Within this part of our ongoing blog series, we would like to introduce a sample data set based upon insurance data. This data set will be used to explain the concepts and patterns expanded upon further in the post. That said, please consider the following situation: an insurance company utilizes two different operational systems, let’s say, a home insurance policy system and a car insurance policy system.
Both systems should be technically integrated, which means if a new customer signs up for a home insurance policy, the customer’s data should be synchronized into the car insurance policy system as well and kept in sync at all times. Thus, when the customer relocates, the new address is updated within both systems.
Though in reality, it often doesn’t go quite as one would expect, as, first of all, both systems are usually not well integrated or simply not integrated at all. Adding to the complexity, in some worst-case scenarios, data is manually copied from one system to the next and updates are not applied to all datasets in a consistent fashion but only to some, leading to inconsistent, contradicting source datasets. The same situation applies often to data sets after mergers and acquisitions are made within an organization.
Within this undesired but all too common scenario, a typical challenge faced is often the question of how to integrate these inconsistent data sets. To illustrate this point, let us look at a scenario in which a business analyst would like to calculate a total insured sum or the total claim amount that a customer has made.
The challenge is how the policies and claims, i.e. transactions, from the home insurance system should be assigned to the customer from the car insurance system, or in other terms, how to identify the correct customer of the transaction.
Sounds simple enough at first but consider this: every single attribute of the customer might change over time and there exists a strong possibility that this change is only applied to one of the two systems in this example given. That being so, it’s not just that the customer might relocate, they might change their credit cards, their email addresses, marry and therefore get a new last name, fix their first name from Mike to Michael or vice-versa, as well as change their birthdate due to data quality issues, e.g., a typo inserted into the home insurance system which was synced to the car insurance system though later fixed only in the home insurance system.
Now, in this situation, how should both datasets be integrated if all data can change over time?
That is the challenge faced by many organizations.
A popular idea is to integrate both datasets on a common attribute that has a low tendency to change, even in the above scenario. The idea is that we create the attribute, that being a business key, when the customer was added within the CRM system, in this case, the customer number. Thus, when the customer is synced into the online store, many descriptive attributes are copied over, including the business key. The exemplary source data already uses rich documents in MongoDB combining customers with their home and car insurance as well as claims. That being so, the JSON object below illustrates a customer with each customer having a unique business key, the customer_id.
The home_insurance array contains information about the home insurance policies, the details about the policy, as well as claims. The same applies for car insurance in the car_insurance array.
Although we already have an aggregated document per customer, some challenges remain in the data such as each block of the contained data can change at any time, i.e. the customer’s data, each individual policy, and claims can be added. Furthermore, the claims do not have unique identifiers which require explicit handling in the target data vault.


To continue, Data Vault consists of three basic entity types:
The concept of the first entity, the Hub entity, is to collect these business keys that are used to identify business objects in an enterprise context. To be more specific, the Hub is a distinct collection of such business keys from each underlying business object ,e.g., customers, products, stores, etc., and are stored in its own collection.
Please note that even semi-structured JSON documents contain these business keys as all enterprise data contain these business keys, regardless of the used structure. The idea now is to integrate documents based on the business keys by extracting them into Hub collections in the EDW layer of the enterprise data warehouse. In MongoDB, a document in a Hub collection looks like the following document:
To better illustrate, the above document structure contains the following attributes:
- The _id attribute is the identifier of the hub document. Instead of relying on MongoDB’s predefined _id value, we are calculating an MD5 hash value for interoperability with other components of the enterprise data warehouse that are not necessarily on MongoDB.
- The ldts attributes is the load date timestamp which indicates when the business key was identified by the hub collection loading process for the very first time.
- The rsrc attribute indicates within the source system in which the business key has originated.
- The customer_id attributes captures the business key, in this example, a business key that identifies customer records.
The hub collection is loaded from all source collections where the defined business key can be found though one must note that all business keys from the source collections should be loaded into the hub collection, regardless of where they can be found. The aggregation pipeline for loading a hub obeys the following principle:
The first step in the aggregation pipeline is to find out which business keys already exists in the target and remove those that are present already. In addition, duplicates are removed before the remaining records are bulk-inserted into the hub document collection.
