
Implementierung von Ghost Records in Data Vault 2.0
Während der Entwicklung von Data Vault – von der ersten Iteration bis hin zur aktuellen Version Data Vault 2.0,– haben wir die Begriffe "Ghost Records" und "Zero Keys" sowohl in unserer Literatur als auch in unserem Data Vault 2.0 Boot Camps verwendet. Seitdem haben wir festgestellt, dass diese Konzepte häufig miteinander verwechselt oder sogar synonym verwendet werden.
In diesem Blogeintrag beschäftigen wir uns mit der Implementierung von Ghost Records in Data Vault 2.0. Bitte beachten Sie, dass es sich hierbei um den ersten Teil einer mehrteiligen Blogserie handelt, in der wir die Unterschiede zwischen Ghost Records und Zero Keys.
Warum Ghost Records einführen?
Das Konzept der Ghost Records wird üblicherweise im Zusammenhang mit der Implementierung von Point-in-Time (PIT)-Tabellen genannt. PIT-Tabellen dienen im Business Vault als sogenannte Query-Assistants, in denen Snapshots von Daten für bestimmte Zeitintervalle erstellt werden, die von den Datenkonsumenten definiert sind. Wichtig dabei ist: Diese Intervalle können täglich, wöchentlich, in Echtzeit oder beliebig anders definiert sein. Jeder Eintrag in einer PIT-Tabelle materialisiert Joins von einem zentralen Data Vault Objekt (entweder einem Hub oder einem Link) zu den zugehörigen Satellitenstrukturen. Dadurch wird die Anzahl der Joins bei Abfragen reduziert und somit die Abfrageleistung deutlich verbessert.
In einigen Fällen kann es jedoch vorkommen, dass beim Join – etwa zwischen einem Hub und einem seiner Satelliten – für bestimmte Snapshots kein zugehöriger Delta-Eintrag im Satelliten gefunden wird. Der Grund dafür kann sein, dass der Business Key zu diesem Zeitpunkt entweder nicht verfügbar oder der Datenquelle nicht bekannt war.

Verweis auf einen Ghost Record in einer PIT-Tabelle
Um dieses Problem zu umgehen, werden Ghost Records zu den Satelliten-Entitäten hinzugefügt, um Lücken am Anfang der Zeitachse virtuell zu schließen. Dadurch werden Equal Joins in Ad-hoc-Abfragen gegen den Raw Vault ermöglicht. Equal Joins (a.k.a. equi-joins) – also Joins, die ausschließlich Gleichheitsoperatoren verwenden – gelten als die effizienteste und schnellste Form von SQL-Joins.
Wie sieht ein Ghost Record aus?
Ein Ghost Record kann als Dummy-Datensatz verstanden werden, der Standardwerte enthält. In der früheren Iteration von Data Vault (DV1) bestand die Lösung darin, für jeden Schlüssel und jede Satellitenstruktur einen Ghost Record zu erzeugen. Damit ließen sich die Lücken am Anfang der Zeitachse weiterhin auffüllen. Diese Lösung ließ sich jedoch bei großen Datenmengen nur schlecht skalieren. Stellen Sie sich einen Hub mit 10 Millionen Business Keys vor, an den drei Satelliten angebunden sind. Jeder dieser Satelliten würde dann ebenfalls 10 Millionen Ghost Records enthalten – also insgesamt 30 Millionen Ghost Records. Hinzu kommt: Immer wenn ein neuer Business Key in den Hub aufgenommen wird, muss in jedem zugehörigen Satelliten ebenfalls ein entsprechender Ghost Record angelegt werden. Die schiere Menge an Ghost Records würde in diesem Fall den eigentlichen Zweck der Equi-Joins – nämlich schnellere Abfragen zu ermöglichen – zunichtemachen.
So muss seit der Einführung von DV2.0 nur noch ein einziger Ghost Record pro Satellitenstruktur eingefügt werden.
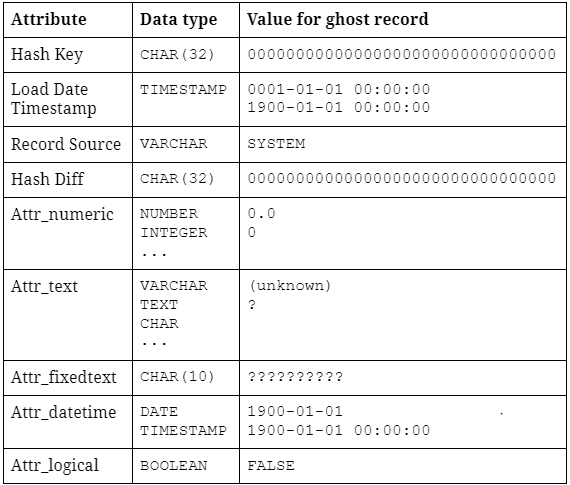
Beispiel: Ghost Record mit Attributen unterschiedlicher Datentypen
Der Ghost Record enthält in der Regel einen konstanten Hash Key: 00000000000000000000000000000000 (32 Mal die Ziffer „0“). Dieser Hash Key wird auch als Zero Key bezeichnet – mehr dazu im nächsten Teil dieser Blogserie. Der zugehörige Load Date Timestamp wird üblicherweise auf den frühestmöglichen Zeitstempel innerhalb des DBMS gesetzt und markiert damit den „Anfangspunkt der Zeit“. Die Record Source „SYSTEM“ weist darauf hin, dass der Datensatz künstlich generiert wurde.
