Was sind Bridge Tables?
Bridge Tables sind spezielle Entitäten innerhalb von Data Vault, die die Abfrageleistung auf dem Weg aus dem Data Vault heraus verbessern. Diese Entitäten werden zwischen dem Data Vault und dem Information Delivery Layer platziert und sind für Fälle erforderlich, in denen viele Joins und Aggregationen auf dem Raw Data Vault ausgeführt werden, was Leistungsprobleme verursacht.
Dies geschieht häufig bei der Gestaltung der virtualisierten Faktentabellen in den Informations- und Data Marts. Um die erforderliche Granularität in den Faktentabellen zu erreichen, ohne die Abfragezeit zu erhöhen, kommen Bridge Tables ins Spiel. Bridge Tables gehören zum Business Vault und haben den Zweck, die Leistung zu verbessern, ähnlich wie die PIT-Tabelle die bereits in einem früheren Newsletter behandelt wurde.
Bridge Tables sind ein Mittel zur Erreichung der Ziele, da sie die im Informationsbereitstellungsprozess häufig erforderliche Kornverschiebung realisieren. Bevor wir uns jedoch näher mit den Besonderheiten der Verwendung von Bridge Tables für die Leistungsoptimierung befassen, ist es wichtig, zunächst die Granularität innerhalb eines Data Warehouses zu definieren.
Granularität definieren im Data Warehousing
Die Granularität innerhalb eines dimensionalen Modells ist die für jede Tabelle verfügbare Detailstufe. So wird der Detaillierungsgrad einer Faktentabelle durch die Anzahl der zugehörigen Dimensionen definiert. Grundsätzlich gibt es drei verschiedene Arten von Granularitäten für Faktenentitäten innerhalb eines dimensionalen Modells.
Die erste ist die Faktentabelle der Transaktion, die einem Messereignis zu einem bestimmten Zeitpunkt in Raum und Zeit entspricht. Die Faktentabellen enthalten einen Fremdschlüssel für jede zugehörige Dimension und optional genaue Zeitstempel sowie degenerierte Dimensionsschlüssel. Es wird deutlich, dass die Struktur der Transaktionstabelle die Struktur der Transaktion selbst ist.
Die zweite ist die Faktentabelle des periodischen Schnappschusses. Die periodische Momentaufnahme ist eine Standardperiode, da sie Messereignisse über einen bestimmten Zeitraum zusammenfasst, der manchmal ein Tag, eine Woche usw. sein kann. Sie wird jedoch häufiger zur Erfassung von Lagerdaten verwendet, z. B. von Produktständen pro Tag. Ein Schnappschuss der Produktfüllstände wird zum Beispiel täglich erstellt, daher der Name.
Drittens: Akkumulierte Snapshot Faktentabellen ähneln in ihrer Art den periodischen Snapshot-Tabellen. Im Gegensatz zur Meldung der Daten innerhalb eines bestimmten Zeitrahmens werden jedoch nur die Abweichungen nach dem ersten Snapshot gemeldet. In einer Faktenentität, die die Lagerbestände beschreibt, würde beispielsweise die erste Ladung aller Produkte im ersten Snapshot enthalten sein. Nach dieser ersten Momentaufnahme würden in den nachfolgenden Momentaufnahmen nur noch die Deltas, die der ein- und ausgehenden Produkte, zu finden sein. Um die aktuellen Lagerbestände eines bestimmten Tages zu ermitteln, müssten also alle Daten bis zu diesem Tag aggregiert werden.
Vergleich mit Data Vault 2.0
Innerhalb von Data Vault enthalten rohe Data Vault-Link-Entities immer die feinstmögliche Körnung, nämlich die von der Quelle kommende. Dies ist darauf zurückzuführen, dass der Raw Data Vault die ursprüngliche Granularität des Quellsystems ohne die beim Laden der Daten vorgenommenen Aggregationen erfasst. Innerhalb der Informationslieferung gibt es oft eine Zielgranularität, die durch Anforderungen des Unternehmens definiert ist. In vielen Fällen ist diese Zielgranularität nicht direkt im Data Vault-Modell zu finden. Daher muss diese Granularität von der Granularität des Data Vault-Modells abgeleitet werden.
