Einführung
Im Zeitalter von Big Data verlassen sich Unternehmen in hohem Maße auf data warehouses zur Speicherung, Verwaltung und Analyse großer Datenmengen. Die Effektivität eines data warehouse hängt jedoch von der Qualität der darin enthaltenen Daten ab. Eine schlechte Datenqualität kann zu ungenauen Erkenntnissen, fehlerhaften Entscheidungen und letztlich zu einem beeinträchtigten Geschäftserfolg führen. Doch wie lässt sich eine hohe Datenqualität sicherstellen?
In diesem Blog-Artikel gehen wir auf die Bedeutung der Datenqualität in einem Enterprise Data Warehouse und bieten praktische Strategien, um genaue, zuverlässige und hochwertige Daten mit Data Vault 2.0 zu gewährleisten.
Vielleicht möchten Sie sich auch die Aufzeichnung des Webinars zu genau diesem Thema ansehen. Sehen Sie es hier für kostenlos!
WAS SIND DIE GRÜNDE FÜR SCHLECHTE DATEN?
Die Datenqualität bezieht sich auf die Genauigkeit, Vollständigkeit, Konsistenz und Zuverlässigkeit der Daten. Im Zusammenhang mit einer data warehouse ist die Aufrechterhaltung einer hohen Datenqualität zu erfüllen ist entscheidend, um aussagekräftige Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen. Mehrere Faktoren tragen zum Vorhandensein schlechter oder fehlerhafter Daten bei. Das Erkennen und Verstehen dieser Gründe ist für die Umsetzung wirksamer Strategien für das Datenqualitätsmanagement unerlässlich. Hier sind einige häufige Gründe für schlechte Daten in einem data warehouse:
- Unvollständige oder fehlende Quelldaten
- Fehlende Standardisierungen
- Probleme bei der Datenumwandlung
- Schlechte Datenverwaltung
- Unzureichende Validierung und Qualitätskontrollen
- Mangelnde Schulung und Sensibilisierung der Nutzer
DATENQUALITÄTSTECHNIKEN
Es gibt eine Vielzahl von Datenqualitätstechniken, und es gibt keine einzige beste Option für alle Probleme. Die Schwierigkeit besteht darin, die aktuelle Situation zu verstehen und die Stärken und Schwächen der verfügbaren Techniken zu erkennen. In der Tat ist die Wirksamkeit der Techniken je nach Kontext unterschiedlich. Eine bestimmte Technik eignet sich in manchen Situationen gut, in anderen weniger gut. Scott Ambler entwickelte fünf Vergleichsfaktoren, die für die Beurteilung der Wirksamkeit einer Datenqualitätstechnik geeignet sind. Diese Faktoren, die unten aufgeführt sind, sollen Ihnen helfen, die richtige DQ-Technik für die jeweilige Situation auszuwählen:
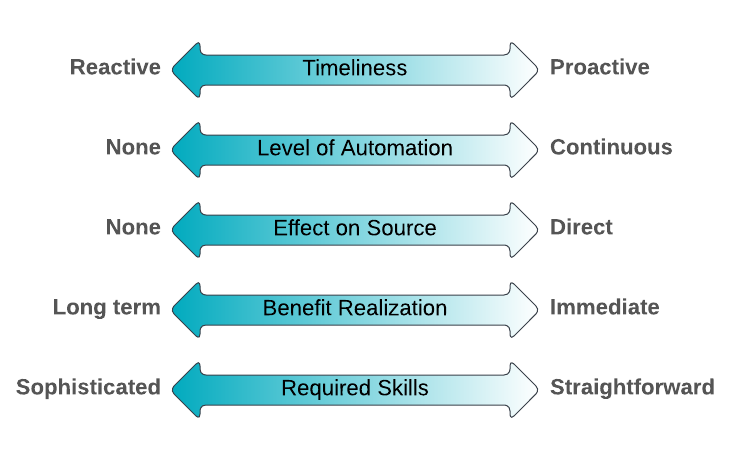
Quelle: https://agiledata.org/essays/dataqualitytechniquecomparison.html
- Pünktlichkeit: Reagieren Sie auf ein entdecktes DQ-Problem oder wenden Sie es an, um DQ-Probleme proaktiv zu vermeiden oder zu reduzieren?
- Grad der Automatisierung: Inwieweit ist eine Automatisierung möglich? Eine kontinuierliche Technik würde bei Bedarf automatisch aufgerufen werden.
- Auswirkungen auf die Quelle: Hat die Technik irgendwelche Auswirkungen auf die eigentliche Datenquelle?
