
Als Dan Linstedt, Mitbegründer von Scalefree, das Data Vault erfand, hatte er mehrere Ziele vor Augen. Eines der Ziele war es, Daten so schnell wie möglich aus der Quelle in ein data warehouse-Modell zu laden, sie zu Informationen zu verarbeiten und sie dem Unternehmensanalysten in jeder gewünschten Zielstruktur zu präsentieren.
Der Einfachheit und Automatisierung halber besteht das Modell Data Vault nur aus drei Grundtypen von Einheiten:
- Hubs: eine eindeutige Liste von Unternehmensschlüsseln
- Verknüpfungen: eine eindeutige Liste von Beziehungen zwischen Geschäftsschlüsseln
- Satelliten: beschreibende Datendie den übergeordneten Schlüssel (Geschäftsschlüssel oder Beziehung) in einem bestimmten Kontext beschreiben, der im Laufe der Zeit versioniert wurde.
Nun, wie wir immer lehren (und manchmal predigen): Sie können alle Unternehmensdaten allein mit diesen drei Entitätstypen modellieren. Ein Modell, das nur diese Entitätstypen verwendet, hätte jedoch mehrere Nachteile. Viele komplexe Joins, Speicherverbrauch, Ingestion-Leistung und verpasste Möglichkeiten zur Virtualisierung.
Die Lösung? Wir fügen ein paar weitere Schrauben und Muttern zu den wichtigsten Entitätstypen des Data Vault hinzu, um diese Probleme zu bewältigen. Eine dieser Schrauben ist der nicht-historisierte Link, auch bekannt als Transaction Link:

In diesem Beispiel ist "Sales" eine nicht-historisierte Verbindung, die Verkaufstransaktionen eines Kunden im Zusammenhang mit einer Filiale erfasst. Das Ziel der nicht-historisierten Verbindung ist es, eine hohe Leistung auf dem Weg in den data warehouse und auf dem Weg nach draußen zu gewährleisten. Vergessen Sie nicht, dass das ultimative Ziel von data warehousing der Aufbau eines data warehouse ist, nicht nur dessen Modellierung. Und zum Aufbau eines data warehouse gehört viel mehr als nur das Modell: Es braucht Menschen, Prozesse und Technologie.
Wie also erreicht die nicht-historisierte Verbindung ihre Ziele? Denken Sie an Ihre Business-Analysten. Was sind ihre Ziele? Um ehrlich zu sein, ist ihnen ein Data Vault-Modell letztlich egal. Stattdessen wünschen sie sich dimensionale Modelle wie Sternschemata und Schneeflockenmodelle oder flache und breite Modelle für Data Mining. Oder sie wollen hin und wieder die hässlichen Tabellen aus dem Mainframe sehen, manchmal verknüpft, manchmal nicht, und viele Leute verstehen die Beziehungen nicht mehr ganz... aber für die Rückwärtskompatibilität ist das einfach toll.
Nach der Definition des Ziels stellt sich die nächste Frage: Was ist die Zielgranularität? In einem dimensionalen Modell spiegelt die Zielgranularität von Faktentabellen beispielsweise häufig die zu analysierenden Transaktionen wider (man denke an Anrufdatensätze in der Telekommunikationsbranche oder an Banktransaktionen).
Interessanterweise lässt sich diese gewünschte Zielgranularität oft direkt in den Quellsystemen finden. Denn ein Telekommunikationsanbieter verfügt über ein operatives System, das jeden Telefonanruf aufzeichnet. Oder eine Bankanwendung, die jede Kontotransaktion aufzeichnet. Und diese Datensätze werden in der Regel ohne Aggregation in die data warehouse geladen (zumindest in der Data Vault, wo wir an der feinsten Granularität zu Prüfungs- und Lieferzwecken interessiert sind).
Und hier kommt das Problem mit den Standard Data Vault Entitätstypen. Sie sind zwar sehr einfach und nach einem Muster aufgebaut, haben aber ein Problem. Es ist die Tatsache, dass der Standard-Link "eine eindeutige Liste von Beziehungen speichert", wie oben erwähnt. Das bedeutet, dass der Link nur an Beziehungen aus der Quelle interessiert ist, die dem Ziel-Link unbekannt sind. Wenn ein Kunde mehrmals in ein Geschäft geht und das gleiche Produkt kauft, ist die Beziehung zwischen Kunde (Nummer), Geschäft (Nummer) und Produkt (Nummer) bereits bekannt, und es wird kein zusätzlicher Link-Eintrag hinzugefügt.
Infolgedessen wird die Granularität der eingehenden Daten beim Laden der Zielverbindung geändert. Wenn die der Transaktion zugrunde liegende Beziehung bereits bekannt ist, würde die Transaktion ausgelassen (und stattdessen von einem Satelliten erfasst) werden.
Das nächste Problem besteht darin, dass die Verknüpfungsgranularität nun von der Zielgranularität abweicht, weil der Geschäftsanalyst einen Datensatz pro Transaktion und nicht pro eindeutiger Geschäftsschlüsselbeziehung wollte. Es ist eine weitere Granularitätsverschiebung erforderlich, bei der in der Regel der Satellit der Verknüpfung mit der Verknüpfung selbst verbunden wird, um die ursprüngliche Granularität wiederherzustellen.
Wie wir in unserem Buch "Aufbau eines skalierbaren Data Warehouse mit Data Vault 2.0"Eine Kornverschiebung ist in Bezug auf die Leistung relativ kostspielig. Dies liegt daran, dass der Vorgang kostspielige GROUP BY-Anweisungen oder LEFT und RIGHT JOINS erfordert.
Und wofür? Das Endergebnis beider Operationen ist oft die ursprüngliche Granularität des Ausgangssystems. Zwei teure Kornverschiebungen für nichts klingt nach einem schlechten Geschäft.

