
Non-Historized Links in Data Vault 2.0
Non-Historized Links in Data Vault 2.0 vereinfachen die Datenmodellierung, indem sie sich auf aktuelle Beziehungen statt auf historische Änderungen konzentrieren. Das steigert die Effizienz, reduziert die Komplexität und verbessert die Abfrage-Performance für agilere Analysen.
Einführung in Non-Historized Links
Non-historized Links, auch bekannt als Transaction Links, sind ein zentrales Element des Data Vault 2.0-Frameworks – aber wie funktionieren sie eigentlich im Modell? Als Dan Linstedt, Mitbegründer von Scalefree, Data Vault erfand, verfolgte er mehrere Ziele. Eines davon: Daten so schnell wie möglich aus der Quelle ins Data-Warehouse-Modell laden, zu Informationen verarbeiten und dem Business-Analysten in jeder gewünschten Zielstruktur bereitstellen.
Zur Vereinfachung und Automatisierung im Data Warehouse besteht das Data Vault 2.0 Modell aus nur drei grundlegenden Entitätstypen:
- Hubs: eine eindeutige Liste von Business Keys
- Links: eine eindeutige Liste von Beziehungen zwischen Business Keys
- Satellites: beschreibende Daten, die den übergeordneten Schlüssel (Business Key oder Beziehung) in einem bestimmten Kontext über die Zeit versioniert beschreiben
Wie wir stets lehren (und manchmal predigen): Mit diesen drei Entitätstypen lässt sich grundsätzlich das gesamte Unternehmensdatenmodell abbilden. Ein Modell, das ausschließlich darauf setzt, bringt jedoch einige Nachteile mit sich – etwa komplexe Joins, hohen Speicherbedarf, geringere Ladeleistung und verpasste Chancen bei der Virtualisierung.
Die Lösung? Die Kernbausteine des Data Vault lassen sich um einige zusätzliche Elemente ergänzen, um genau diese Schwächen auszugleichen. Eines davon ist der Einsatz von Non-Historized Links, auch bekannt als Transaction Links:

In diesem Beispiel lassen sich Sales mit Non-Historized Links modellieren, die einzelne Transaktionen eines Customer im Zusammenhang mit einem Store erfassen. Ziel dieser Links ist es, sowohl beim Laden ins Data Warehouse als auch beim Abfragen eine hohe Performance sicherzustellen. Nicht vergessen: Ziel von Data Warehousing ist es, ein funktionierendes Data Warehouse aufzubauen – nicht nur ein Modell zu entwerfen. Und dafür braucht es mehr als nur das Modell: Menschen, Prozesse und Technologie.
Hauptmerkmale von Non-Historized Links
Wie also helfen Non-Historized Links dabei, diese Ziele zu erreichen? Denk an deine Business-Analysten. Was sind ihre Ziele? Um ehrlich zu sein: Sie interessieren sich in der Regel nicht für ein Data-Vault-Modell. Stattdessen möchten sie dimensionale Modelle sehen – etwa Star Schemas, Snowflake Schemas oder Flat-and-Wide-Modelle fürs Data Mining. Oder sie wollen gelegentlich die alten, unansehnlichen Tabellen vom Mainframe sehen – manchmal verknüpft, manchmal nicht –, bei denen kaum noch jemand die Beziehungen versteht... Aber für die Abwärtskompatibilität ist das völlig in Ordnung.
Ist das Ziel definiert, stellt sich die nächste Frage: Was ist die Zielgranularität? In einem dimensionalen Modell spiegelt die Zielgranularität von Fact Tables häufig die zu analysierenden Transaktionen wider – (zum Beispiel Anrufdatensätze in der Telekommunikationsbranche oder Buchungen im Bankwesen).
Interessanterweise lässt sich diese gewünschte Zielgranularität oft direkt in den Quellsystemen finden. Denn ein Telekommunikationsanbieter hat ein operatives System, das jeden einzelnen Anruf erfasst. Oder eine Bankanwendung zeichnet jede Kontobewegung auf. Diese Datensätze werden in der Regel ohne Aggregation in das Data Warehouse geladen – zumindest im Data Vault, wo wir an der feinsten Granularität für Prüf- und Lieferzwecke interessiert sind.