Anschließend folgt eine Liste von Standard NULL-Werten für jedes beschreibende Attribut innerhalb der Satellitenstruktur. Für jeden Datentyp wird ein definierter Standardwert im Ghost Record hinterlegt. Beispielsweise können Attribute mit numerischem Datentyp mit einer (numerischen ) Null belegt werden, während String Attribute – je nach Längendefinition – entweder mit „(unknown)“ oder „?“ gefüllt werden.
Es wird empfohlen, den Ghost Record mit Standardwerten zu befüllen, anstatt lediglich NULL- oder Leerwerte zu verwenden. Diese Standardwerte können dann ebenfalls Downstream weiterverwendet und angezeigt werden. Ein gutes Beispiel dafür sind Dimensionstabellen: Ein String wie „(unknown)“ ist in der Regel deutlich aussagekräftiger als ein einfacher NULL-Wert.
Wie man Ghost Records einfügt
Es gibt mehrere Möglichkeiten, Ghost Records in Satellitestrukturen einzufügen.
Die erste Variante besteht darin, die Ghost Records direkt bei der Objekterstellung als einmalige Operation einzufügen – und danach einfach zu ignorieren. Ganz einfach!
Eine weitere Möglichkeit besteht darin, die Ghost Records während des Ladevorgangs der Satelliten einzufügen. Die Ladeprozedur sollte damit beginnen, einen Ghost Record in das Zielobjekt einzufügen – sofern dieser noch nicht vorhanden ist. Anschließend kann der Satellit wie gewohnt mit den eingehenden Daten befüllt werden. Diese Variante mag auf den ersten Blick etwas übertrieben erscheinen, stellt jedoch sicher, dass die Ghost Records stets vorhanden sind – und im Falle eines versehentlichen Löschens oder nach einem Truncate-Vorgang (z. B. während der Entwicklung) automatisch wieder eingefügt wird.
Beide Varianten lassen sich mit dem Data Vault Automatisierungstool Ihrer Wahl vollständig automatisieren.
Fazit
Wir hoffen, dass dieser Blogbeitrag zur Klärung der Implementierung von Ghost Records in einer Data Vault 2.0-Lösung beitragen konnte. Als Nächstes möchten wir uns dem „anderen Fachbegriff“ – den Zero Keys – widmen und den Unterschied zwischen Ghost Records und Zero Keys erläutern, da genau diese Unterscheidung für viele Data Vault-Anwender häufig verwirrend ist.
Teilen Sie diesen Blogbeitrag gerne mit Ihren Kolleginnen und Kollegen und hinterlassen Sie doch einen Kommentar dazu, wie in Ihrem Projekt Ghost Records implementiert werden!
-von Trung Ta (Scalefree)
Is it really recommended to set default values for the ghost record attributes?
Read somewhere on the forum where Dan advised against putting anything other than NULL, especially for numerical fields. https://datavaultalliance.com/discussions/postid/1813/
The reasoning made sense to me, that if you assign a default value based on the data type you can quickly run into issues downstream. E.g. if you put FALSE as the default for boolean, then the columns IS_ACTIVE or IS_INACTIVE will have VERY different meaning.
You could also consider if you had a employee satellite with a numerical salary column, then setting the default to 0 might affect downstream calculations.
I get that it’s easier to just set the default values in the satellite, rather than in the information mart, but it sounds to me like the default values can be based on a lot of assumptions.
Hello Jeppe,
Thank you for reaching out with the question! It is indeed recommended by Data Vault 2.0 to set default values for ghost record attributes. In the end, the ghost record will end up being only the default member in a dimension, of which the content doesn’t matter much. Moreover, when working with aggregations, you can identify, whether the parent of a hash key is an actual object or a ghost record, through the hash key – i.e. zero key in the case of ghost record (“0000…”).
Thank you kindly
Trung Ta
Hi, by using ghost records we avoid outer joins which i guess shall be more perfomant.
Just a remark, doesnt PIT only needs SATs load_dates ? I dont see reason to duplicate the HUB hask key 3 times in your example, HK_HUB should be sufficient right ?
Thanks,
Emanuel
Hello Emanuel,
Thank you for reaching out with the question! Since you can have either the parent hash key, or the zero key of the ghost record (“0000…”) coming from a Satellite, we recommend having multiple hash key columns in a PIT table structure. Not only does this simplify the management of PIT table structure, but also queries joining PIT table with descriptive information from Satellites – since you have the combination of parent hash key and load date timestamp for each satellite ready for the join.
Thank you kindly,
Trung Ta