
Namenskonventionen im Data Warehousing
Eine erste Entscheidung von entscheidender Bedeutung innerhalb Data Vault Entwicklung bezieht sich auf die Definition von Namenskonventionen für Datenbankobjekte. Als Teil der Entwicklungsstandardisierung sind diese Konventionen obligatorisch, um ein gut strukturiertes und konsistentes Data Vault-Modellzu erstellen. Es ist wichtig anzumerken, dass angemessene Namenskonventionen die Benutzerfreundlichkeit des Data Warehouses erhöhen, nicht nur für Lösungsentwickler, sondern auch für Power-User bei der Datenexploration.
In diesem Artikel werden wir die wichtigsten Überlegungen im Rahmen unseres Standardwerks, dem Prozess der Festlegung von Namenskonventionen, vorstellen.
In diesem Artikel:
- Dokumentation der Namenskonvention
- Benennungskonventionen: Groß- und Kleinschreibung
- Benennungskonventionen: Verwendung von Unterstrichen "_", Bindestrichen "-"
- Benennungskonventionen: Abkürzungen, Akronyme
- Benennungskonventionen: Singular vs. Plural von Objektnamen
- Benennungskonventionen: Präfix vs. Suffix
- Fazit
Dokumentation der Namenskonvention
Es ist eine Sache, einfach nur Namenskonventionen zu definieren, die bei der Entwicklung Ihres data warehouse verwendet werden, aber es ist eine ganz andere, Konsistenz herzustellen, um definierte Namenskonventionen zu schaffen, die zu Standards werden sollen. Dennoch ist es eine gute Praxis, einen Leitfaden für die Benennung von Data Warehouse-Objekten zu dokumentieren. Zu diesem Zweck werden in den nächsten Abschnitten mehrere Überlegungen erörtert, die bei der Festlegung der Namenskonventionen für eine data warehouse-Lösung zu berücksichtigen sind.
Benennungskonventionen: Briefkasten
Bei der Wahl der Groß- und Kleinschreibung von Namen gibt es mehrere Möglichkeiten: Großbuchstaben, Kleinbuchstaben, Camel Case und Pascal Case. Auch wenn die Unterschiede gering sind, hat jede Option ihre eigenen Vor- und Nachteile in Bezug auf die Lesbarkeit und die Schreibbarkeit, um die Unterschiede kurz zu erläutern.
Letztendlich hängt die Entscheidung über die Groß- und Kleinschreibung davon ab, welches Datenbankmanagementsystem verwendet wird, da einige, wie z. B. PostgreSQL, die Groß- und Kleinschreibung von Objektnamen unterstützen, was die Verwendung von Namen in Anführungszeichen erfordert. Daher bevorzugen Benutzer oft die Kleinschreibung als Standard in PostgreSQL, da die Kleinschreibung von Objektnamen die Menge des zu generierenden Codes reduzieren kann und gleichzeitig die Benutzerfreundlichkeit für Ad-hoc-Abfragen durch Power-User verbessert. Nichtsdestotrotz ist es zwingend erforderlich, eine konsistente Groß- und Kleinschreibung sowohl für Entitäts- als auch für Spaltennamen beizubehalten.
Benennungskonventionen: Verwendung von Unterstrichen "_"Bindestriche "-"
Um die Lesbarkeit zu verbessern, sind Worttrenner wie Unterstriche "_" oder, je nach Anwendungsfall, Bindestriche "-" wünschenswert. Es ist jedoch zu bedenken, dass Bindestriche in vielen Systemen als Minuszeichen interpretiert werden. Abgesehen davon werden Bindestriche häufig in XML- oder JSON-Datenformaten verwendet, obwohl sie leicht durch Unterstriche ersetzt werden können, wenn letztere als Trennzeichen verwendet werden.
Benennungskonventionen: Abkürzungen, Akronyme
Einige Systeme schreiben Zeichenbeschränkungen für Objektnamen vor, z.B. erlaubt Oracle 12.1 und darunter nur eine maximale Länge von 30 Bytes für Objektnamen. Daher können Abkürzungen und Akronyme bei der Benennung von Objekten berücksichtigt werden, auch wenn sie oft zu Fehlinterpretationen führen können. Um dem entgegenzuwirken, empfiehlt es sich, ein Dokument zu erstellen, das eine Liste der verwendeten Abkürzungen mit einer detaillierten Beschreibung ihrer Bedeutungen enthält. Um eine mögliche Verwirrung zu vermeiden, sollte jedoch eine übermäßige Verwendung von Abkürzungen und Akronymen vermieden werden.
