Data Vault 2.0 Definition
Data Vault 2.0 ist ein hybrider Ansatz für EDW-Lösungen der von Dan Linstedt, Mitbegründer und Gesellschafter von Scalefree, in den 1990er Jahren entwickelt wurde.
Als hybride Architektur umfasst sie die besten Aspekte der dritten Normalform und eines Sternschemas. Diese Kombination führt zu einem historisch nachvollziehbaren, detailorientierten, eindeutig verknüpften Satz von normalisierten Tabellen. Alle diese Tabellen dienen der Unterstützung eines oder mehrerer funktionaler Geschäftsbereiche.
Außerdem handelt es sich um einen offenen Standard, der auf drei Säulen beruht:
- Methodik
- Architektur
- Modellierung
mit einem Experten

Was ist Data Vault 2.0?
Darüber hinaus werden die Implementierungsmuster als Untersäule der Methodik betrachtet, die auf die Steigerung der Agilität ausgerichtet ist.
Das Modell Data Vault 2.0 ist daher ausdrücklich auf die Bedürfnisse der heutigen enterprise data warehouses. Erreicht wird dies durch besonders hohe Skalierbarkeit, Flexibilität und Konsistenz. Data Vault 2.0 katapultiert die ursprünglichen Data Vault-Modellierungskonzepte in eine moderne Umgebung.
Obwohl der Ansatz modernisiert wurde, deckt Data Vault 2.0 auch Themen wie Implementierung, Methodik und Architektur ab.
Warum Data Vault 2.0?
Flexibilität
Um einen flexibleren Ansatz zu ermöglichen, kann Data Vault 2.0 mit mehreren Quellsystemen und sich häufig ändernden Beziehungen umgehen, indem der Wartungsaufwand minimiert wird.
Das bedeutet, dass eine Änderung in einem Quellsystem, die neue Attribute erzeugt, einfach durch Hinzufügen eines weiteren Satelliten zum Data Vault-Modell umgesetzt werden kann. Einfach ausgedrückt: Neue und sich ändernde Beziehungen schließen einfach eine Verbindung und erstellen eine andere.
Diese Beispiele zeigen die hohe Flexibilität von Data Vault 2.0.
Skalierbarkeit
Wenn ein Unternehmen wächst, steigen auch die Anforderungen an die Daten.
In einer traditionellen Umgebung würde dies lange Implementierungsprozesse, hohe Kosten und eine umfangreiche Liste von dienstübergreifenden Auswirkungen erfordern.
Mit Data Vault 2.0 können neue Funktionalitäten einfach und schnell hinzugefügt werden, ohne dass dies Auswirkungen auf die nachgelagerten Systeme hat.
Konsistenz
Daten werden immer häufiger für wichtige Geschäftsentscheidungen verwendet.
Um sicherzustellen, dass diesen Daten vertraut werden kann, ist Datenkonsistenz entscheidend.
Zu diesem Zweck ist in Data Vault 2.0 die Datenkonsistenz in das Data Vault-Modell eingebettet. Auf diese Weise ist es möglich, Daten auf konsistente Weise zu erfassen, selbst wenn die Quelldaten oder ihre Lieferung inkonsistent sind.
Und das alles bei gleichzeitiger Möglichkeit, Daten mit Hilfe von Hashwerten parallel zu laden.
Dies ermöglicht einen schnelleren Datenzugriff und verbessert gleichzeitig die Zufriedenheit der Geschäftsanwender.
Aus diesem Grund ebnet die hohe Konsistenz von Data Vault den Weg für den Einsatz von Automatisierungstools zur automatischen Modellierung Ihres Data Vault 2.0-Modells.
Reproduzierbarkeit
Die Methodik von Data Vault folgt dem CMMI-Prinzip.
CMMI ist ein Schulungs- und Bewertungsprogramm zur Prozessverbesserung, das fünf verschiedene Reifegrade eines Unternehmens umfasst.
So kann es sich auf die kontinuierliche Verbesserung der Prozesse auf der Grundlage quantitativer und präskriptiver Analysen konzentrieren.
Das ist auch der Grund, warum Data Vault 2.0 darauf abzielt, den genauen Reifegrad für die Implementierung strukturierter Entwicklungsprozesse zu ermitteln.
Dieser einfache, aber detaillierte Prozess ermöglicht eine leichte Wiederholbarkeit, wenn es darum geht, eine neue Änderung an einem bereits geplanten Prozess vorzunehmen.
Agilität
Eine der Säulen von Data Vault 2.0 ist die Methodik, die mehrere Prinzipien agiler Arbeitsprozesse beinhaltet.
