
Innerhalb einer hybride data warehouse-ArchitekturWie in der Data Vault 2.0-Bootcamp-Schulung beschrieben, wird ein Data Lake als Ersatz für einen relationalen Staging-Bereich verwendet. Um die Vorteile dieser Architektur voll auszuschöpfen, muss die Datensee ist am besten so organisiert, dass ein effizienter Zugriff innerhalb eines persistenten Staging Area-Musters und eine bessere Datenvirtualisierung möglich ist.
Der Data Lake in einer hybriden Data Vault-Architektur
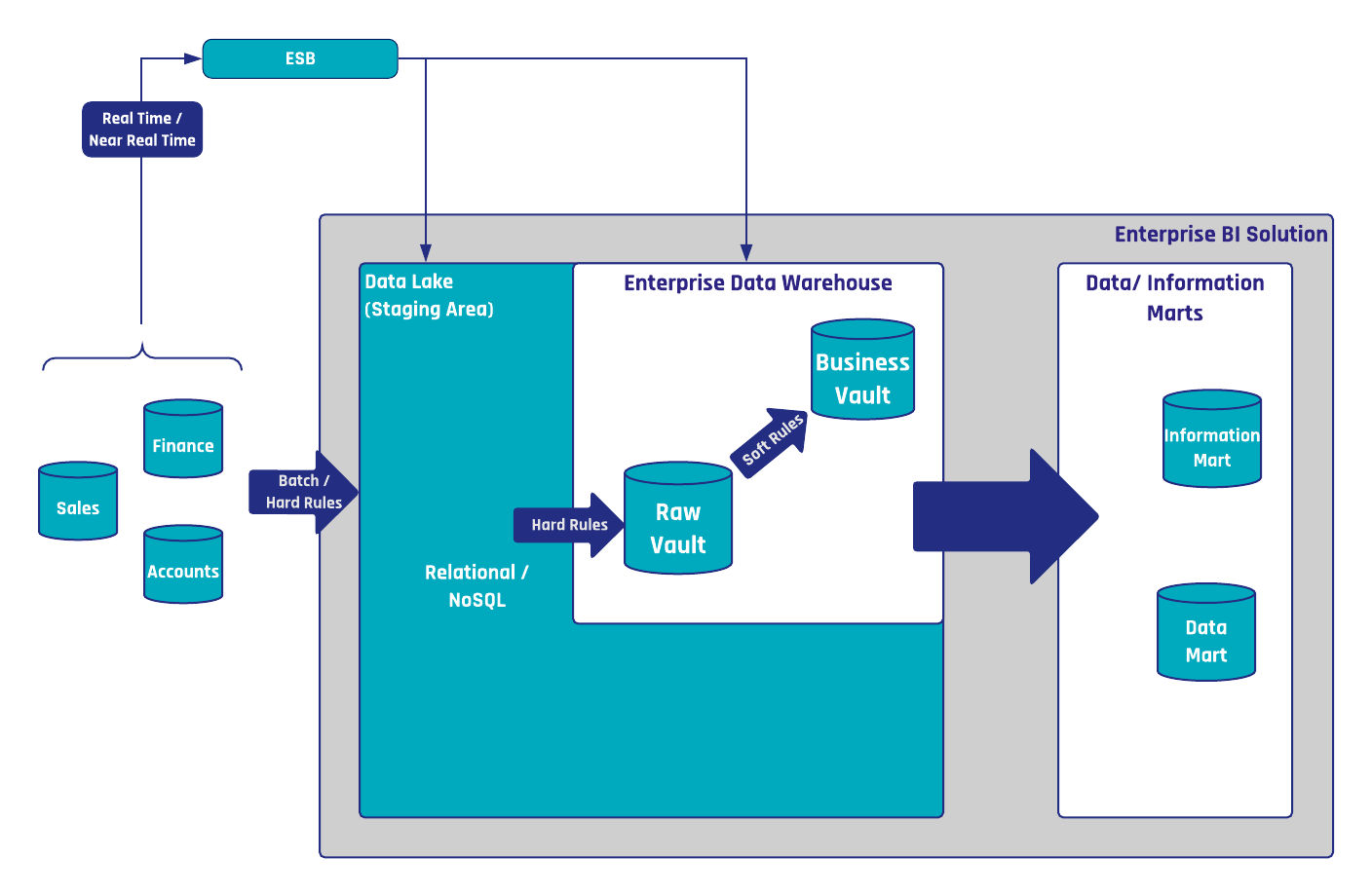
Abbildung 1: Der Data Lake in einer hybriden Data Vault-Architektur
Die Datenseewie in Abbildung 1 dargestellt, wird innerhalb der hybriden Architektur als persistente Staging Area (PSA) verwendet. Dies unterscheidet sich von der relationalen Bereitstellung, bei der ein persistenter oder transienter Bereitstellungsbereich (TSA) verwendet wird. Ein TSA hat den Vorteil, dass der Aufwand für die Datenverwaltung reduziert wird: Ändert sich z.B. die Quellstruktur, muss die relationale Stufentabelle angepasst werden. Wenn die Stufentabelle leer ist, entfällt also die Datenpflege. Wird jedoch eine PSA mit relationaler Technik erstellt, müssen die historischen Daten innerhalb der Tabelle an die neue Struktur angepasst werden.