In logischen Modellen ist es ratsam, dass Objektnamen so selbsterklärend wie möglich sind, d.h. die meisten Wörter sollten vollständig ausgeschrieben werden, mit Ausnahme gängiger Abkürzungen für längere Wörter wie "abt" für "Abteilung" oder "org" für "Organisation". In physikalischen Modellen werden jedoch in der Regel Abkürzungen und Akronyme verwendet, um die Objektnamen kurz zu halten.
Benennungskonventionen: Singular vs. Plural von Objektnamen
Es ist eine gängige Praxis, Substantive oder Substantivphrasen in ihrer Einzahl als Objektnamen zu verwenden. Auf diese Weise wird vermieden, dass man sich mit der unregelmäßigen Pluralisierung im Deutschen befassen muss, z. B. Mann/Männer, Person/Personen, was unnötigerweise eine ganz neue Ebene der Komplexität innerhalb des Datenmodells bedeuten würde.
Benennungskonventionen: Präfix vs. Suffix
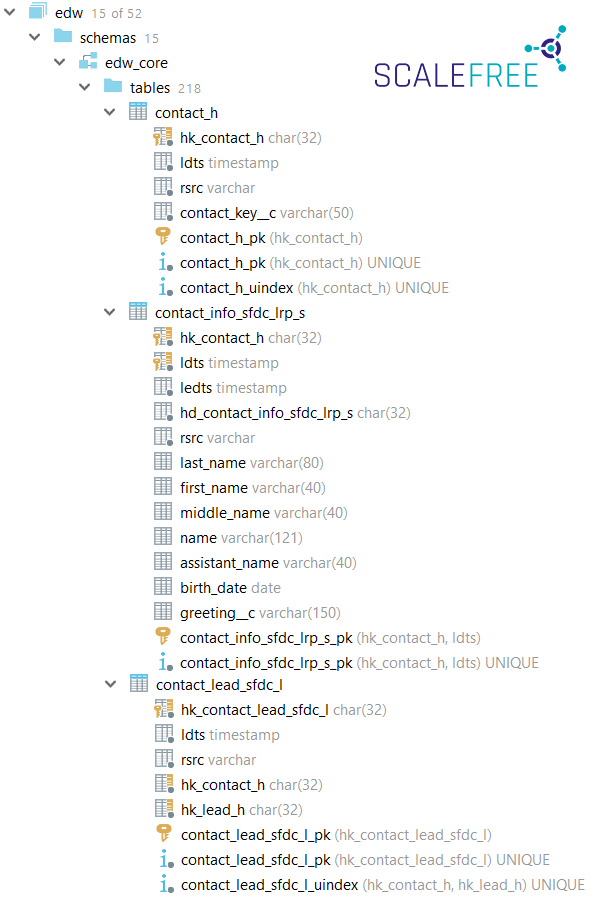
Ob Objekte mit Präfixen oder Suffixen benannt werden, ist für die Entwicklung nicht von großer Bedeutung. Intern bei Scalefreebevorzugen wir Tabellennamen mit Suffixen wie "Kunde_h" und "Transaktion_l", anstatt Präfixe zu verwenden. Der Vorteil dieser Methode besteht darin, dass die meisten Datenbanktools Tabellen alphabetisch sortieren, so dass alle Tabellen, die mit einem Geschäftsobjekt in Verbindung stehen, gruppiert werden. So werden zum Beispiel alle Kontaktknoten, Satelliten und Links, deren Namen mit "Kontakt_..." beginnen, im Browser gemeinsam gefunden. Dies unterstützt die Datenexploration durch Power-User und Entwickler.