Bridge Tables fungieren als übergeordnete faktenlose Faktentabelle und enthalten Hash-Schlüssel von den Knotenpunkten und Verbindungen, die sie überspannen. Eine weitere Leistungsverbesserung kann erreicht werden, indem ressourcenintensive Berechnungen in die Bridge Tables verlagert werden. Dies ist besonders wichtig, wenn virtuelle Information Marts auf dem Data Vault erstellt werden, da diese einige Berechnungen erfordern, die den Zugriff auf die virtualisierten Information Mart Entitäten verlangsamen. Mit Bridge Tables kann die Abfrageleistung drastisch verbessert werden. Bridge Tables müssen nicht die gleiche Körnung haben wie die Links, die sie abdecken. In diesen Fällen kann die Bridge Table aggregierte Werte enthalten, die der Struktur hinzugefügt und mit GROUP BY-Anweisungen geladen werden. Die resultierende Bridge Table hat eine höhere Granularität als die in der Tabelle enthaltenen Links.
Gängige Geschäftsbeispiele für eine Granularitätsveränderung in einer Transaktionsfaktentabelle sind Rechnungen. In dem gegebenen Beispiel benötigt der Business User einen Information Mart, der Rechnungen in der Faktentabelle enthält. In den meisten Fällen bestehen Rechnungen aus Einzelposten (bekannt als Dependent Child Key) und diese Einzelposten würden in der Raw Data Vault gespeichert werden, was zu einer feineren Granularität als in der Zielfaktentabelle führt. Um jedoch den gewünschten Detaillierungsgrad zu erreichen, müssen die Einzelposten zu Rechnungen aggregiert werden.
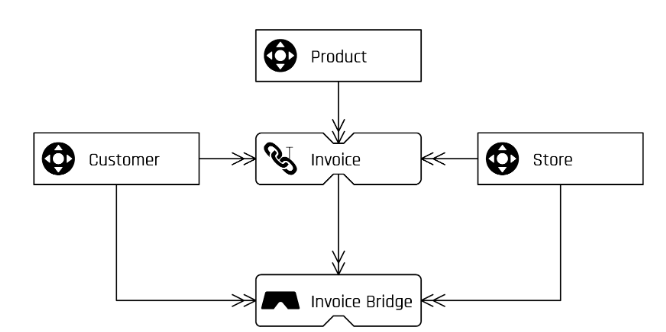
Abbildung 1: Modell Data Vault - Bridge Table
Hier ist der Non-Historized Link sehr hilfreich. Als Faktentabelle einer Transaktion kann typischerweise aus den nicht-historisierten Verknüpfungen abgeleitet werden. Wenn sie die ursprüngliche Granularität der Transaktion speichern und wenn es der Ziel-Granularität entspricht, sind keine weiteren Aggregationen erforderlich. In unserem Beispiel der Rechnungen wird eine höhere Granularität für die Transaktionsfaktentabelle benötigt. Um eine bessere Leistung zu erhalten, wäre eine Bridge Table erforderlich, die die Änderung der Granularität realisiert.
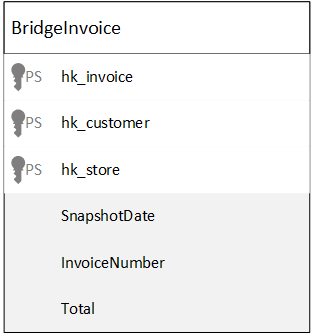
Abbildung 2: Aufbau einer Bridge Table

Tabelle 1: Bridge Table-Informationen
Die Granularität der abgebildeten Bridge Table wird durch die Hub-Referenzen definiert. Zusätzlich erhält die Bridge Table Link-Hash-Keys und mit diesen können Link-Satelliten von der Brücke aus verbunden werden, um auf beschreibende Attribute zuzugreifen. Zusätzliche Attribute zur Messung, speichern die Ergebnisse von Aggregationen. Das letzte Attribut der Bridge Table ist das Snapshot-Datum, das durch das Ladeverfahren hinzugefügt wird. In einigen Fällen können die Snapshot-Daten Teil des Primärschlüssels sein, z. B. bei der kumulativen Umsatzverfolgung. In diesem Fall werden die Verkäufe pro Kunde, pro Filiale und pro (Snapshot-)Tag verfolgt. Das folgende Beispiel zeigt ein Beispiel für eine Bridge-Ladung.
