CI/CD
CI/CD-Pipelines werden immer wichtiger, um sicherzustellen, dass Software-Updates kostengünstig und in hoher Qualität veröffentlicht werden können. Aber wie genau funktionieren CI/CD-Pipelines, und wie kann ein Projekt von ihrer Nutzung profitieren?
Dieser Newsletter soll diese Fragen anhand eines praktischen Beispiels für eine CI/CD-Pipeline beantworten. Das Beispiel konzentriert sich auf eine CI/CD-Pipeline für ein GitHub-Repository, das ein Paket zur Implementierung von Data Vault 2.0 in dbt über verschiedene Datenbanken hinweg beinhaltet. Daher wird dieser Newsletter auch die Grundlagen von dbt und GitHub Actions behandeln.
Von kontinuierlicher Integration zu Data Vaults: Ein umfassender Workflow
In diesem Webinar wird erläutert, was CI/CD-Pipelines sind und welche Vorteile sie bieten. Wir werden Teile der CI/CD-Pipeline für das öffentliche datavault4dbt-Paket vorstellen, um zu zeigen, wie eine CI/CD-Pipeline verwendet werden kann. Im Webinar werden die wichtigsten Funktionen von GitHub Actions vorgestellt und anhand von Beispielen erläutert. Dabei wird gezeigt, wie jede Funktion in der Praxis genutzt werden kann und welche verschiedenen Möglichkeiten GitHub Actions bietet. Das Webinar zielt darauf ab, die Vorteile von CI/CD-Pipelines zu erklären und anhand eines praktischen Beispiels zu zeigen, wie eine solche Pipeline aussehen kann.
Was ist CI/CD?
CI steht für Continuous Integration, und CD steht für Continuous Delivery oder Continuous Deployment. Aber was genau bedeuten diese Begriffe?
Unter Continuous Integration versteht man das regelmäßige Zusammenführen von Codeänderungen, wobei automatisierte Tests durchgeführt werden, um mögliche Fehler frühzeitig zu erkennen und sicherzustellen, dass die Software in einem funktionsfähigen Zustand bleibt.
Bei Continuous Delivery wird der validierte Code in einem Repository zur Verfügung gestellt. Zu diesem Zweck sollten in der Pipeline bereits CI-Tests durchgeführt werden. Es umfasst auch weitere Automatisierungen, die für eine schnelle Bereitstellung erforderlich sind, wie die Erstellung eines produktionsbereiten Builds. Der Unterschied zwischen Continuous Delivery und Continuous Deployment besteht darin, dass bei Continuous Deployment die erfolgreich getestete Software direkt für die Produktion freigegeben wird, während bei Continuous Delivery alles für die Freigabe vorbereitet wird, ohne dass es automatisch bereitgestellt wird.
Continuous Deployment ermöglicht eine schnelle Umsetzung von Änderungen durch viele kleine Versionen anstelle einer großen Version. Allerdings müssen die Tests gut konfiguriert sein, da es keinen manuellen Übergang zur Produktion gibt.
CI/CD-Pipelines bieten eine immense Zeitersparnis durch Automatisierung. Auch die Kosten für die Ressourcen, die für manuelle Tests benötigt werden, sind mit CI/CD-Pipelines geringer, da sie so konfiguriert werden können, dass Ressourcen nur für Tests hochgefahren und danach wieder heruntergefahren werden. Da keine permanenten Ressourcen erforderlich sind, zahlen Sie nur für die während der Testlaufzeit benötigten Ressourcen.
Einführung in dbt
Die Abkürzung dbt steht für "data build tool". dbt ist ein Werkzeug, das die Datentransformation direkt innerhalb eines Data Warehouses ermöglicht. Es verwendet SQL-basierte Transformationen, die direkt in der dbt-Umgebung definiert, getestet und dokumentiert werden können.
Das macht dbt zu einer ausgezeichneten Wahl für die Umsetzung von Data Vault 2.0 da dbt verwendet werden kann, um die von Data Vault benötigten Hubs, Links und Satelliten zu erstellen und zu verwalten.
Um diesen Prozess zu erleichtern, haben wir bei Scalefree das datavault4dbt-Paket entwickelt. Datavault4dbt bietet viele nützliche Funktionen, wie z. B. vordefinierte Makros für Hubs, Links, Satelliten, den Staging-Bereich und vieles mehr.

Für ein tieferes Verständnis von dbt oder datavault4dbt bieten wir Ihnen gerne weitere unserer Artikel zu diesem Thema.