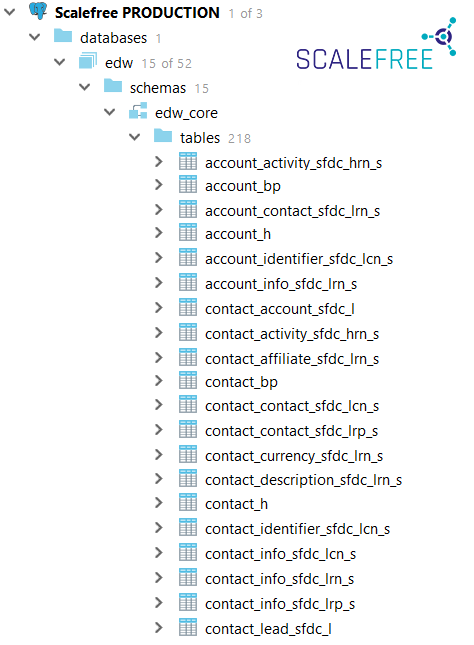
Nichtsdestotrotz können Präfixe in einigen Anwendungsfällen sinnvoll sein, z. B. hilft die Verwendung von Präfixen in den Namen von Ebenenschemata dabei, diese im Datenbankbrowser übersichtlich zusammenzufassen.
Fazit
Namenskonventionen sind zum Teil eine Frage der persönlichen Vorlieben und organisatorischer Richtlinien. Je systematischer und konsistenter die Namenskonventionen bei ihrer Festlegung sind, desto mehr Vorteile ergeben sich letztendlich bei der Entwicklung und Implementierung Ihrer Data Vault Lösung. Um dies zu verdeutlichen, empfehlen wir den Data Vault-Entwicklungsteams, eine einfache SQL-Funktion zu schreiben und zu implementieren, die die gesamte Datenbank auf Inkonsistenzen bei den Namenskonventionen prüft. Damit wird sichergestellt, dass die Standards eingehalten werden.
Möchten Sie wissen, wie wir hier bei Scalefree die Namenskonventionen standardisieren? In einem kommenden Artikel werden wir mehrere konkrete Vorschläge für Namenskonventionen vorstellen, von denen die meisten sowohl von unseren Kunden als auch von unserem Team regelmäßig intern verwendet werden.
Lassen Sie uns nun im Kommentarfeld unten darüber diskutieren: Wie setzen Sie bei Ihrer Data Vault-Entwicklung Namenskonventionen um? Welche Konventionen befolgen Sie?
Assume you have a source system in english, but your users speak german. Additionaly the column names from the source system are highly abbreviated, while your users require speaking column names in their reports. What is the better strategy to name the columns in the raw vault? On one hand you could follow the data driven approach and therefore use the table and column names from the source system. The advantage here is to deliver results quickly. On the other hand you could follow the business centered approach and have german and speaking column names in the raw vault. The advantage would be that you find requested data faster and don’t have to rename columns on the way to reporting. What is the better approach from your experience?
Hello Daniel,
Thank you for reaching out with your question! Generally it is a good idea to position translation work further downstream (i.e. Business Vault, preferably even Information Delivery), in order to achieve the advantage that you mentioned – to deliver results rapidly. Moreover, if an attribute is renamed in the source, you won’t have to propagate the column rename through the Raw/Business Vault.
However, if for example you have to process a source system that is in a completely foreign language to your organisation, you might want to have translation work done earlier in the pipeline, either in the Raw Vault, or in the Staging area. This ensures that you get needed data into your data warehouse in a comprehensible state for all users – both developers and data consumers.
Thank you kindly,
Trung Ta
At ChipSoft we use an ORM to generate the tables for our data warehouse product. Definition is done in C#, so casing follows C# conventions (=PascalCase).
We use database schema’s as datastores (being security boundaries). We have not enough of them yet to prescribe a naming standard.
For the table names in Data Vault we also prefer postfixing, for the same grouping argument you also use.
The format of a Hub-table name would be {module}{entity}Hub, e.g. ConfigUserHub, e.g. ConfigUserHub.
The corresponding Satellite-tables would have names like {module}{entity}{optional subdivision}Sat, e.g. ConfigUserSat or ConfigUserPersonalDataSat.
The Link-tables would have names like ConfigUserLink and ConfigUserOrganisationalLink.
In this way, tables will first be grouped per module, and next per entity, which we think is convenient.
For Information marts (dimensional modelled) we use prefixing, because Dimension-tables are not necessarily bound to a single Fact-table.
The format of Dimension-table names is: Dim{optional subject area}[entity}.
The format of Fact-table names is: Fact{subject area}{measure group}.
For Fact-tables (as well as Data Vault Bridge-tables) we use often plural forms. All other table names use singular forms.
Thank you for your comment Arne!
Thank you for your comment Arne!
Kind regards,
Your Scalefree Team