- Realisierung des Nutzens: Wird der Nutzen der Qualitätsverbesserung sofort eintreten oder ist ein langfristiger Nutzen zu erwarten?
- Erforderliche Fähigkeiten: Erfordert die Technik anspruchsvolle Fähigkeiten, die möglicherweise durch Ausbildung/Erfahrung erworben werden müssen, oder ist die Technik leicht zu erlernen?
DIE VORTEILE DES DATA VAULT 2.0-ANSATZES
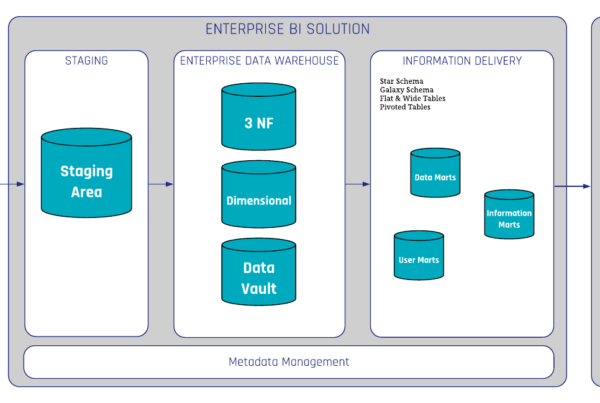
Wenn fehlerhafte Daten entdeckt werden, muss als Erstes eine Ursachenanalyse durchgeführt werden. Was ist, wenn die fehlerhaften Daten aus der Quelle stammen? Der beste Ansatz wäre, die Fehler direkt in der Datenbank zu beheben. Quellsystem. Diese Methode wird jedoch häufig abgelehnt, da sie als kostspielig angesehen wird. Da die Quellen außerhalb der Reichweite eines data warehousing-Teams liegen, müssen wir einen Weg finden, die schlechten Daten irgendwo in unserer Architektur zu bereinigen. In Data Vault 2.0 betrachten wir eine Datenbereinigungsroutine als eine Geschäftsregel (Soft Rule), wobei diese Regeln in der Business Vault.
In der gezeigten Architektur (Abbildung 1) gibt es eine in den Business Vault integrierte Qualitätsschicht, in der die Datenbereinigungsroutinen durchgeführt werden. Ziel ist es, die bereinigten Daten in hohem Maße für nachgelagerte business vault- und Information Mart-Objekte wiederverwendbar zu machen. Wenn sich die Datenqualitätsregeln ändern oder neue Erkenntnisse über die Daten gewonnen werden, ist es möglich, die Regeln anzupassen, ohne dass frühere Rohdaten neu geladen werden müssen.