Dies unterscheidet sich von einem Staging-Bereich in einem Data Lake, da bei einer Änderung der Quelldaten die historischen Daten in anderen Dateien nicht betroffen sind. Daher ist keine Datenverwaltung erforderlich, und in diesem Sinne werden PSAs auf Data Lake gegenüber TSAs bevorzugt.
Eine klare Begründung für diese Aussage wird wie folgt dargestellt:
- Es dient nicht nur dem data warehouse-Team bei seinen Ladevorgängen, sondern auch den Datenwissenschaftlern, die direkt auf den Data Lake zugreifen und dabei möglicherweise die EDW.
- Full Loads können vom data warehouse-Team verwendet werden, um neue Raw Data Vault-Entitäten mit historischen Daten zu initialisieren.
- Dieses Muster könnte verwendet werden, um das data warehouse auf dem Data Lake zu virtualisieren.
STRUKTURIERUNG DES DATA LAKE FÜR EINEN EFFIZIENTEN DATENZUGRIFF
Je nachdem, wie die Daten im Data Lake organisiert sind, kann der Zugriff auf die Daten nachgelagert sein oder nicht. Während es immer einfach ist, Daten in den Data Lake zu verlagern, ist es in der Regel eine Herausforderung, die Daten effizient abzurufen, damit sie von der inkrementellen oder anfänglichen EDW-Last und von Data Scientists für unabhängige Abfragen verwendet werden können.
In diesem Sinne ist ein effizienter Data Lake funktional strukturiert, was im Wesentlichen bedeutet, dass die Metadaten der Quellsysteme die Organisation des Data Lake bestimmen.
Unserer Erfahrung nach ist es immer besser, die folgende Ordnerstruktur in einem Data Lake zu haben:
- Quellsystem: Der erste Ordner in einem Data Lake ist der Typ des Quellsystems (z. B. Oracle).
- Verbindung: Das typische Unternehmen hat mehrere Verbindungen desselben Quellsystems, z. B. mehrere Oracle-Datenbanken, die in den Data Lake geladen werden müssen. Es ist jedoch darauf zu achten, dass der Bezeichner für jede Verbindung eindeutig ist. Dies kann durch eine Nummer, einen Code oder eine Abkürzung geschehen.
- Schemaname: Einige Quellsysteme bieten mehrere Schemata oder Datenbanken pro Verbindung. Diese Hierarchie sollte sich in diesem Bereich widerspiegeln und kann tatsächlich aus mehreren Ordnern bestehen.
- Name der Sammlung/Beziehung: Dies ist der Name der Entität oder der REST-Sammlung, die abgefragt werden soll.
- Zeitstempel des Ladedatums: Der LDTS gibt den Zeitstempel des Ladedatums der Charge an.
Innerhalb des letzten Ordners (Zeitstempel des Ladedatums) ist es oft von Vorteil, die Daten in mehreren Buckets zu speichern (anstelle einer großen Datei oder sehr kleiner Dateien). Dies verbessert im Allgemeinen die Leistung von Abfragetools, insbesondere wenn die Daten in einem verteilten Dateisystem gespeichert sind. Es wird auch empfohlen, Avro-Dateien zu verwenden, die in der Regel mit Snappy komprimiert werden. Wenn Downstream-Tools dieses Dateiformat nicht unterstützen, kann stattdessen gunzipped JSON verwendet werden.
Die Datei selbst sollte zusätzlich zu den Quellattributen die folgenden Attribute aufweisen:
- Zeitstempel des Ladedatums: Viele Tools können den Zeitstempel des Ladedatums nicht aus dem Schlüssel der Datei im Data Lake abrufen.
- Unter-Sequenznummer
Diese Struktur kann mit mehreren Abfrage-Engines (z. B. Apache Drill, Impala, Hive usw.) verwendet werden und hat sich in diesen Szenarien bewährt.
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Um die Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio zu unterstützen, wurde eine Schablone implementiert, die zum Zeichnen von Data Vault-Modellen verwendet werden kann. Die Schablone ist erhältlich bei www.visualdatavault.com.



Hallo, sehr interessanter Artikel. Empfehlen Sie Bucketing auf Business Key Spalten?