Geschäftsanwender erwarten von ihren data warehouse-Systemen, dass sie immer mehr Daten laden und aufbereiten, was die Vielfalt, das Volumen und die Geschwindigkeit der Daten betrifft. Auch die Arbeitsbelastung typischer data warehouse-Umgebungen nimmt immer mehr zu, insbesondere wenn die ursprüngliche Version des Warehouse bei den ersten Anwendern ein Erfolg geworden ist. Skalierbarkeit hat also mehrere Dimensionen. Letzten Monat sprachen wir über Satellitesdie im Hinblick auf die Skalierbarkeit eine wichtige Rolle spielen. Wir erklären nun, wie man strukturierte und unstrukturierte Daten mit einer hybriden Architektur kombinieren kann.
ARCHITEKTUR DES LOGISCHEN DATENTRESORS 2.0
Die Data Vault 2.0-Architektur basiert auf drei Schichten: dem Staging-Bereich, in dem die Rohdaten aus den Quellsystemen gesammelt werden, der data warehouse-Schicht des Unternehmens, die als Data Vault 2.0-Modell modelliert ist, und der Informationsbereitstellungsschicht mit Informationskataloge wie Sternschemata und andere Strukturen. Die Architektur unterstützt sowohl das Batch-Laden von Quellsystemen als auch das Laden in Echtzeit aus dem Enterprise Service Bus (ESB) oder einer anderen serviceorientierten Architektur (SOA).
Das folgende Diagramm zeigt die grundlegende logische Data Vault 2.0-Architektur:
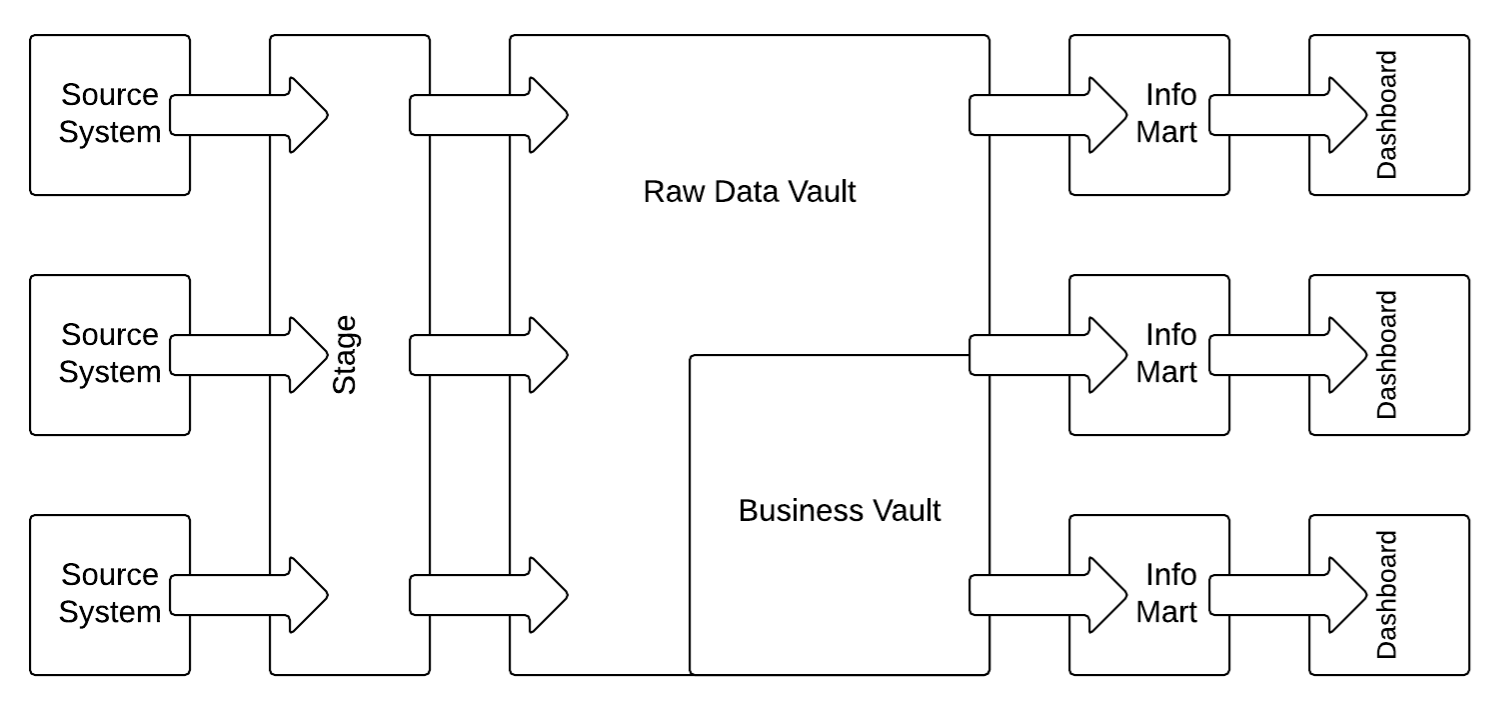
In diesem Fall werden die strukturierten Daten aus den Quellsystemen zunächst in den Staging-Bereich geladen, um die Betriebs-/Leistungsbelastung durch die operativen Quellsysteme zu verringern. Sie werden dann unverändert in das Raw Data Vault geladen, das die Enterprise Data Warehouse-Schicht darstellt. Nachdem die Daten in dieses Data Vault-Modell (mit Hubs, Links und Satelliten) geladen wurden, werden die Geschäftsregeln im Business Vault auf die Daten im Raw Data Vault angewendet. Sobald die Geschäftslogik angewendet wurde, werden sowohl das Raw Data Vault als auch das Business Vault zusammengeführt und in das Geschäftsmodell für die Informationsbereitstellung in den Information Marts umstrukturiert. Der Geschäftsanwender verwendet Dashboard-Anwendungen (oder Berichtsanwendungen) für den Zugriff auf die Informationen in den Information Marts.