Und hier zeigt sich ein Problem der Standard-Entitätstypen im Data Vault. Sie sind zwar einfach und standardisiert, bringen aber eine Einschränkung mit sich. Denn wie bereits erwähnt, speichert der Standard-Link „eine eindeutige Liste von Beziehungen“. Das bedeutet, dass nur solche Relationen aus der Quelle berücksichtigt werden, die dem Ziel-Link noch nicht bekannt sind. Wenn ein Customer also mehrmals in denselben Store geht und dasselbe Product kauft, ist diese Beziehung bereits bekannt – und es wird kein zusätzlicher Link-Eintrag erzeugt.
Infolgedessen ändert sich die Granularität der eingehenden Daten beim Laden des Links. Wenn die Beziehung einer Transaktion bereits bekannt ist, wird diese Transaktion ausgelassen – und stattdessen durch einen Satellite erfasst.
Das nächste Problem: Die Link-Granularität unterscheidet sich nun von der Zielgranularität, da der Business-Analyst einen Datensatz pro Transaktion erwartet, nicht nur pro eindeutiger Beziehung. Es ist ein weiterer Grain Shift erforderlich – typischerweise durch das Joinen des Satellites mit dem Link, um die ursprüngliche Granularität wiederherzustellen.
Wie wir in unserem Buch "Building a Scalable Data Warehouse with Data Vault 2.0" beschrieben haben, ist ein solcher Grain Shift (in Bezug auf die Leistung relativ kostspielig). Denn der Vorgang erfordert aufwendige GROUP BY-Operationen oder LEFT- und RIGHT-JOINs.
Und wofür das Ganze? Das Endergebnis beider Schritte ist häufig wieder die ursprüngliche Granularität aus dem Quellsystem. Zwei teure Grain Shifts – für nichts.

Genau das ist der Punkt.
Hier kommen Non-Historized Links ins Spiel: Sie sind eine einfache Variation des Standard-Links – mit dem Ziel, Quelltransaktionen und Events in ihrer ursprünglichen Granularität zu erfassen.
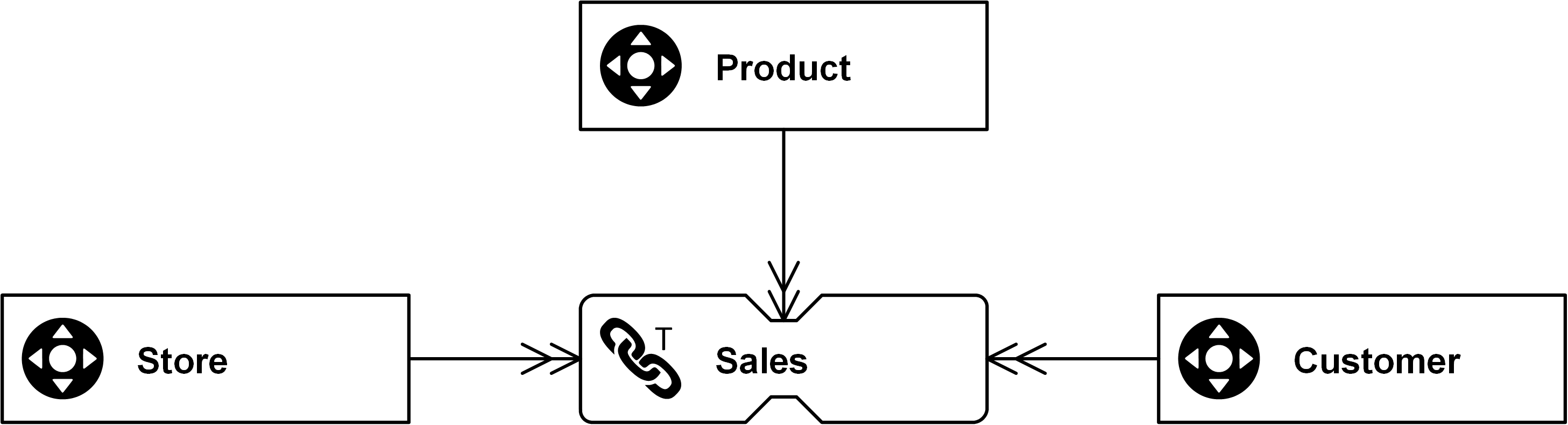

Abbildung: Non-Historized Link mit Sales ID als zusätzlichem Schlüssel
Ein komplexeres Szenario wäre der Fall, dass dasselbe Product – also die feinste Granularität – innerhalb eines Sales zweimal vorkommt, zum Beispiel aufgrund unterschiedlicher Rabatte. In diesem Fall dient die Position des einzelnen Line Items als zusätzlicher Schlüssel (Dependent Child Key), um jeden Datensatz eindeutig zu machen.
