
Einfach ausgedrückt, ein Enterprise Data Warehouse (EDW) sammelt Daten aus unternehmensinternen und -externen Datenquellen, um sie für einfache Berichte und Dashboards zu verwenden. Oft werden auf diese Daten einige analytische Transformationen angewandt, um die Berichte und Dashboards so zu gestalten, dass sie sowohl nützlicher als auch wertvoller sind. Es gibt jedoch noch weitere wertvolle Anwendungsfälle, die von Unternehmen beim Aufbau einer data warehouse oft übersehen werden. EDWs können nämlich ein ungenutztes Potenzial erschließen, das über die bloße Berichterstattung über Statistiken der Vergangenheit hinausgeht. Um diese Möglichkeiten zu erschließen, bietet Data Vault ein hohes Maß an Flexibilität und Skalierbarkeit, um dies auf agile Weise zu ermöglichen.
Data Vault Anwendungsfälle
Zunächst einmal wird das data warehouse häufig nur zur Datenerfassung und zur Vorverarbeitung der Informationen für Berichte und Dashboarding-Zwecke verwendet. Wenn nur dieser eine Aspekt eines EDW genutzt wird, verpassen die Benutzer Möglichkeiten, ihre Daten zu nutzen, indem sie das EDW auf solche grundlegenden Anwendungsfälle beschränken.
Durch den Einsatz des data warehouse kann eine ganze Reihe von Anwendungsfällen realisiert werden, z. B. zur Optimierung und Automatisierung von Betriebsprozessen, zur Vorhersage der Zukunft, zur Rückführung von Daten in betriebliche Systeme als neuer Input oder zur Auslösung von Ereignissen außerhalb des data warehouse, um nur einige der neuen Möglichkeiten zu nennen.
Datenbereinigung (innerhalb eines operativen Systems)
In Data Vault unterscheiden wir zwischen Rohdaten und Geschäftsdaten. So werden Rohdaten in der Raw Data Vault und Geschäftsdaten in der Business Vault gespeichert. Innerhalb der Data Vault 2.0 wird die Raw Data Vault jedoch verwendet, um die guten, schlechten und hässlichen Daten zu speichern, wie sie vom Quellsystem geliefert werden. Auf der anderen Seite kann der Business Vault beliebige Wahrheiten erstellen, z. B. die Berechnung eines KPI wie Gewinn, entsprechend einer vom Informationsteilnehmer definierten Geschäftsregel.
Für die Berichterstattung und das Dashboarding werden in der Regel Datenbereinigungsregeln angewandt, um die Daten für die jeweilige Aufgabe nützlicher zu machen und somit wiederum die Rohdaten zu nützlichen Informationen zu verarbeiten. Diese Geschäftsregeln für die Datenbereinigung können aber auch dazu verwendet werden, die bereinigten Daten in das operative System zurückzuschreiben. Im besten Fall werden die Geschäftsregeln mit Hilfe von virtualisierten Tabellen und Ansichten innerhalb des Business Vault angewendet. Diese bereinigten Daten können dann in das operative System zurückgeschrieben werden, um das Konzept des Total Quality Management (TQM) umzusetzen, bei dem Fehler an der Wurzel behoben werden, die oft im Quellsystem selbst liegt.
Die Verwendung des EDW für die Datenbereinigung kann also mehrere Vorteile haben. Im Falle von Datenbereinigungstools ist es beispielsweise nicht immer möglich, komplexe Skripte auszuführen. Die meisten Tools haben vordefinierte Listen von Ländern usw., um einige ausgewählte Attribute zu bereinigen. Außerdem sind die meisten Tools für die Bereinigung von Daten aus einem einzigen operativen Quellsystem konzipiert und lassen Inkonsistenzen zwischen mehreren operativen Systemen außer Acht.
Aus der Sicht von Data Vault sind die Datenbereinigungsregeln gewöhnliche Geschäftsregeln. Das heißt, sie werden mit Hilfe von Geschäftssatelliten implementiert, oft mit Hilfe von Referenztabellen. Die folgende Abbildung zeigt ein Beispiel für Datenbereinigung unter Verwendung einer Data Vault 2.0-Architektur, wie sie intern bei Scalefree verwendet wird.