Die Möglichkeiten von GitHub Actions
GitHub Actions ist eine Funktion von GitHub mit der Sie Workflows direkt in GitHub-Repositories erstellen und ausführen können. Sie können verschiedene Auslöser für Workflows definieren, z. B. Pull Requests, Commits, Zeitpläne, manuelle Auslöser und mehr.
Dadurch ist GitHub Actions ideal für den Aufbau von CI/CD-Pipelines für private und öffentliche Repositories. Die Workflows sind in mehrere Jobs unterteilt, die jeweils aus mehreren Schritten bestehen. Jeder Job wird auf einer anderen virtuellen Maschine ausgeführt.
Innerhalb dieser Schritte können Sie benutzerdefinierte Aufgaben definieren oder externe oder interne Workflows verwenden. Dies bietet den großen Vorteil, dass Sie nicht alles in einem Workflow von Grund auf neu entwickeln müssen, sondern öffentliche Workflows nutzen können, die von anderen erstellt wurden.
Die nahtlose Integration von Docker bietet zudem zahlreiche Möglichkeiten, wie z.B. das schnelle Einrichten verschiedener Testumgebungen, was die Erstellung einer CI/CD-Pipeline erheblich vereinfacht.
GitHub Actions ist das Schlüsselwerkzeug in dem folgenden Beispiel einer CI/CD-Pipeline.
Praktisches Beispiel: CI/CD-Pipeline für datavault4dbt
Für das öffentliche Repository des datavault4dbt-Pakets haben wir eine CI/CD-Pipeline eingerichtet, um sicherzustellen, dass alle Funktionen mit jedem Pull Request(PR) für alle unterstützten Datenbanken weiterhin funktionieren. Wenn ein PR von einem externen Benutzer eingereicht wird, muss jemand aus unserem Entwicklerteam den Start der Pipeline genehmigen. Im Gegensatz dazu kann ein PR von einem internen Benutzer automatisiert werden, indem ein bestimmtes Label hinzugefügt wird, um die Pipeline zu starten.
Sobald die Pipeline ausgelöst wird, startet GitHub Actions automatisch eine separate virtuelle Maschine (VM) für jede Datenbank. Derzeit unterstützt das Paket datavault4dbt AWS Redshift, Microsoft Azure Synapse, Snowflake, Google BigQuery, PostgreSQL und Exasol, sodass insgesamt sechs VMs gestartet werden. Da GitHub Actions serverlos arbeitet, müssen diese VMs nicht manuell eingerichtet oder verwaltet werden.
Die VMs stellen dann eine Verbindung zu den erforderlichen Cloud-Systemen her. Zum Beispiel verbindet sich die VM für Google BigQuery mit Google Cloud, während die VM für AWS Redshift mit AWS verbunden wird. Anschließend werden die erforderlichen Ressourcen für jede Datenbank generiert, was über API-Aufrufe oder mithilfe von Tools wie Terraform erfolgen kann.
Nachdem die Ressourcen erstellt wurden, werden zusätzliche Dateien, die für die Tests benötigt werden, generiert und in die VM geladen. In unserer Beispielpipeline sind dies Dateien wie profiles.yml, die Informationen enthalten, die dbt für die Verbindung mit den Datenbanken benötigt.
Als nächstes wird auf jeder VM ein Dockerfile verwendet, um ein Image zu erstellen, das automatisch alle Abhängigkeiten für die jeweilige Datenbank installiert. In dieser Phase wird auch Git auf jedem Image installiert, damit Tests, die in einem separaten Git-Repository gespeichert sind, auf das Image geladen werden können.
Das Laden der Tests aus einem Repository ermöglicht eine zentrale Verwaltung der Tests und stellt sicher, dass alle Änderungen für jede Datenbank während des nächsten Pipelinelaufs ausgeführt werden. Sobald die Images erstellt sind, werden Container basierend auf diesen Images erstellt, in denen Tests mit verschiedenen Parametern durchgeführt werden. Nach Abschluss aller Tests werden die Container heruntergefahren, und standardmäßig werden die Ressourcen bei den jeweiligen Cloud-Anbietern gelöscht.