Jetzt sind die Daten bereit für die Verwendung in einem beliebigen Dashboarding- oder Berichtstool. Es ist auch möglich, die bereinigten Daten zurück in die Quelle zu schreiben. Zu diesem Zweck werden die Daten an eine Schnittstelle Mart die wiederum die Daten an das Quellsystem selbst zurücksendet. Auf diese Weise können die Geschäftsanwender die hochwertigen Daten auch in ihren Quellanwendungen nutzen. Wenn die Rohdaten das nächste Mal in das Raw Data Vault geladen werden, sind die Daten bereits bereinigt.
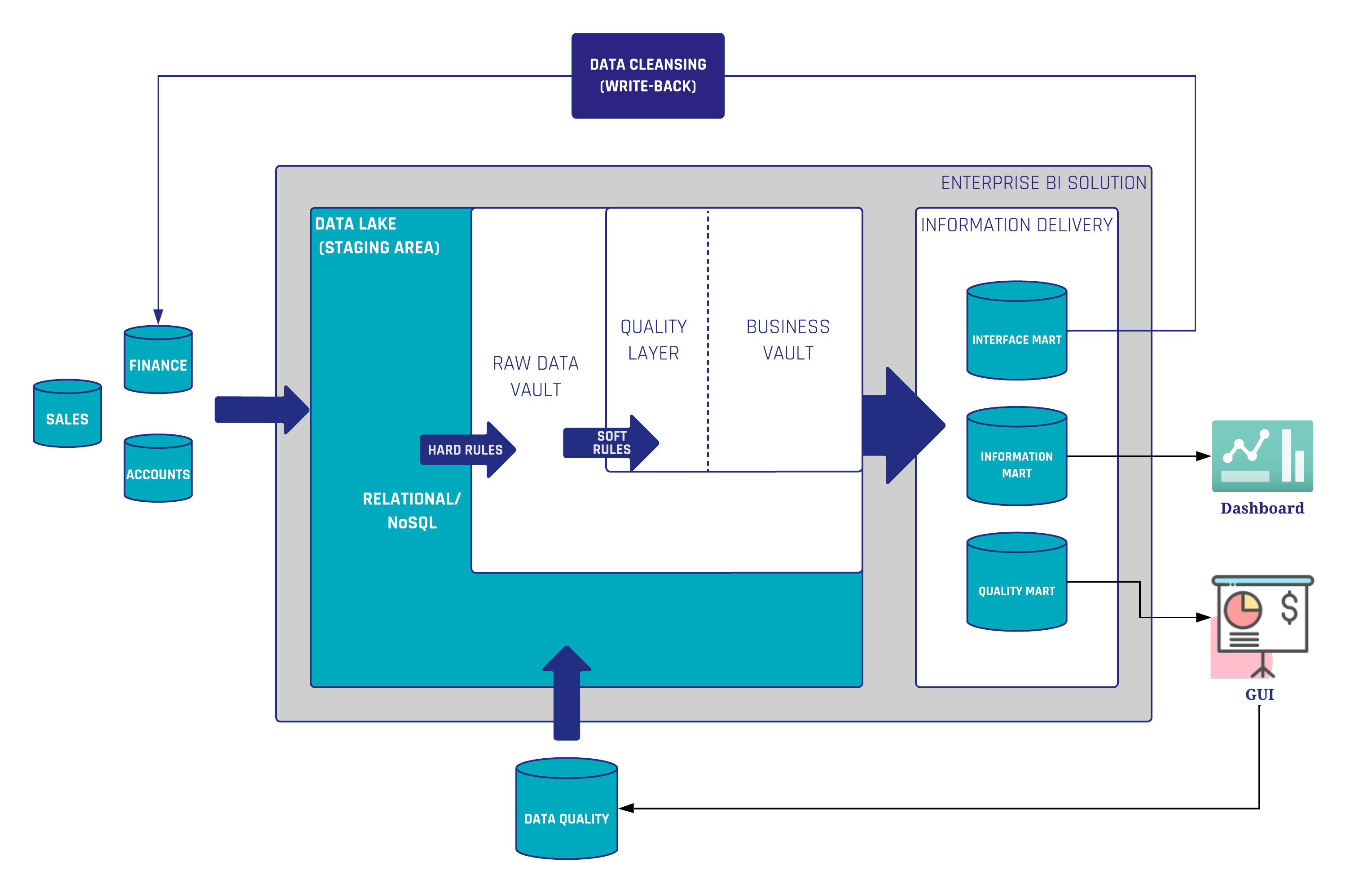
Der zweite in Abbildung 1 beschriebene Anwendungsfall ist die Überwachung schlechter Daten durch einen sogenannten Quality Mart. Der Quality Mart ist Teil der Informationsbereitstellungsschicht und selektiert alle schlechten Daten anstelle der bereinigten Daten. Auf dieser Grundlage können Berichte oder grafische Benutzeroberflächen für den Datenverwalter erstellt werden. Darüber hinaus kann der Datenverwalter Kommentare zu bestimmten Datensätzen hinterlassen, die nicht als schlechte Daten betrachtet werden sollten oder Ausnahmen von den Regeln darstellen. Diese Benutzeroberfläche speichert alle hinzugefügten Daten (Kommentare, Markierungen usw.) in einer Datenbank, die wiederum als Quelle für das Data Vault dient. Diese Daten können verwendet werden, um die Geschäftsregeln zu erweitern. Insbesondere, um die Ausnahmen von den Datenbereinigungsregeln herauszufiltern.
Ein weiterer Vorteil von Data Vault 2.0 sind die hohen musterbasierten und standardisierten Einheiten. Dies ermöglicht eine einfache und automatisierte Entwicklung von technischen Tests. Einmal für jede Data Vault-Entität erstellt, können diese Tests sowohl auf die Raw Data Vault-Entitäten als auch auf die Business Vault-Entitäten angewendet werden. Dies gewährleistet ein konsistentes und prüfbares data warehouse. Sehen Sie sich dies an Blog-Artikelwenn Sie ausführlichere Informationen über technische Prüfungen in Data Vault benötigen.