Daher haben Data Vault-Projekte einen kurzen, umfangskontrollierten Release-Zyklus. Normalerweise besteht dieser Zyklus aus einem Produktionsrelease alle zwei bis drei Wochen. Dies ermöglicht es dem Entwicklungsteam, eng mit den Anforderungen des Unternehmens zusammenzuarbeiten, um eine bessere Lösung zu schaffen.
Anpassungsfähigkeit
Ein modernes Geschäftsumfeld ist häufig von häufigen Veränderungen geprägt.
Dabei kann es sich entweder um kleine Änderungen handeln, die sich kaum oder gar nicht auf die Datenstruktur auswirken, oder um große Änderungen, die erhebliche Auswirkungen auf die zugrunde liegende Datenstruktur haben.
Ein guter möglicher Anwendungsfall wäre die Übernahme eines anderen Unternehmens.
Dadurch würde die Notwendigkeit entstehen, komplexe neue Datenquellen zu integrieren, was eine der Hauptstärken von Data Vault ist. Die neuen Quellen würden als Erweiterung des bestehenden Data Vault 2.0-Modells modelliert werden, ohne dass sich das bestehende Modell ändert.
Dadurch wird der Wartungsaufwand auf ein Minimum reduziert.
Prüfbarkeit
Die Arbeit mit Daten erfordert oft detaillierte Informationen über die Herkunft der verarbeiteten Daten. Mit Data Vault 2.0 gibt es verschiedene Methoden, die helfen, den Überblick über Ihre Daten zu behalten.
So sind beispielsweise für jede Zeile, die im Data Warehouse ankommt, ein Ladezeitstempel und eine detaillierte Datensatzquelle erforderlich. Das Data Vault-Modell verfolgt auch alle Änderungen an Ihren Daten, indem es das Ladedatum als Teil des Primärschlüssels des Satelliten verwendet. Durch diese Faktoren wird die Überprüfbarkeit von Data Vault verbessert.
1. Methodik
Der Data Vault 2.0-Standard bietet eine Best Practice für die Projektdurchführung, die so genannte "Data Vault 2.0-Methodik". Sie ist von zentralen Software-Engineering-Standards wie Scrum, Six Sigma usw. abgeleitet und passt diese Standards für den Einsatz im Data Warehousing an.
Sie besteht aus:
- Software Development Life Cycle (SDLC)
- Projektmanagementtechniken aus dem PMI Project Management Body of Knowledge (PMBOK)
- Project Management Professional (PMP)
- Capability Maturity Model Integration (CMMI)
- Total Quality Management (TQM)
- Six Sigma Regeln und Grundsätze
2. Architektur
1 - Staging Layer
Der Staging Layer wird beim Laden von Batch-Daten in das Data Warehouse verwendet.
Sein Hauptzweck besteht darin, die Quelldaten schnell zu extrahieren, so dass die Arbeitslast auf den operativen Systemen verringert werden kann. Beachten Sie, dass der Staging-Bereich die Daten im Gegensatz zu den traditionellen Architekturen nicht aufbewahrt.
2 - Enterprise Data Warehouse Layer
Die unveränderten Daten werden in den Raw Data Vault geladen, der die Data-Warehouse-Schicht des Unternehmens darstellt. Der Zweck des Data Warehouses besteht darin, alle historischen, zeitlich variablen Daten zu speichern. Alle Daten werden in der Granularität gespeichert, die von den Quellsystemen bereitgestellt wird. Die Daten sind nicht flüchtig und jede Änderung im Quellsystem wird von der Data-Vault-Struktur verfolgt.
Nachdem die Daten in das Data Vault-Modell geladen wurden, komplett mit Hubs, Links und Satellites, werden die business rules im Business Vault angewendet. Dieser Prozess findet auf den Daten im raw data vault statt.
Sobald die Geschäftslogik angewendet wurde, werden sowohl der raw data vault als auch der business vault zusammengeführt und in das Geschäftsmodell für die Informationsbereitstellung in den Information Marts umstrukturiert.
Darüber hinaus kann die Data-Warehouse-Schicht des Unternehmens durch optionale Vaults - einen Metrics Vault und einen Operational Vault - erweitert werden. Der Metrics Vault dient der Erfassung und Aufzeichnung von Laufzeitinformationen. Der Operational Vault speichert Daten, die von operativen Systemen in das Data Warehouse eingespeist werden. Alle optionalen Vaults, der Metrics Vault, der Business Vault und der Operational Vault, sind Teil des Data Vault und in die Data Warehouse-Schicht integriert.
