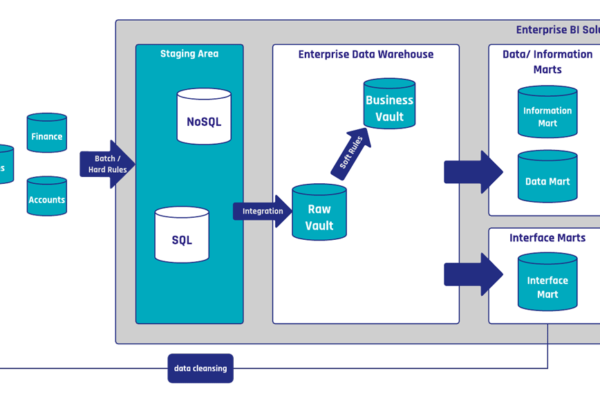
Skilled modeling is important to harness the full potential of Data Vault 2.0. To get the most out of the system due to scalability and performance, it also has to be built on an architecture which is completely insert only. On the way into the Data Vault, all update operations can be eliminated and loading processes simplified.
THE COMMON IMPLEMENTATION
In the common loading patterns, there are two important technical timestamps in Data Vault 2.0. The first is the load date timestamp (LDTS). This timestamp does not represent a business date that comes from the source system. Instead, it provides the information about when the data was first loaded into the data warehouse, usually the staging area.
Therefore, it is completely different from the various business dates that come from the source systems including a business meaning. For this reason, it must be generated for a whole batch loading process. Business dates, for example validation dates, are stored in effectivity satellites, which are mostly found connected with link entities. They provide information about the relationship of business objects with begin and end date of a relationship.
The second technical timestamp is the load end date timestamp (LEDTS). Like the LDTS, the LEDTS is system-generated and occurs in satellite entities only. As those satellites are delta driven, there is always one record which represents the most recent delta. The value of the LEDTS on those records is usually ‘9999-12-31’ (end of time) or NULL. The following figure shows the whole end dating process which comes with the usage of the LEDTS attribute. It is executed after the loading process of the satellite (not in the loading process):

The figure shows that we have to update the satellite with the new LEDTS value which costs performance. As mentioned in the beginning we want to remove the LEDTS updates to get more performance with a 100% insert only architecture.
At this point, a typical question is how to query the most recent delta in a satellite when we don’t have the LEDTS anymore? Using max(LDTS)? For sure not.
THE ADVANTAGE OF PIT TABLES
The answer is to use window functions to load your point in time (PIT) tables. We covered the topic PIT tables with an example from the insurance industry in our newsletter from October 2018. The purpose of PIT tables is to improve the query performance by eliminating outer joins and allow inner joins with equi join conditions for performance reasons. We highly recommend building a PIT table as the better alternative to the LEDTS. The PIT table is built using window functions to find the most recent delta in the satellite. Once it is created with snapshots of the current data, we don’t have to query on the LDTS with BETWEEN conditions. The temporal history is stored as snapshots and can be queried with equi join conditions on the Hash Key and the LDTS to the related satellites. Due to the fact that the PIT tables grow, it is recommended to create partitions on the snapshot date. At the end, the (visualized) Information Mart dimensions can be easily queried directly from the PIT table and the related satellites.
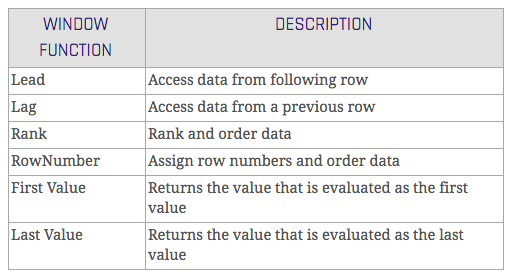
By using window functions on the Hash Key (partition) and the LDTS (order) you can identify the most recent delta, which is dynamically calculated. There are some window functions that can be used for finding the most recent delta. The following table shows some examples for window functions.
A reason for the existence of the LEDTS in Data Vault is that many databases in the early 21st century were not supporting window functions or there were not fast enough.
As already mentioned in the previous newsletter of October 2018, the purpose of PIT tables is to allow inner joins with equi join conditions. But they are also the key to get to an insert only implementation of Data Vault 2.0, which allows more efficient loading processes.
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Um die Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio zu unterstützen, wurde eine Schablone implementiert, die zum Zeichnen von Data Vault-Modellen verwendet werden kann. Die Schablone ist erhältlich bei www.visualdatavault.com.