SELECT
hk_invoice,
hk_Kunde,
hk_store,
? als SnapshotDate,
RechnungsNummer,
SUMME(Gesamt)
FROM Link_Rechnung inv
WO NICHT VORHANDEN (
SELECT
1
FROM
DataVault.biz.BridgeInvoice tgt
WHERE
inv.hk_invoice = tgt.hk_invoice AND
inv.hk_Kunde = tgt.hk_Kunde AND
inv.hk_store = tgt.hk_store AND
inv.SnapshotDate = tgt.SnapshotDate
)
GROUP BY hk_invoice, hk_customer, hk_store,SnapshotDate,InvoiceNumber;
'?' ist ein Parameter, der auf das Snapshot-Datum gesetzt wird. Zum Beispiel auf 6 Uhr morgens bei einer täglichen Brückenlast.
Schlussfolgerung
In diesem Artikel wird eine Data Vault-Entität vorgestellt, die für Granularitätsänderungen im Rahmen der Informationsbereitstellung von wesentlicher Bedeutung ist. Mit Bridge Tables können Änderungen der GRanularität realisiert werden, um die Leistung für die erforderlichen Aggregationen und Join-Operationen zu steigern. Im Vorangegangenen wurden verschiedene Granularitäts-Definitionen für Faktentabellen behandelt und die transaktionale Faktentabelle ausführlicher besprochen.
Das Geschäftsbeispiel hat gezeigt, wie eine solche Tabelle aussehen wird und wie man sie aufbaut. Da es nach Kimball noch zwei weitere Definitionen von "grain" für Faktentabellen gibt, wird in einem späteren Artikel erörtert, wie die periodischen Snapshot-Faktentabellen und die akkumulierenden Snapshot-Faktentabellen grain sind.
- Marc Winkelmann (Scalefree)
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.




Das Beispiel ist schlecht gewählt, da jede Dimensional Mart den Faktor Order_Line enthalten sollte.
Wirklich? Was ist mit der Tabelle der Benutzerbeschwerden? 😉
Ich denke, Ihre Abfrage ist falsch. Group by sollte alle Schlüssel enthalten, die in der Select-Klausel enthalten sind. Richtig? Aber das ist nicht meine Frage. Meine Frage ist, ob es bei der Erstellung einer Aggregatbrücke Regeln dafür gibt, wonach gruppiert werden soll und wonach nicht?
Hallo, Autor! Ich kann nicht herausfinden, wie der Rechnungslink mit dem Produkt-Hub verbunden werden kann (Abbildung 1)? Wenn Ihre Rechnung Link-Tabelle enthält Hash-Schlüssel aus Produkt-Hub-Tabelle, dann ist es nicht Rechnung, sondern InvoiceItem und wenn das so ist, dann Invoice Brücke kann nicht durch Rechnung (Nummer) aggregiert werden - das Modell bricht zusammen. Bitte helfen Sie mir, es herauszufinden 🙂
Hallo Andrey,
Sie haben Recht. Danke für die Rückmeldung. Der nicht-historisierte Link sollte den Begriff "line_item" enthalten, da er sich auf den Product Hub bezieht. Die GROUP BY-Anweisung muss außerdem das Snapshot-Datum, den Hashkey der Filiale, den Hashkey des Kunden sowie die Rechnungsnummer enthalten. Wir werden dies korrigieren.
- Markus