3 - Information Delivery Layer
Im Gegensatz zu herkömmlichen Data Warehouses wird auf die Data Warehouse-Schicht der Data Vault 2.0-Architektur nicht direkt von den Endnutzern zugegriffen. Der Grund dafür ist, dass das Ziel des Enterprise Data Warehouse darin besteht, den Endnutzern wertvolle Informationen zur Verfügung zu stellen. Beachten Sie, dass wir für diese Schicht den Begriff "Informationen" anstelle von "Daten" verwenden.
Ferner ist zu beachten, dass die Informationen im Information Mart themenorientiert sind und in aggregierter Form, flach oder breit, für das Reporting aufbereitet, hochgradig indexiert, redundant und qualitätsbereinigt sein können.
Es folgt häufig dem Sternschema und bildet die Grundlage sowohl für relationale Reports als auch für multidimensionale OLAP-Würfel. Weitere Beispiele für Information Marts sind der Error Mart und der Meta Mart. Sie sind der zentrale Ort für Fehler im Data Warehouse bzw. für die Metadaten.
Aufgrund der Plattformunabhängigkeit von Data Vault 2.0 kann NoSQL für jede Data-Warehouse-Schicht verwendet werden, einschließlich der Staging-Schicht, der Enterprise-Data-Warehouse-Schicht und der Information Delivery. Daher kann eine NoSQL-Datenbank als Staging-Area verwendet werden, die Daten in die relationale Data Vault-Schicht laden kann.
4 - hard Business Rules
Jede Regel, die den Inhalt einzelner Felder oder die Granularität nicht verändert. Stattdessen ändert sie nur die Struktur der eingehenden Daten.
5 - Soft Business Rules
Jede Regel, die den Inhalt der Daten verändert, z. B. die Umwandlung von Daten in Informationen.
6 - Information Marts
Jede Struktur, auf die der Endnutzer Zugriff hat und die zur Erstellung von Reports verwendet werden kann.
7 - Raw Data Vault
Die als Hubs, Links und Satellites modellierten Rohdaten sowie der Inhalt dieser Artefakte, die von der Quelle bereitgestellt werden.
8 - Business Vault
Daten, die durch die Business Rules geändert wurden und in DV-Tabellen modelliert sind; spärlich erstellt.
9 - Echtzeitbeladung
Echtzeitdaten werden als ein Strom von Transaktionsdaten geladen.
3. Data Vault Modellierung
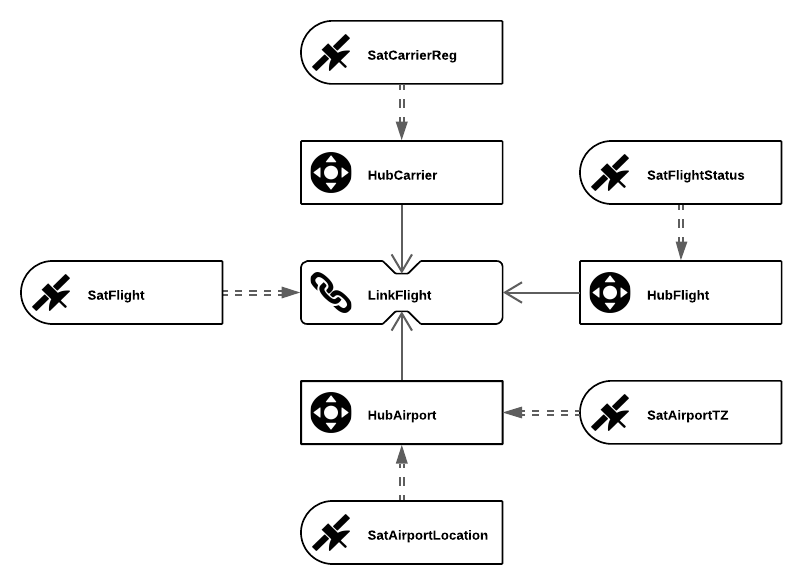
Das Data Vault-Modell basiert auf drei grundlegenden Entitätstypen. Diese Entitäten sind Hubs, Links und Satellites.
Jeder Entitätstyp dient einem bestimmten Zweck: der Hub trennt die Geschäftsschlüssel vom Rest des Modells; der Link speichert Beziehungen zwischen Geschäftsschlüsseln; und Satelliten die Attribute eines Geschäftsschlüssels oder einer Beziehung speichern.
Hubs
Wenn Geschäftsanwender auf Informationen in einem operativen System zugreifen, verwenden sie einen Geschäftsschlüssel, der sich auf ein bestimmtes Geschäftsobjekt bezieht.
