Hash Keys in DV2.0
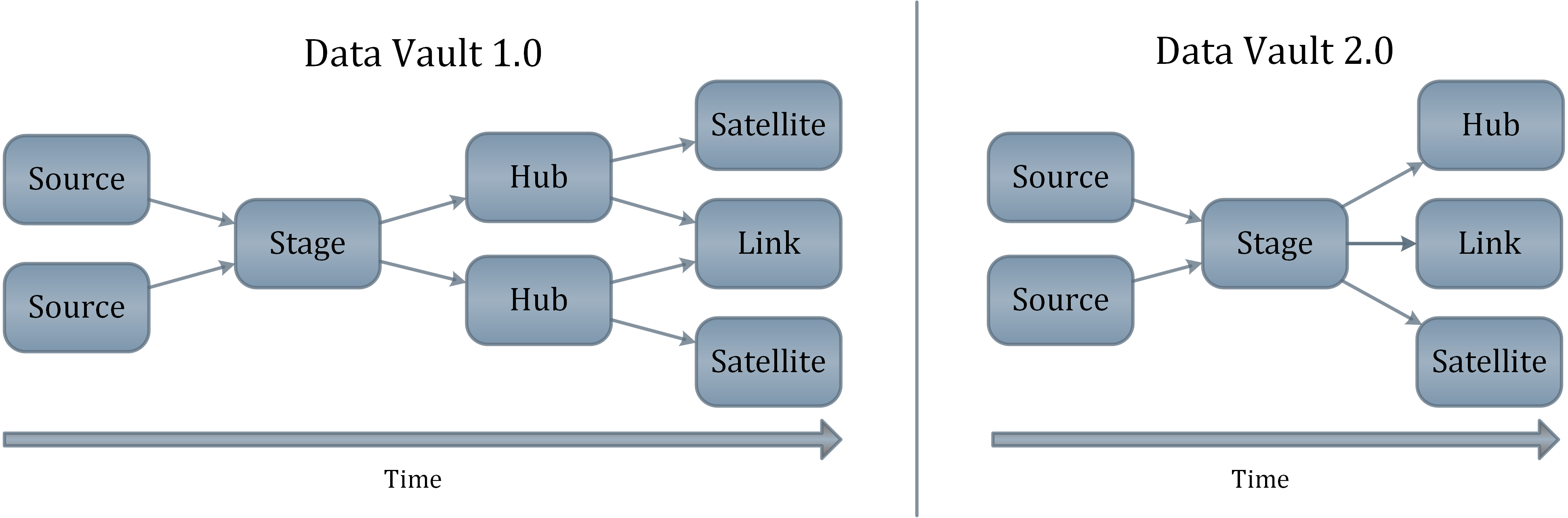
Data Vault 2.0 führt Hash-Schlüssel ein, um das herkömmliche Data Vault-Modell zu verbessern, was für data warehousing mehrere Vorteile mit sich bringt. Hash-Schlüssel beschleunigen nicht nur den Ladevorgang, sondern sorgen auch dafür, dass das data warehouse des Unternehmens mehrere Umgebungen überspannen kann: lokale Datenbanken, Hadoop-Cluster und Cloud-Speicher.
Betrachten wir zunächst den Leistungsgewinn: Um die Ladevorgänge zu steigern, müssen Abhängigkeiten im Ladeprozess minimiert oder sogar eliminiert werden. In Data Vault 1.0 wurden Sequenznummern verwendet, um eine Geschäftseinheit zu identifizieren, und das hatte zur Folge, dass es beim Ladevorgang zu Abhängigkeiten kam.
Diese Abhängigkeiten haben den Ladevorgang verlangsamt, was insbesondere bei Echtzeit-Feeds ein Problem ist. Hubs mussten zuerst geladen werden, bevor der Ladevorgang der Satelliten und Links beginnen konnte. Es ist beabsichtigt, diese Abhängigkeiten durch die Verwendung von Hash-Schlüsseln anstelle von Sequenznummern als Primärschlüssel aufzulösen.
Business Keys vs. Hash Keys
Vorab können Geschäftsschlüssel eine laufende Nummer sein, die von einem einzigen Quellsystem erstellt wird, z. B. die Kundennummer.
Geschäftsschlüssel können aber auch ein zusammengesetzter Schlüssel zur eindeutigen Identifizierung einer Geschäftseinheit sein, z. B. wird ein Flug in der Luftfahrtindustrie durch die Flugnummer und das Datum identifiziert, da die Flugnummer jeden Tag wiederverwendet wird.
Allgemein: Ein Geschäftsschlüssel ist der natürliche Schlüssel, der von einem Unternehmen zur Identifizierung eines Geschäftsobjekts verwendet wird.
Während der Verwendung des Geschäftsschlüssel in Data Vault eine Option sein könnte, ist es eigentlich eine langsame Option, die viel Speicherplatz benötigt (sogar mehr als Hash-Schlüssel).
Insbesondere in Links und ihren abhängigen Satelliten sind viele zusammengesetzte Geschäftsschlüssel erforderlich, um die Beziehung oder den Vorgang/das Ereignis in einem Link zu identifizieren - und im Satelliten zu beschreiben.