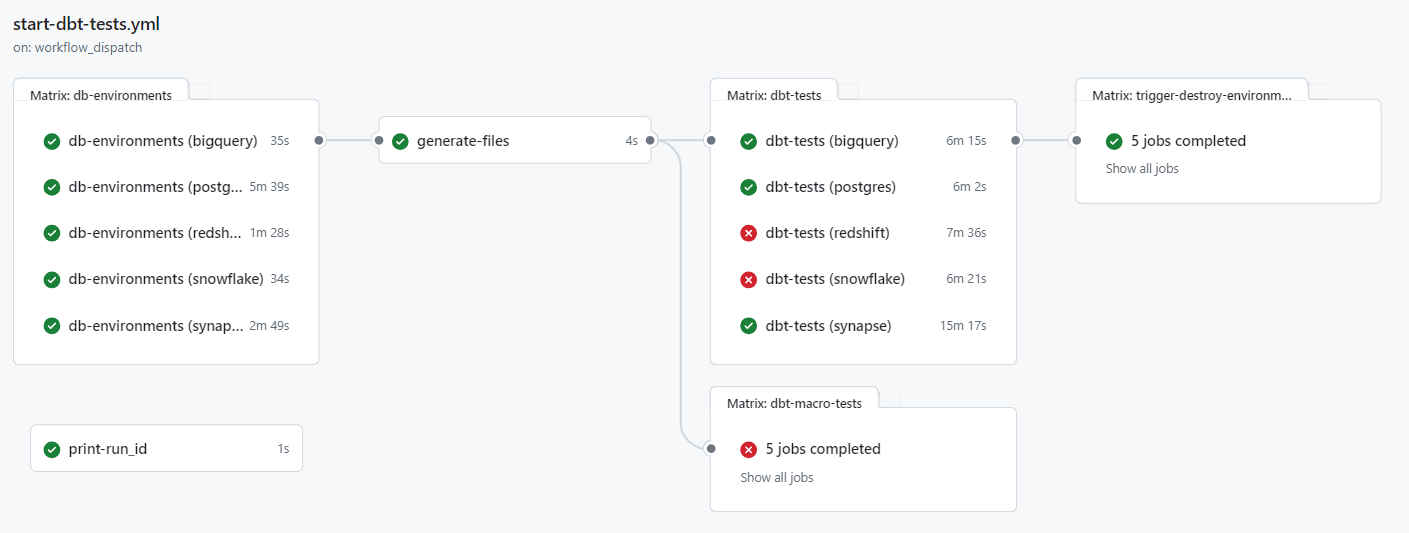
Die Testergebnisse sind in GitHub Actions vollständig sichtbar, wobei erfolgreiche und fehlgeschlagene Tests deutlich gekennzeichnet sind.

Wird die Pipeline manuell gestartet, kann zusätzlich festgelegt werden, ob nur bestimmte ausgewählte Datenbanken getestet werden sollen und ob die Ressourcen auf den Cloud-Systemen nach den Tests erhalten bleiben sollen. Dies ermöglicht es den Entwicklern, die Daten auf den Datenbanken genauer zu untersuchen, sollten Fehler auftreten.
Diese Pipeline bietet zahlreiche Vorteile für die Entwicklung des datavault4dbt-Pakets. Sie ermöglicht das Testen auf Fehler in jeder der unterstützten Datenbanken bei jeder Änderung, ohne viel Zeit für die Erstellung von Testressourcen aufzuwenden. Gleichzeitig spart sie Kosten, da alle Ressourcen nur so lange wie nötig laufen und nach den Tests sofort heruntergefahren werden.
Die Verwaltung der Pipeline wird durch GitHub ebenfalls vereinfacht, da alle Variablen und Geheimnisse direkt in GitHub gespeichert werden können und somit ein zentraler Ort für alles zur Verfügung steht. Sobald die Pipeline eingerichtet ist, kann sie leicht erweitert werden, um zusätzliche Datenbanken einzubeziehen, die in Zukunft unterstützt werden könnten.
Letztlich ist dies nur ein Beispiel dafür, wie eine CI/CD-Pipeline aussehen kann. Solche Pipelines sind so vielfältig wie die Software, für die sie entwickelt werden. Wenn wir Ihr Interesse geweckt haben und Sie weitere Fragen zu einer möglichen Pipeline für Ihr Unternehmen haben, kontaktieren Sie uns gerne..
Fazit
In diesem Newsletter werden die Vorteile und die Funktionsweise von CI/CD-Pipelines in der agilen Softwareentwicklung anhand eines praktischen Beispiels mit einem GitHub-Repository und einem dbt-Paket für die Implementierung von Data Vault 2.0 erläutert, wobei Tools wie GitHub Actions für die Automatisierung und Effizienz der Bereitstellungsprozesse hervorgehoben werden.
- Damian Hinz (Scalefree)