be left. Can you point out any pitfalls you can see regarding this approach?
Hello Karel,
1) Correct.
2) Your approach is similar to that, which involves Driving Keys. However, in this case, you’ll NEED a Link to set Business Keys in relation, what is also part of the standards of Data Vault 2.0 for several reasons – but this is another topic. Keep in mind, that the approach you suggest would work for a one-to-many relationship, but not for a many-to-many relationship as you would need to activate multiple LDTS per Hash Key.
The situational issue here is, when the business key in a relationship has changed and you don’t have an audit trail, which informs you about that. The result would be a new Link entry with a new Link Hash Key (which is ok) and another Satellite entry (which is ok as well), however you’ll have to soft delete the “old” entries (or however you mark disappearing data in your Data Warehouse).
This forces you to perform a full table scan of the Stage table to figure out, which Business Key relations have disappeared. This can be handled in various ways: create a Record Tracking or Effectivity Satellite hanging on the Link; utilize the Driving Key approach; or – the more “straight-forward” way – keep just one Non-Historized Link table and simply counter the whole record as soon as it’s disappeared from the source.
Kind regards,
Your Scalefree Team
There are a few problems with this approach
1) modelling attributes into a link is inflexible to schema evolution — if another attribute is to be added the entire history of the link needs to be considered.
2) if the driving key for the relationship changes then you will need to model a new link
3) non-historised links are exception loading patterns, they are reserved for immutable data that is not expected to change – such as transactions coming in at real-time. Non-historised links are made for speed layer (lambda) where data is not staged.
4) modelling the details as a link is far more effective but adding a counter would mean you have derived data – i.e. it is a business rule and thus something you add to business vault. Non-historised links are not business vault artefacts.
5) how do you deal with a relationship that has returned? i.e. the the employee has returned to his original department.
This flexibility is effectively (pun intended) handled in creating effectivity satellites based on the driving keys of a link. If the driving key changes then the link remains but a new effectivity satellite is created. Effectivity satellites are derived; each new relationship per driving key is given a highdate as an end-date. Each change to that relationship in relation to non-driving key keys of that relationship generates a close record and a new active record (highdate). All of it is insert only. Querying the data is flexible too, pick your driving key(s) (there may be more than one) and select the data from the effectivity satellite based on the date you’re after and you can trace the number of times the relationship has changed.
You can even trace when the relationship was lost. i.e. a null was presented from source for the non-driving key business keys making it a zero key and we can easily trace that through this construct. Effectivity satellites need a driving key and are all about the relationship and not the contextual information for that relationship. i.e the column salary would sit in a link-sat for that relationship and not in the effectivity satellite. If start and end dates are provided by the source system then this is a regular satellite and not an effectivity satellite.
Hi Patrick,
thank you for your feedback. Here are my 2 cents on your challenges:
1) you could just add a non-historized satellite to the existing link to capture additional entities without reloading and restating the link data
2) non-historized links should not be used to capture relationships (like employee to manager) but instead focus on transactions and events. I have to admit, I’m not a big fan of the driving key concept and to be honest – avoid it like the pest. Which means that I try to find a better solution for a driving key (in a non-historized link, that is a counter-transaction).
3) not necessarily. We used it with banks (for example) to capture booking transactions that were loaded in batches via stage. In other words: every entity (hubs, standard links, non-historized links and any satellite) can be loaded in batch, near-realtime or “actual” realtime.
4) Any entity type can be part of the Business Vault. The difference between Raw Data Vault and Business Vault is that the Raw Data Vault contains raw, unmodified data, while the Business Vault contains calculated, pre-processed data. For the Raw Data Vault, the question is: can you re-construct the delivery as it was delivered from the source? We can, even with the technical counter transactions. Therefore it meets the Raw Data Vault definition (but I have to admit, it is a border case).
5) Again, I would not use non-historized links to capture relationships. Use a standard link in combination with an effectivity satellite to capture the business driven “employement start and end-date”.
I hope that clarifies it a bit.
Mike
Very interesting approach I like it. One thing I haven’t wrapped my head around yet is: where do we get the BK for the changing HK(s) for (not part of the driving key, in this article the Department BK) , to calculate the Unique Hash key for the counter transaction? From the hub(s)?
Hi Johan,
thank you very much!
In this case, you don’t need the Business Key. Keep in mind that this is a possible approach if no audit trail is provided by the source system, which means that you have to do a complete lookup back into the staging to figure out whether or not a Link Hash Key (the most recent record) still exists. If not, you create the “counter booking”, based on the Link itself with the counter value -1.
Hope this helps.
Kind regards,
Your Scalefree Team