Aus Performance-Gründen sollten Grain Shifts beim Auslesen ebenfalls vermieden werden. Wenn eine abweichende Zielgranularität benötigt wird, die sich weder aus dem Quellsystem noch aus dem Data-Vault-Modell direkt laden lässt, empfiehlt sich der Einsatz einer Bridge Table. Diese modelliert den Grain Shift explizit und bietet gleichzeitig die Möglichkeit, das Zielmodell flexibel an die Anforderungen des jeweiligen dimensionalen Zielmodells anzupassen.
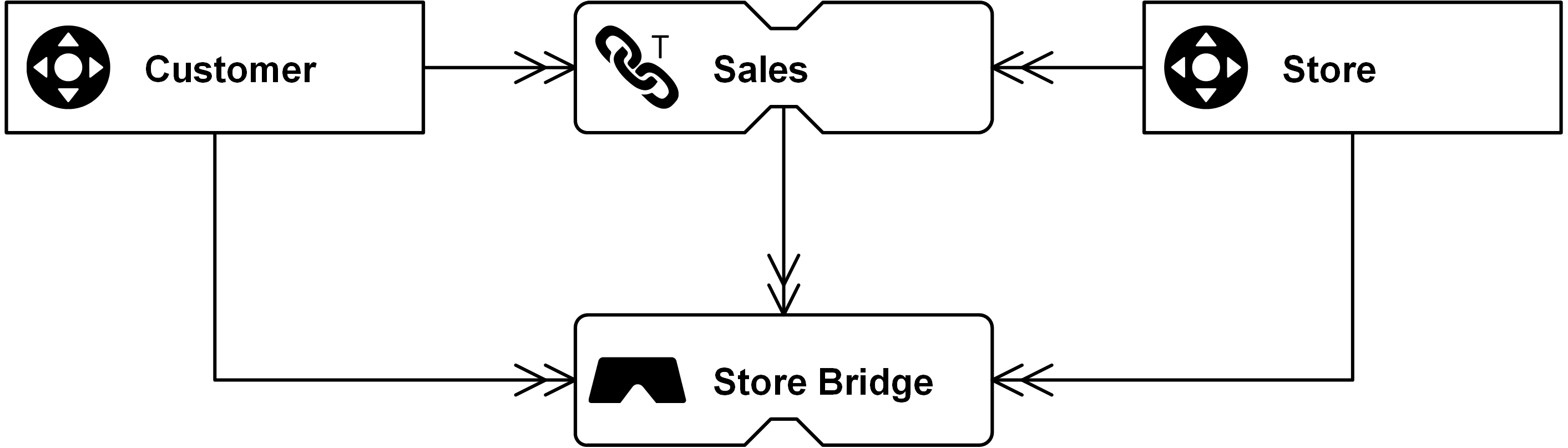
Abbildung: Virtuelle Bridge Table als Fact Table mit GROUP BY Store Hash Key
Fazit
Non-Historized Links bieten einen einen vereinfachten und performanten Ansatz für die Data-Vault-Modellierung. Sie optimieren die Performance und vereinfachen die Datenstrukturen. Durch den Fokus auf aktuelle Beziehungen statt historischer Änderungen steigern sie die Effizienz, senken den Speicherbedarf und verbessern die Abfragegeschwindigkeit. Ihre Integration in die Datenarchitektur kann zu einer agileren und besser skalierbaren Analyseumgebung führen.
