
Der Kunde ist ein Tochterunternehmen, das sich auf Informationstechnologie und Telekommunikation im Transportsektor spezialisiert hat und gleichzeitig seine Muttergesellschaft und verschiedene Geschäftsbereiche unterstützt.
Über den Kunden
Problemstellung
Der Kunde möchte seine Datenintegration und die Bereitstellung von Datenprodukten verbessern und gleichzeitig die gesetzlichen Anforderungen besser einhalten. Das bestehende data warehouse-System behindert jedoch die Erreichung dieses Ziels erheblich:
- Hohe Wartungskosten aufgrund einer veralteten Technologie
- Kostspielige, zeitintensive Integration ihrer komplexen Quellsysteme
- Die aktuelle Lösung war für die Einhaltung der GDPR nicht gut gerüstet
Die Herausforderung
Das Datenteam des Kunden ist zwar technisch versiert, wird aber durch seine Unerfahrenheit bei der Entwicklung und Implementierung einer Data Vault 2.0-ähnlichen Architektur und einen etwas langsamen Entscheidungsfindungsprozess eingeschränkt. Zusätzlich zu den genannten Problemen stieß das Team auf weitere Herausforderungen:
- Zeitliche Beschränkungen bei einem bereits beschlossenen End-of-Life-Altlager
- Ressourcenprobleme, da die Teammitglieder verpflichtet waren, die Produktion am Laufen zu halten
Die Lösung
Als Teil unserer Lösung überprüften wir das aktuelle data warehouse des Kunden und führten eine Werkstatt über unsere Erkenntnisse mit ihnen. Wir konzentrierten uns vor allem auf die Organisation und Modellierung, gaben Empfehlungen zur Umsetzung der GDPR-Compliance und zur Nutzung von Automatisierungstools wie Turbovault4dbt von Scalefree und dbt mit datavault4dbt sowie zur raschen Integration ihrer Quellsysteme in die Datenplattform bei gleichzeitiger Kostenreduzierung.
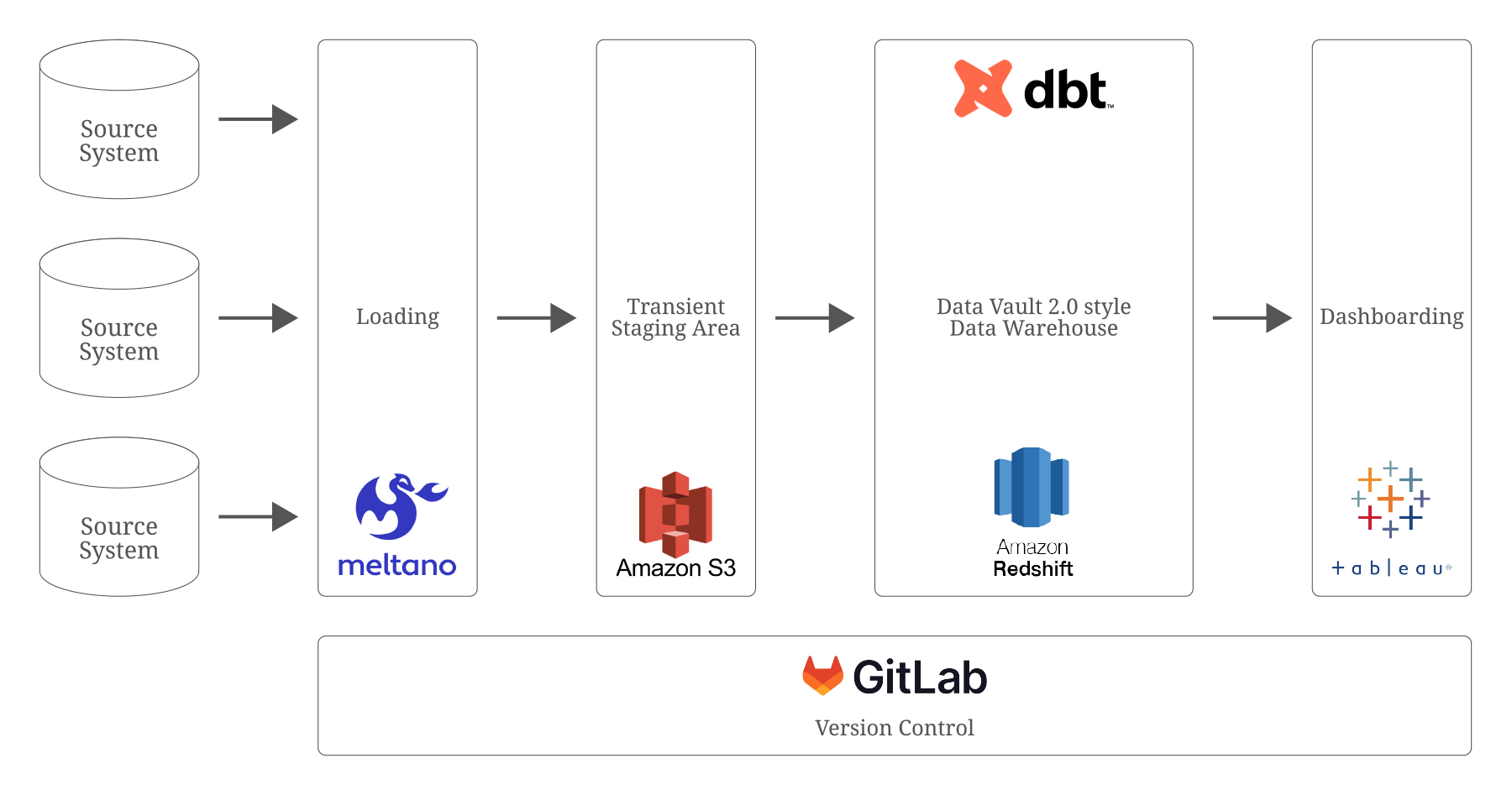
Konkrete Ergebnisse für den Kunden
Wir haben uns darauf konzentriert, unser Wissen weiterzugeben, das Datenteam zu befähigen und es mit allem auszustatten, was es braucht, um mit der Implementierung einer data warehouse gemäß den Data Vault 2.0-Standards zu beginnen und so den Weg zu einer schnelleren Datenintegration und einer effizienteren, kostensparenden Bereitstellung von Datenprodukten zu beschleunigen.
Beteiligte Technologien
- Meltano
- Data Lake auf AWS S3
- EDW auf Redshift
- dbt Kern
- Dashboarding mit Tableau
- Visuelle Modellierung mit draw.io
- Gitlab
