
Data Vault 2.0 Implementation
Data Vault 2.0 is often assumed to be only a modeling technique, but it encompasses much more than that. Not only that, but it is a whole BI solution composed of agile Methodik, Architektur, Umsetzung und Modellierung.
Warum also Data Vault verwenden?
- Data Vault 2.0 ermöglicht es Ihnen, automatisierte Ladeprozesse/Muster zu erstellen und Modelle sehr einfach zu generieren
- Plattformunabhängigkeit
- Prüfbarkeit
- Skalierbarkeit
- Unterstützt ELT anstelle von ETL-Prozesse
Now that we answered the why, you may be wondering what steps are needed to implement Data Vault 2.0 in your project.
Das hängt von vielen Faktoren ab, z. B. von Ihrem Geschäftsfall, der gewünschten Architektur, der Art und Weise, wie Ihre Quellen geladen werden, dem Zeitplan für Ihr Projekt usw.
Begehung einer Data Vault 2.0-Implementierung
It can be a bit overwhelming for beginners to start using Data Vault 2.0 and how and where to implement it. In this webinar, a very basic guide will be provided showing the steps needed for making a Data Vault 2.0 implementation based on a business requirement from scratch. This will be done with a demonstrated example, and it starts from the gathering of some sample requirements to the finished delivered product.
Data Vault 2.0 feature by feature architecture
Eines ist sicher: Die Architektur sollte vertikal und nicht horizontal aufgebaut sein. Das heißt, nicht Schicht für Schicht, sondern Merkmal für Merkmal.
A common approach here is the Tracer Bullet approach. Based on business value, which is defined by a report, a dashboard, or an information mart, the source data needs to be identified, modeled, and loaded through all layers of the architecture.
Nehmen wir zum Beispiel an, dass die Geschäftsanforderung darin besteht, ein Dashboard zu erstellen, um die Verkaufszahlen des Unternehmens zu analysieren:
1. Auszug
Als Erstes müssen wir die Daten aus den Quellsystemen extrahieren und die Daten so, wie sie sind, irgendwo laden. In diesem Beispiel haben wir die Daten in einen vorübergehenden Bereitstellungsbereich gelegt, aber Sie können auch einen dauerhaften Bereitstellungsbereich in einer Data Lake auch.
2. Transformieren
Next, you should apply some hard rules if necessary, be careful with this as you do not want to make business calculations here, using a transformation tool. There are a lot of different Data Warehouse-Automatisierungs Werkzeuge, aus denen Sie wählen können: dbt, Koaleszieren, WhereScape , usw.
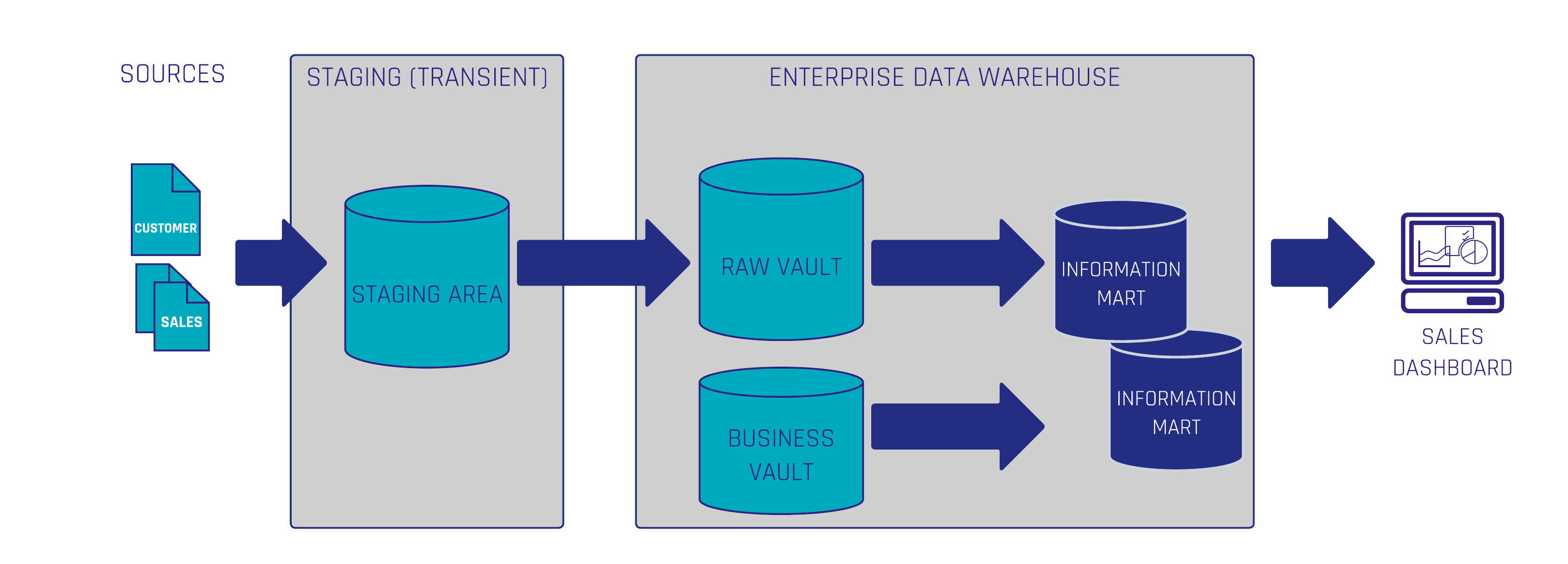
3. Laden Sie
Laden Sie Ihre Raw Stage in den Raw Vault.
4. Modell Geschäftsanforderungen