What should I do if there is no useful additional key like the sales_id in the example.
The source only provides the load timestamp?
Hello Oliver,
with the assumption that the transaction itself is not related to a business process (like a sale), but comes in real-time from a machine, sensor or similar, you can use a sequence in the NH-Link.
Best regards,
Your Scalefree Team
As there are no satellites for NH-Link and descriptive data is part of it, what if any attributes need to be added or removed as per source data changes ? Will it not impact/compromise the flexibility ?
Hi Siva,
in order to add descriptive data to a non-historized link, you have two options:
1. Have the descriptive attributes denormalized to the link entity
2. Have a “non-historized satellite” (PK = HK of parent, no LDTS) attached to the link with a 1:1 relationship
If your descriptive data changes, turn it into a standard satellite. If the attributes in the link change over time, use counter-transactions.
Hope that clarifies it a bit. We discuss these topics in training in much more detail (hope to see you there 😉 )
Cheers,
Mike
a non-historized link supports the use of “non-historized satellites” bes
If a source system holds counter-transactions with a reference back to the original transaction being reversed and we load both original and counter transactions into a non-historized link; what would be the preferred approach to preserving that reference between the original and counter transactions received from the source system?
The only options I can think of are:
1) Is this one of the rare cases for using a Link against another Link, with, say, a dedicated ‘Reversal’ Link joining together the two non-historized link records for original and counter transactions – should not slow down the loading of the actual transactions into the non-historized link if it is just loaded where it occurs in an independent process, but does introduce additional change dependencies on the non-historized link, albeit pretty focused as the additional link only joins to the same non-historized link twice.
2) Document the id of the original transaction in a non-historized satellite against the non-historized link record for the counter transaction – feels like a bit of a cop-out as there is a genuine relationship between the two non-historized transactions, it is not really just descriptive information and would make any attempt to navigate between the original and counter transactions by consumption processes very inefficient.
Hi Richard,
the recommendation here is to use one Non-Historized Link for both transactions, and the audit trail is kept in a Same-As-Link. When your source system delivers counter transactions with relation to the original one, this is the best-case scenario you can have to make the loading as easy as possible while having an audit trail in place. The assumption here is that each transaction has a consistent singular ID (e.g. transaction ID) in addition to the original reference. Use this attribute as the “dependent child key” (part of the Link Hash Key but no own Hub) and load the counter transaction into the same Non-Historized Link as they come from the source. The assumption here is that the values are multiplied with (-1) by source system, or any other recognition that this is a counter transaction. Additionally, load both, the Link Hash Key from the original record and the Link Hash Key from the counter record into a Same-as-Link to keep the audit trail with the effective date.
Kind regards,
Your Scalefree Team
The SAL should refer to the transaction ID in this example to avoid link-to-link models.
I have case where there is no unique key in source data. Certain batch corrections create multiple identical rows that are counter actions for rows that were not identical to begin with. To oversimplify a bit there could be salary paid on April and March and then at May salary correction that create 2 rows saying like: “person A got paid incorrect amount X” and another 2 rows saying like: “person A should have been paid amount X”. The problem is, that the stamp goes on basis on the time of the correction, not the time of the corrected event, which makes these rows as two pair of rows that each are identical to every column data has within pair, including milliseconds of the stamp. So the case differs from customer – product – purchase example and the first question in that sense that there is no distinction of time between the legal multiples. As said, this is oversimplification. Actual data has in worst cases tens of identical rows that need to be considered as different instances of data.
My question is. Is there any salvation in situation like this provided that no changes are done at the source system?
Hi Jarmo,
You need to identify that a record is a “counter” to an original record (there is no way around). When you have this information you can add the counter records into the Non-Historized Link. You have to add/change 2 things: 1. Add a counter column with the value “1” for original records and a “-1” for counter records. 2. The counter value (1 or -1) as well as the load date timestamp needs to be added to the Link Hash Key calculation (alternative is to add only the counter column and make the load date timestamp as additional PK). Here you can see another blog post where we handle this situation: https://www.scalefree.com/scalefree-newsletter/delete-and-change-handling-approaches-in-data-vault-without-a-trial/
Hope this helps.