Die Architektur erlaubt es, die Geschäftsregeln im Business Vault mit einer Mischung aus verschiedenen Technologien zu implementieren, wie z.B. SQL-basierte Virtualisierung (typischerweise unter Verwendung von SQL-Views) und externe Tools, wie z.B. Business Rule Management Systeme (BRMS).
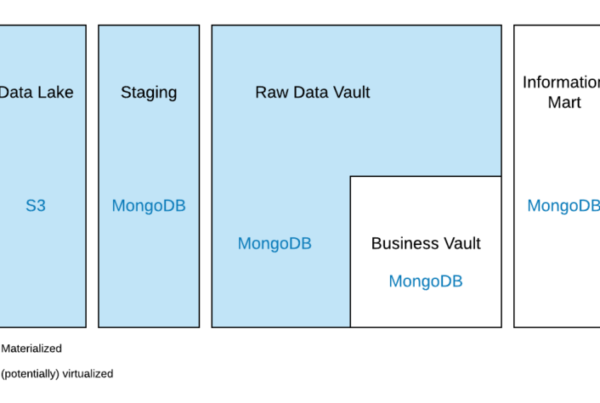
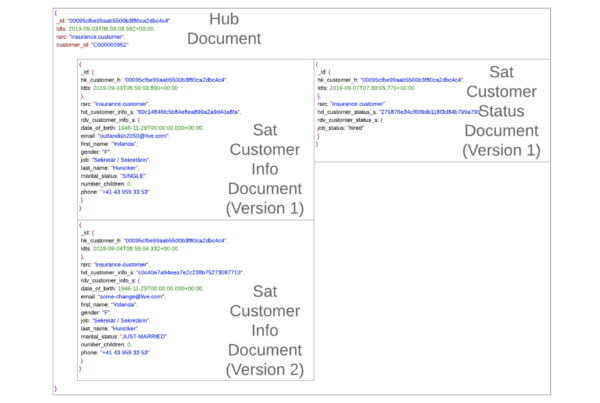
Es ist aber auch möglich, unstrukturierte NoSQL-Datenbanksysteme in diese Architektur zu integrieren. Aufgrund der Plattformunabhängigkeit von Data Vault 2.0 kann NoSQL für jede data warehouse-Schicht verwendet werden, einschließlich der Stage Area, der Enterprise data warehouse-Schicht und der Informationsbereitstellung. Daher könnte die NoSQL-Datenbank als Staging Area verwendet werden und Daten in die relationale Data Vault-Schicht laden. Sie könnte aber auch in beide Richtungen in die Data Vault-Schicht integriert werden, und zwar über eine gehashter Business Key. In diesem Fall würde es sich um eine hybride Lösung handeln, und die Information Marts würden Daten aus beiden Umgebungen nutzen.