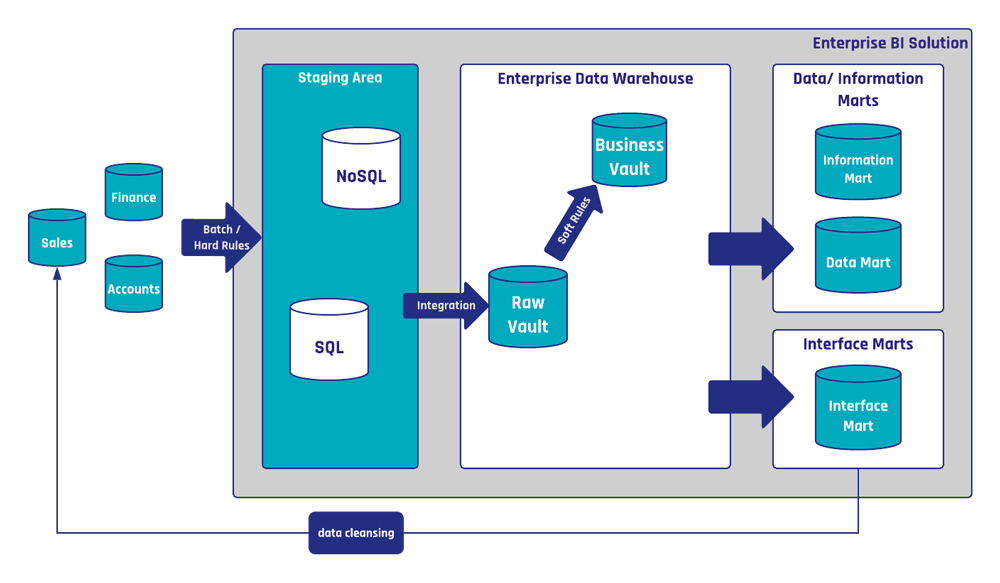
Die Scalefree EDW ist die zentrale Bibliothek für Datenbereinigungsregeln, die in mehreren Systemen wie denen der EDW und operativen Systemen verwendet werden können. Der gezeigte Datenbereinigungsprozess wird unter anderem zur Bereinigung von Kundendatensätzen und zur Standardisierung von Telefonnummern sowie den dazugehörigen Adressen verwendet. Neben der InformationsmärkteDas Interface Mart "Sales Interface" implementiert die API des Verkaufssystems und wendet Datenbereinigungsregeln aus dem Business data vault an. Ein geplantes Schnittstellenskript lädt die Daten aus dem Interface Mart in die API des Quellsystems. In diesem speziellen Fall ist das Skript in Python geschrieben.
Ein wichtiger Aspekt dieses Prozesses ist die ordnungsgemäße Dokumentation der Datenbereinigungsregeln. Eine interne Wissensplattform wird verwendet, um die Dokumentation jeder einzelnen Datenbereinigungsregel zu speichern. Auf diese Weise weiß jeder Mitarbeiter, der auf die Dokumentation zugreift, welche Datenbereinigungsregel für die operativen Daten gilt. Dies kann auch für Geschäftsanwender von Nutzen sein, da sie dann verstehen können, warum ihre Daten über Nacht korrigiert wurden.
Schlussfolgerung
Dank der Flexibilität des Data Vault können Unternehmen neue Funktionen nutzen, die über die Standardberichte und das Dashboarding hinausgehen. So kann das data warehouse zur Datenbereinigung innerhalb der operativen Systeme verwendet werden, indem zentralisierte Bereinigungsregelstandards befolgt werden.
Wenn Sie mehr über Data Vault-Anwendungsfälle und die neuesten Technologien auf dem Markt erfahren möchten, bietet Ihnen das World Wide Data Vault Consortium (WWDVC) eine gute Gelegenheit dazu. Hier haben Sie die Möglichkeit, mit den erfahrensten Experten auf diesem Gebiet zu sprechen. Dieses Jahr findet die Konferenz vom 9. bis 13. September zum ersten Mal in Hannover, Deutschland, statt.