Dies würde viel Speicherplatz erfordern und den Ladevorgang verlangsamen, da nicht alle Datenbank-Engines sind in der Lage, effiziente Joins mit Geschäftsschlüsseln variabler Länge durchzuführen.
Andererseits würden wir zu viele Spalten in der Verknüpfung haben, da jeder Business Key Teil der Verknüpfung sein muss.
Das Problem an dieser Stelle ist, dass wir auch unterschiedliche Datentypen mit unterschiedlichen Längen in den Verbindungen haben. Dieses Problem wird dadurch verschärft, dass auch die Geschäftsschlüssel in die Satelliten repliziert werden müssen.
Um eine konsistente Join-Leistung zu gewährleisten, besteht die Lösung darin, die Geschäftsschlüssel in einem einzigen Spaltenwert zu kombinieren, indem Hash-Funktionen zur Berechnung einer eindeutigen Darstellung eines Geschäftsobjekts verwendet werden.
Massiv parallele Verarbeitung (MPP)
Aufgrund der Unabhängigkeit beim Ladevorgang von Hubs, Links und Satelliten ist es möglich, dies alles parallel zu tun.
Die Idee besteht darin, die Tatsache zu nutzen, dass ein Hash-Schlüssel von einem Geschäftsschlüssel oder einer Kombination von Geschäftsschlüsseln abgeleitet wird, ohne dass ein Nachschlagen in der übergeordneten Tabelle erforderlich ist.
Anstatt die Sequenz eines Geschäftsschlüssels in einem Hub nachzuschlagen, bevor der Geschäftsschlüssel im Satellit beschrieben wird, können wir daher einfach den Hash-Schlüssel des Geschäftsschlüssels berechnen.
Die (korrekte) Implementierung der Hash-Funktion gewährleistet, dass derselbe semantische Geschäftsschlüssel zu genau demselben Hash-Schlüssel führt, unabhängig von der geladenen Zielentität.
Hash Keys als Teil von Apache™ Hadoop® Datensätze
Ohne Hashing erfordert die Last in HadoopⓇ oder NoSQL eine Suche nach der Hub- oder Link-Sequenz im relationalen System, bevor die Daten eingefügt oder angehängt werden können.
Hashing statt Sequenzierung bedeutet, dass wir komplette 100% parallele Operationen in alle Hubs, alle Links, alle Satelliten laden und alle Hadoop anreichern könnenⓇ oder NoSQL-basierte Dokumente parallel zu verarbeiten.
Es ermöglicht auch die Verbindung über mehrere heterogene Plattformen hinweg - von Teradata Database bis zu ApacheTM HadoopⓇ zum Beispiel.
Hash-Differenz
Die Hash-Differenz Spalte gilt für die Satelliten. Der Ansatz ist derselbe wie bei den Geschäftsschlüsseln, nur dass hier alle beschreibende Daten wird gehasht.
Das reduziert den Aufwand beim Hochladen, da nur eine Spalte nachgeschlagen werden muss. Der Satelliten-Upload-Prozess prüft erstens, ob der Hash-Schlüssel bereits im Satelliten vorhanden ist, und zweitens, ob es Unterschiede zwischen den Hash-Differenzwerten gibt.
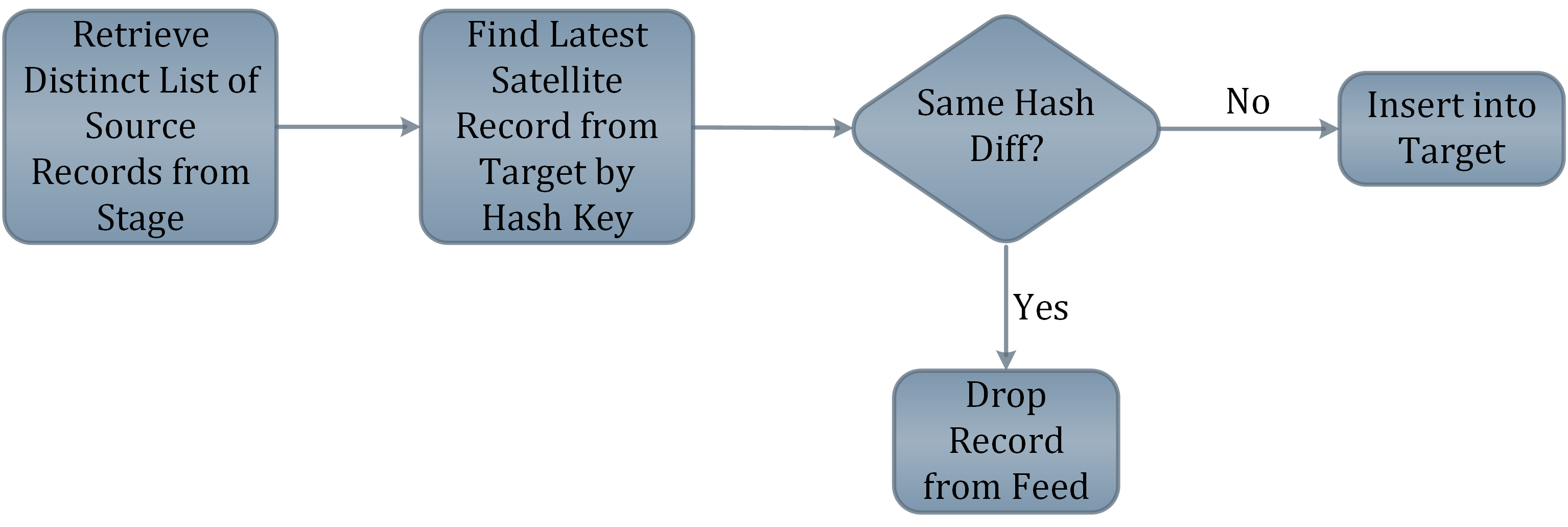
Die obige Abbildung zeigt den Prozess, wenn das Quellsystem Ihnen eine vollständige Datenlieferung sendet.