Marc
I have a case where the transactions (roster entries) can go through corrections over time. You suggest in such a case to convert the link into a standard satellite to capture history. I wonder though if you mean actually a link-sat instead of a hub-satellite, I can’t see the point of a hub-sat when the roster entries have as a composite key other hub entries. Thanks in advance.
Hi Edwina,
Depends on what the data is describing. If it’s the relationship of all related Hubs, then it’s a Link-Satellite, if you created a Hub (i.e. roster_hub) where the data fits to, then a Hub-Satellite makes more sense. This is also discussed in our Boot Camp btw. 😉
Kind regards,
Marc
NHL use cases are mostly to deal with transactions as a whole. If business needs to analyze transactions as a whole after some data transformation business rules, the option suggested is having a Satellite. Since transactions as a whole cannot be under a single hub, they will belong under a link in most cases. Since these are business vault satellites, they do need to allow for business rule changes and hence mutable. This is fairly straight forward as long as transactions can be uniquely identified with a combination of hubs that will make the normalized link.
If the transactions cannot be identified with a combination of hubs (even degenerate keys combined) and whole set of columns of NHL is needed to identify uniquely, the business vault link will end up being the NHL itself. In which case, this Business vault NHL will have to be updateable to allow for business rule changes .
Hello!
I have a use case, where I don’t have a descriptive attributes for the link but I want to track a history of relationship of that link.
Should I use Satellite without descriptive attributes, which tracks only inserts and deletes?
Hi Daniil,
You should use an Effectivity Satellite for this, tracking which relationship is/was valid at which point in time (based on the ldts). I think this is what you need: https://www.scalefree.com/scalefree-newsletter/handling-validation-of-relationships-in-data-vault-2-0/. Hope this helps.
-Marc
Hi all,
I’m facing with the below use case where I want to use DataVault as design methodology:
I have a message broker source (Solace) system that send messages via broker into PPMP protocol (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
I have stored the incoming data into a staging area having roughly the following structure:
message_id——–queue———–message (storing the message in json )—–load_date——–source_system———some_audit_cols
1 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619010000 SRC1 audit vals
2 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619010000 SRC1 audit vals
1 queue1 {“device”: {}, “part”:{}, {“measurements”: [] etc}} 20220619020000 SRC1 audit vals
The business wants to have a start schema in information marts some similar with the model from PPMP protocol (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
It is a good approach to design this data messages in raw vault using only non-historized link? The link will have: lnk_hk , hub_device_hk, hub_part_hk, message_id, message etc.
Namely, all data will be stored in this link including the descriptive fields too (message, queue, etc). No required any link satellites due there is not history for incoming messages.
The identified hubs are: hub_device, hub_part (having their own satellites)
Afterward, I should also create some business vault entities that can help other information marts to calculate easy and quickly the KPIs.
I’m looking forward your feedback.
Regards,
Laurentiu
Hi Laurentiu,
all of the above sounds good 🙂
-Marc
I have a case where source system is sending 2 datasets. First dataset contains the Key and its attribute. Second dataset contains different transactions for a particular key. Second data set may or may not contain key. For e.g. first dataset contains account no and second dataset contains txns associated with a particular account no. Now, there can be a scenario where the second dataset may not contain an account no because no txn has occurred. Lastly, the existing txns can also be updated from source. Second dataset also has bunch of attributes along with txn id. Now, i have created a hub (hub account) but, facing challenge how to model the second dataset.
– As per my understanding the second dataset cannot be a direct sat attached to hub as the grain will differ
– Another approach I am thinking of having a transaction link (with Account number and txn id ) and then a txn link sat (but this sat will act as a normal sat to the link because a particualar txn can be updated later on. So, the sat will have multiple records for a txn but only one will be active or latest)
Can you please let me know if this approach is ok to follow or is there any better approach? Thanks in advance
Hi Kapil,
Different grain means different Hub, or in your case, a different Non-Historized Link including the transaction number as additional Key. Your second approach sounds valid. Another one could be to model transaction as an own Hub and hang the standard Satellite on it.
Hope this helps.