Dort wird Ivan Schotsmans über Informationsqualität im Data Warehouse sprechen. Dabei wird er aufzeigen, wie aktuelle und zukünftige Herausforderungen in Bezug auf die Data-Warehouse-Architektur gemeistert werden können, wie man bei der Implementierung eines neuen data warehouse zu einem agilen Ansatz übergeht und wie man das Business stärker einbindet. Um diese Gelegenheit nicht zu verpassen, melden Sie sich noch heute an, um seine und andere interessante Präsentationen, die von Wherescape, Vaultspeed und vielen anderen Anbietern und Referenten gehalten werden, nicht zu verpassen!
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Um die Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio zu unterstützen, wurde eine Schablone implementiert, die zum Zeichnen von Data Vault-Modellen verwendet werden kann. Die Schablone ist erhältlich bei www.visualdatavault.com.



Hallo,
interessanter Ansatz, danke für den Beitrag. Ich habe eine Frage dazu, wo diese Datenbereinigungsregeln angewendet werden...
1) Zwischen den Quellsystemen und den Staging-Systemen -> Ich gehe davon aus, dass dies nicht der Fall ist, da wir wollen, dass der Staging-Bereich nur zum Laden verwendet wird, um das Quellsystem so schnell wie möglich zu entladen. Nein? Was sind die "harten Regeln" zwischen dem Quell- und dem Staging-System?
2) Die Datenbereinigung zwischen den Interface Marts und den Quellsystemen scheint außerhalb des Tresors zu erfolgen? Bedeutet dies, dass Sie die "bereinigten" Daten nicht direkt im Tresorraum aufbewahren (sondern dass sie nach dem nächsten Laden aus der Quelle automatisch hineingelangen würden)?
Dankeschön
Vielen Dank für Ihren Kommentar!
Unter dem Begriff "harte Geschäftsregeln" fassen wir technische Regeln zusammen, die das korrekte Datenformat beim Laden von Daten aus Quellsystemen in die Staging-Schicht erzwingen. Wenn z.B. ein Attribut Informationen über Zeitpunkte liefert, sollte es vom Datentyp TIMESTAMP oder gleichwertig sein. Die Quellsysteme liefern jedoch manchmal nicht den richtigen Typ. In diesem Fall sollte das Attribut in den richtigen Datentyp umgewandelt werden. Darüber hinaus können harte Geschäftsregeln Normalisierungsregeln sein, die komplexe Datenstrukturen behandeln, z. B. um verschachtelte JSON-Objekte zu glätten.
Zu Ihrer Frage bezüglich der Datenbereinigung: In unserem Beispiel findet der Datenbereinigungsvorgang sowohl innerhalb als auch außerhalb des Data Vault statt. Um die Idee hinter diesem Vorgang zu verdeutlichen, beginnt der Prozess mit der Beschaffung von Daten aus dem Raw Vault, dann werden weiche Regeln zur Korrektur von Telefonnummern und Adressformaten auf die Rohdaten angewandt und die Ergebnisse in die Strukturen des Business Vault geschrieben. Der Interface Mart wählt nur bereinigte Datensätze aus dem Business Vault aus, die noch nicht in das operative Quellsystem zurückgeschrieben wurden. Von dort lädt ein externes Skript die Daten aus dem Interface Mart in die API des Quellsystems, um die ursprünglichen Datensätze mit dem korrekten, standardisierten Format für Telefonnummern und Adressen zu aktualisieren.
Und Sie haben Recht - dieses externe Skript lädt die Daten nicht aus dem Interface Mart in den Raw Vault, da die aktualisierten Datensätze im Quellsystem erst beim nächsten Staging-Vorgang erscheinen und dann in den Raw Vault übernommen werden sollten.
Ich hoffe, das beantwortet Ihre Fragen.
Herzlichen Dank,
Trung Ta