Der Punkt, an dem die Werte gehasht werden sollen, sollte auf dem Weg in den Bereitstellungsraum liegen, denn An diesem Punkt ist Zeit, um auf "doppelte Kollisionen" zu prüfen und Hashing-Probleme zu behandeln, bevor mit den Daten in der Data Vault.
Welche Hash-Funktion soll verwendet werden?
Es gibt viele Hash-Funktionen zur Auswahl: MD5, MD6, SHA-1, SHA-2 und einige mehr.
Wir empfehlen in den meisten Fällen die Verwendung des MD5-Algorithmus mit einer Länge von 128 Bit, da Sie ist auf den meisten Plattformen allgegenwärtig und hat eine recht geringe Wahrscheinlichkeit von Doppelkollisionen bei einem akzeptablen Speicherbedarf.
Ein weiterer Vorteil des Hashings ist, dass es dass die Hashes die gleiche Länge haben und vom gleichen Datentyp sind, woraus sich eine Leistungsverbesserung ergibt.
Außerdem werden Hash-Werte generiert, so dass sie nie verloren gehen und wiederhergestellt werden können.
Kollision
Das Hashing birgt ein sehr kleines Risiko: die Kollision. Das bedeutet, dass zwei verschiedene Daten denselben Hash-Wert erhalten.
Aber das Risiko ist zum Beispiel sehr gering: Bei einer Datenbank mit mehr als einer Billion Hash-Werten ist die Wahrscheinlichkeit, dass es zu einer Kollision kommt, so groß wie die Wahrscheinlichkeit, dass ein Meteor in Ihrem Rechenzentrum landet.
Zusammenfassung
Hash Keys sind für das Data Vault nicht zwingend erforderlich, werden aber dringend empfohlen. Die Vorteile von
- Massiv parallele Verarbeitung (MPP),
- Leistung beim Laden von Daten,
- Konsistenz und
- Prüfbarkeit
sind unverzichtbar und können nicht mit Sequenzen oder Business Keys erreicht werden.
Hash-Schlüssel sind kein Allheilmittel... aber sie bieten (viel) mehr Vorteile als Nachteile (Speicherung).
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.



Wir planen, eine POC auf data vault für ein Datamart-Projekt durchzuführen. Wir verwenden derzeit SQL Server 2016 und laut den Microsoft-Dokumenten ist die MD5-Funktion veraltet. Können Sie uns bitte zeigen, wie wir dieses Problem umgehen können?
Eine Möglichkeit besteht darin, auf eine Kompatibilitätsstufe unter 130 zu wechseln. Die andere Möglichkeit besteht darin, den md5-Hash-Algorithmus als eigene Datenbankfunktion zu erstellen: http://binaryworld.net/main/CodeDetail.aspx?CodeId=3600#copy.
Mit freundlichen Grüßen,
Ihr Scalefree-Team
Interessant ist, dass die Datenquellen nicht in die Hashing-Berechnung einbezogen werden. Nehmen wir an, wir haben zwei Buchhaltungssysteme: SAP und Quickbooks. Wenn beide Systeme dieselbe Rechnungsnummer haben, um verschiedene Rechnungen zu repräsentieren, würden wir dann nicht einen unterschiedlichen Hash-Wert für diese haben wollen? Ich vermute, man könnte zwei verschiedene Sätze von Verknüpfungen mit dem Hub für verschiedene Nummern verwenden, aber das klingt, als würden die Abfragen hier komplex werden. Was ist die beste Praxis für Situationen wie diese?
Hallo Brad,
Sie haben Recht - wenn sich Geschäftsschlüssel über mehrere Quellsysteme hinweg überschneiden, fügen wir solche Quellkennungen hinzu.
Aber nur in diesem Fall - wenn die gleichen Geschäftsschlüssel das semantisch gleiche Geschäftsobjekt identifizieren, sollte der Hub die Daten tatsächlich systemübergreifend integrieren. In diesem Fall würde der Quellbezeichner die Integration verhindern.
Ich hoffe, das hilft,
Mike
Nicht notwendig, da der Kontext in einem separaten Satelliten gespeichert wird. Das Hinzufügen eines Quellenindikators in den Hashkey macht ihn quellenspezifischer und komplexer