HYBRIDE ARCHITEKTUR
Die Standard-Data Vault 2.0-Architektur in Abbildung 1 konzentriert sich auf strukturierte Daten. Da es sich bei immer mehr Unternehmensdaten um halbstrukturierte oder unstrukturierte Daten handelt, ist die empfohlene Best Practice für eine neue Unternehmens-data warehouse eine hybride Architektur auf der Grundlage eines Hadoop-Clusters, wie in der nächsten Abbildung dargestellt:
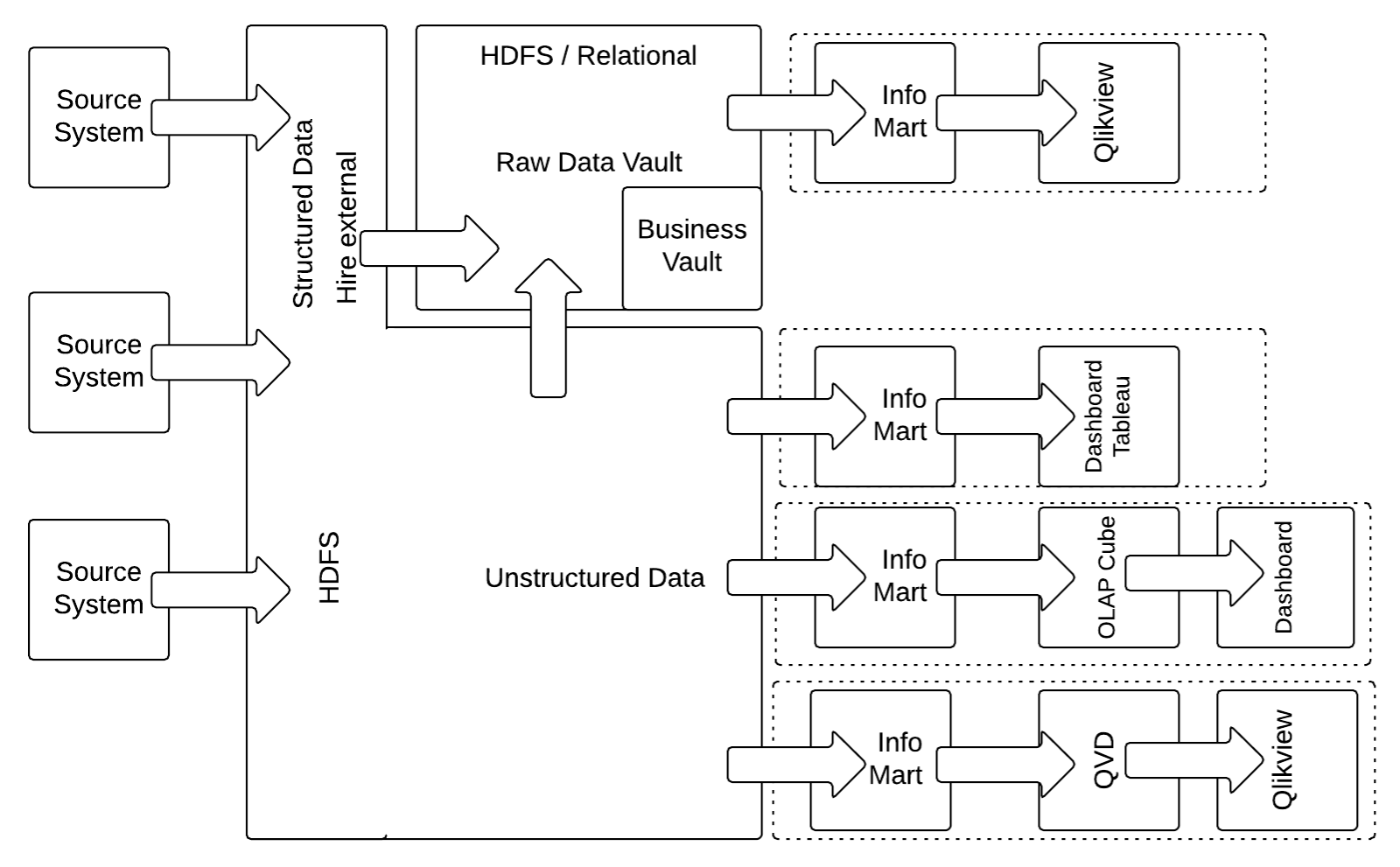
Bei dieser Änderung der Architektur aus dem vorherigen Abschnitt wird der relationale Staging-Bereich durch einen HDFS-basierten Staging-Bereich ersetzt, der alle unstrukturierten und strukturierten Daten erfasst. Während die Erfassung strukturierter Daten im HDFS auf den ersten Blick als Overhead erscheint, reduziert diese Strategie tatsächlich die Belastung des Quellsystems, indem sie sicherstellt, dass die Quelldaten immer extrahiert werden, unabhängig von strukturellen Änderungen. Die Daten werden dann mit Apache Drill, Hive External oder ähnlichen Technologien extrahiert.
Es ist auch möglich, das Raw Data Vault und den Business Vault (die strukturierten Daten im Data Vault-Modell) auf Bienenstock Intern.
Wie Sie Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.