Modellieren Sie die Data Vault-Entitäten, die für die zu erfüllende Geschäftsanforderung benötigt werden. Wenn wir z.B. einige Verkaufstransaktionen und Kundendaten haben, modellieren wir eine Nicht-historisierter Linkauch Transactional Link genannt, und einen Customer Hub, sowie zusätzliche Satelliten zur Aufnahme der Kunden beschreibende Daten die wir am Ende im Sales Dashboard sehen wollen.
5. Geschäftslogik anwenden
Next, we need some calculations and aggregations to be performed, so we will build some business logic on top of the raw entities, loading it into the business vault.
6. Einen Informationsmarkt aufbauen
Now, we could directly use the data stored in the Raw and Business Vault into charts/dashboards, but we want to structure the data, so it can be easily read and fetched by business users, so we will build an Informationsmarkt mit einem Sternschema-Modell mit einer Faktentabelle und Dimensionen.
7. Daten visualisieren
Um das Sales Dashboard in einem BI-Visualisierungstool wie PowerBI oder Tableau zu erstellen, holen wir uns jetzt direkt aus dem Sternschema im Information Mart, das alle Informationen enthält, die wir brauchen, und verwenden eine Verbindung zu meinem data warehouse in unserer Datenbank.
Data Vault 2.0 bietet einen agilen, skalierbaren und flexiblen Ansatz für Data Warehousing Automatisierung. Wie im Beispiel gezeigt, haben wir nur die Data Vault-Tabellen modelliert, die für die Erledigung der gestellten Aufgabe, ein Vertriebs-Dashboard zu erstellen, erforderlich waren. Auf diese Weise können Sie Ihr Unternehmen je nach Bedarf skalieren und müssen nicht das gesamte Unternehmen auf einmal abbilden.
Die Antwort auf die Frage, wie man Data Vault 2.0 einführt, lässt sich in einem einfachen Satz zusammenfassen: Konzentrieren Sie sich auf den Geschäftswert!
If you would like to see an explanation of this step-by-step implementation with some demonstration of actual data using dbt as the chosen transformation tool, check out the Webinar-Aufzeichnung.
Fazit
Implementing Data Vault 2.0 involves a structured approach that begins with extracting data from source systems into a staging area, followed by minimal necessary transformations, and loading into the Raw Vault. Subsequently, business requirements guide the modeling of Data Vault entities, application of business logic, construction of information marts, and data visualization. This feature-by-feature methodology ensures scalability and flexibility, allowing organizations to focus on delivering business value incrementally. By aligning development efforts with specific business needs, enterprises can efficiently build and expand their data warehousing solutions.
- Barbara Schlottfeldt Maia (Scalefree)