GEMEINSAME DATENQUALITÄTSTECHNIKEN
Im letzten Abschnitt haben wir bereits einige Techniken zur Gewährleistung einer hohen Datenqualität in einer Data Vault 2.0-Architektur beschrieben. Natürlich gibt es eine Reihe weiterer Techniken, die unabhängig davon sind, welcher Modellierungsansatz verwendet wird. Darüber hinaus gibt es Techniken, die sich nicht primär auf die Datenqualität konzentrieren, diese aber dennoch positiv beeinflussen. Im Folgenden wollen wir uns einige von ihnen genauer ansehen:
- Validierung von Geschäftsregeln: An dieser Stelle müssen wir zwischen Datenqualität und Informationsqualität unterscheiden. Die Datenqualität konzentriert sich auf die intrinsischen Merkmale der Daten und befasst sich mit Problemen wie Fehlern, Inkonsistenzen und Vollständigkeit auf granularer Ebene. Informationsqualität ist ein breiteres Konzept, das nicht nur die Qualität einzelner Datenelemente, sondern auch den Gesamtwert und den Nutzen der aus diesen Daten abgeleiteten Informationen umfasst. Was für den einen Geschäftsfall eine nützliche Information ist, kann für einen anderen nicht ausreichend sein. Aus diesem Grund müssen die Geschäftsanwender stark in diesen Prozess einbezogen werden, zum Beispiel durch Benutzerakzeptanztests.
- Datenverwaltung beinhaltet die Festlegung von Rollen, Zuständigkeiten und Verantwortlichkeiten für die Datenqualität und stellt sicher, dass Daten als wertvolles Unternehmensgut behandelt werden. Entwicklung und Durchsetzung von Data Governance Rahmenwerke, einschließlich Datenqualitätsstandards, Verantwortlichkeiten für die Verwaltung und Dokumentation.
- Leitfaden für Daten und Standardisierung gewährleistet die Einheitlichkeit von Formaten, Einheiten und Werten im gesamten data warehouse und verringert so das Risiko von Fehlern aufgrund von Abweichungen in der Datendarstellung. Festlegung und Durchsetzung standardisierter Namenskonventionen, Maßeinheiten, Formatierungsregeln und Datensicherheits-/Privatschutzkonventionen. Darüber hinaus ist das Data Vault 2.0 in dieser Hinsicht sehr hilfreich, da alle Einheiten stark standardisiert und automatisierbar sind.
- Datenverwalter: Als Teil der Data-Governance-Praxis ist ein Datenverwalter eine Aufsichts-/Governance-Rolle innerhalb einer Organisation und dafür verantwortlich, die Qualität und Zweckmäßigkeit der Daten der Organisation sicherzustellen.
- Kontinuierliche Integration (CI) ist eine Entwicklungspraxis, bei der die Entwickler ihre Arbeit häufig integrieren. Erfolgreiche Tests sollten eine obligatorische Bedingung für die Einführung jeder neuen Änderung an Ihrem System sein. EDW Code-Basis. Dies lässt sich durch den Einsatz von DevOp-Tools und die kontinuierliche Integration in Ihrem Entwicklungszyklus erreichen. Die Durchführung automatisierter Tests bei jeder Überprüfung oder Zusammenführung von Code stellt sicher, dass Probleme mit der Datenkonsistenz oder Fehler frühzeitig erkannt und behoben werden, bevor sie in die Produktion einfließen.
- A Review ist ein Peer-Review der Implementierung (Quellcode, Datenmodelle usw.). Die Entwicklung eines soliden Überprüfungsprozesses bildet die Grundlage für eine kontinuierliche Verbesserung und sollte Teil des Arbeitsablaufs eines Entwicklungsteams werden, um die Qualität zu verbessern und sicherzustellen, dass jeder Teil des Codes von einem anderen Teammitglied geprüft wurde.
- Benutzer Ausbildung und Awareness: Aufklärung der Benutzer über die Bedeutung der Datenqualität und Bereitstellung von Schulungen zu den erforderlichen Themen und Fähigkeiten. Förderung einer Kultur des Datenqualitätsbewusstseins innerhalb der Organisation, um die proaktive Identifizierung und Lösung von Datenqualitätsproblemen zu fördern.
Schlussfolgerung
Es steht außer Frage, dass eine hohe Datenqualität für ein erfolgreiches data warehousing-Projekt unerlässlich ist. Der Prozess hin zu einer hohen Datenqualität ist keine einmalige Anstrengung, sondern eine ständige Verpflichtung. Es handelt sich um einen vielschichtigen Prozess, der eine Kombination von Techniken, teamübergreifende Zusammenarbeit und die Förderung einer Kultur der Datenverantwortung umfasst.
In diesem Artikel haben wir uns mit den Ursachen für schlechte Daten befasst und verschiedene Techniken zur Bewältigung dieser Probleme erörtert. Genauer gesagt, haben wir beschrieben, wie Datenqualitätstechniken in einer Data Vault 2.0-Architektur implementiert werden können.
Wenn Sie tiefer in das Thema Datenqualität eintauchen möchten, sollten Sie sich den kostenlosen Webinar Aufnahme.
- Julian Brunner (Scalefree)
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.