Beachten Sie, dass Geschäftsschlüssel eine Rechnungsnummer, eine Fahrzeugidentifikationsnummer oder eine Kundennummer sein können. Manchmal ist eine Kombination von Schlüsseln erforderlich, um ein Objekt eindeutig zu identifizieren.
Die Geschäftsschlüssel sind für das Data Vault-Modell von zentraler Bedeutung. Aus diesem Grund werden sie vom Rest des Modells getrennt gehalten. Diese Trennung wird über Hubs vorgenommen.
Jede Art von Geschäftsschlüssel wird als ein anderer Hub implementiert. Die zentralen Elemente in einem Luftverkehrsszenario (siehe oben) sind Flughäfen (Airport), Fluggesellschaften (Carrier) und Flüge (Flight). Daher werden diese Geschäftsschlüssel als drei verschiedene Hubs modelliert: HubAirport, HubCarrier und HubFlight.
Links
Gleichzeitig ist jedoch kein Geschäftsobjekt vollständig von anderen Geschäftsobjekten getrennt. Stattdessen sind sie durch Verweise auf ihre Geschäftsschlüssel miteinander verbunden. In Data Vault werden diese Beziehungen mit Links modelliert, die zwei oder mehr Hubs miteinander verbinden.
Diese Hub-Link-Konstruktionen repräsentieren typischerweise Einkauf, Produktion, Werbung, Marketing und Verkauf.
Links enthalten die Geschäftsschlüssel für die angeschlossenen Hubs zusammen mit zusätzlichen Metadaten.
Es ist jedoch zu beachten, dass noch keine beschreibenden Attribute modelliert wurden.
In dem vorgestellten Beispiel aus der Luftfahrt wird ein Link verwendet, um die drei Hubs HubAirport, HubCarrier und HubFlight zu verbinden. Dieser Link heißt LinkFlight und stellt einen vollständigen Flug mit all seinen Informationen dar.
Satellites
Ein Data-Vault-Modell mit Hubs und Links allein würde uns nicht genügend Informationen liefern. Das fehlende Element ist der Kontext dieser Geschäftsobjekte und ihrer Verknüpfungen. Bei einer Flugtransaktion könnte dies die Flugzeit des Flugzeugs oder die sicherheitsbedingte Verzögerung eines Flugs sein.
Satelliten fügen dem Data Vault-Modell diese Funktionalität hinzu. Attribute, die entweder zu einem Geschäftsschlüssel eines Hubs oder zu einer Beziehung/Transaktion eines Links gehören. Die Änderung von Attributen wird ebenfalls im Satelliten gespeichert, um die Historie eines Objekts zu verfolgen.
Wie Sie bei HubAirport sehen können, können sich mehrere Satelliten an einem Hub oder einem Link befinden, SatAirportLocation und SatAirportTZ. Gründe für die Verteilung der Attribute sind beispielsweise mehrere oder wechselnde Quellsysteme oder eine unterschiedliche Häufigkeit von Datenänderungen.
Was ist ein Business Vault?
Es werden viele Begriffe verwendet, die oft für Verwirrung sorgen. Um also eine richtige Definition zu geben:
Business Vault = Business Data Vault
und
Raw Vault = Raw Data Vault
und
Raw Data Vault + Business Vault = Data Vault
Im Raw Vault sind also die rohen, ungefilterten Daten aus den Quellsystemen, die auf der Grundlage von Geschäftsschlüsseln in Hubs, Links und Satellites geladen wurden.
Der Business Vault ist eine Erweiterung des Raw Vaults, der ausgewählte Business Rules, Denormalisierungen, Berechnungen und andere Funktionen zur Unterstützung von Abfragen anwendet.
Dies geschieht, um den Endnutzern Zugang und Berichterstattung zu erleichtern.
Ein Business Vault wird in DV-Tabellen modelliert, wie z.B. Hubs, Links und Satellites, aber er ist keine vollständige Kopie aller Objekte im Raw Vault. Er enthält nur Strukturen, die einen gewissen Geschäftswert haben.
Die Daten werden so umgewandelt, dass Regeln oder Funktionen angewandt werden, die für die meisten Geschäftsanwender nützlich sind, anstatt sie wiederholt in mehrere Marts anzuwenden. Dazu gehören Dinge wie Datenbereinigung, Datenqualität, Buchhaltungsregeln oder wiederholbare Berechnungen.
In Data Vault 2.0 enthält der Business Vault auch einige spezielle Entitäten, die bei der Erstellung effizienterer Abfragen des Raw Vault helfen. Diese sind Point-in-Time- und Bridge-Tables.

Marc Winkelmann
Managing Consultant
Telefon: +49 511 87989342
Mobil: +49 151 22413517
Planen Sie Ihre
Kostenlose Erstberatung