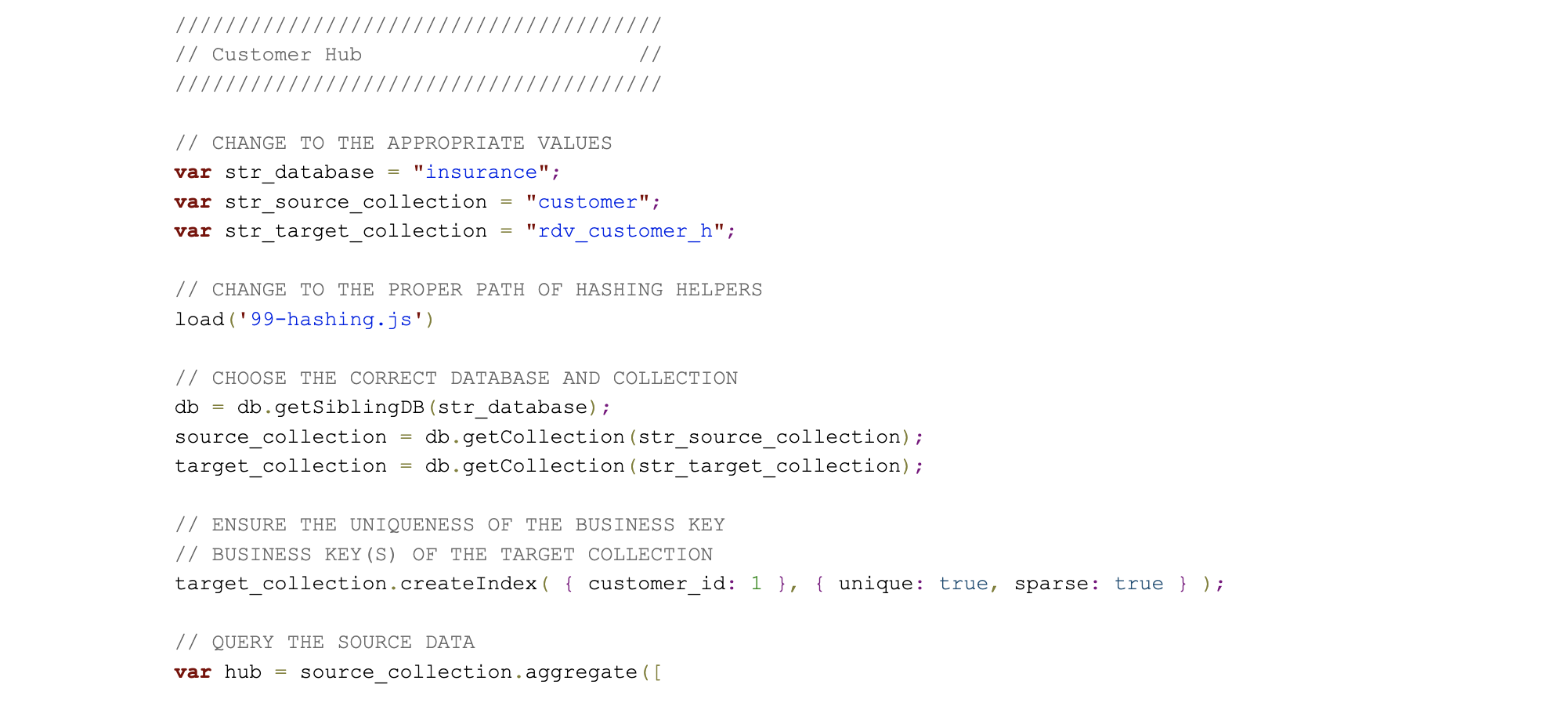
The following code shows an exemplary implementation on MongoDB.
The code example can be executed in the MongoDB Shell as:
In order to calculate the hashes, the below helper method has been used, 99-hashing.js in the above example:
A note on the above code that the authors of this article are optimizing the code and it may still change over time as we tune it for performance. And that concludes this post within our series.
The next article will discuss the next Data Vault entity, the link entity, which implements relationships between business keys. Subsequent articles will discuss how to store descriptive data in satellite documents and how to extract useful information from the Data Vault collections in MongoDB.
Note that this work is from an ongoing project between Scalefree and MongoDB to fine-tune these statements on a massive volume scale. We are going to continue updating these articles in the near future so please check in with us for any updates made in the meantime.
Suggestions? Questions? Comments?
We’d love to hear from you in the comment section below!