Und das ist sie.
Hier kommt die nicht-historisierte Verknüpfung ins Spiel: Die Verknüpfung ist eine einfache Abwandlung der Standardverknüpfung mit dem Ziel, die Ursprungstransaktionen und -ereignisse in der ursprünglichen Granularität zu erfassen.
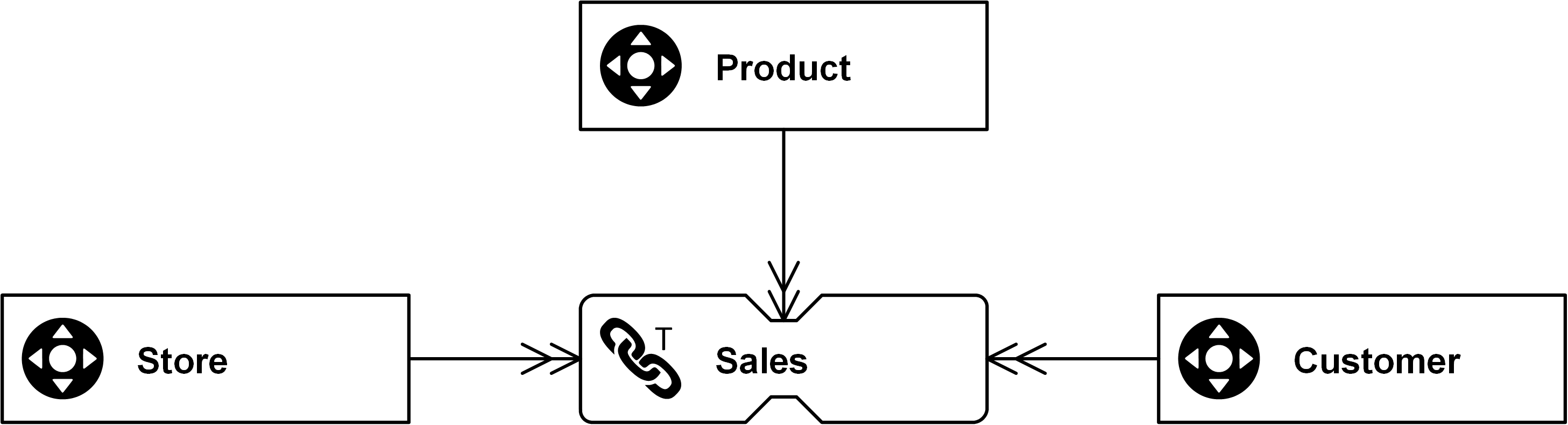

Abbildung: Nicht-historisierte Verknüpfung mit Verkaufs-ID als zusätzlicher Schlüssel
Ein tiefergehendes Szenario wäre, wenn dasselbe Produkt (in diesem Fall die höchste Granularität) zweimal in einem Verkauf auftaucht, z. B. aufgrund unterschiedlicher Rabatte. In diesem Fall wäre die Einzelpostennummer ein zusätzlicher Schlüssel (abhängiger untergeordneter Schlüssel), um jeden Datensatz eindeutig zu machen.
Aus Leistungsgründen sollten Kornverschiebungen auf dem Weg nach draußen vermieden werden. Wenn eine andere Zielgranularität erforderlich ist und es nicht möglich ist, diese Granularität aus dem Quellsystem oder aus dem Data Vault-Modell zu laden, sollte eine Brückentabelle in Betracht gezogen werden. Der Zweck dieses Entitätstyps besteht darin, die Granularitätsverschiebung zu materialisieren und gleichzeitig den Vorteil zu behalten, dass das Ziel entsprechend den individuellen Anforderungen an das Dimensionsziel angepasst werden kann.
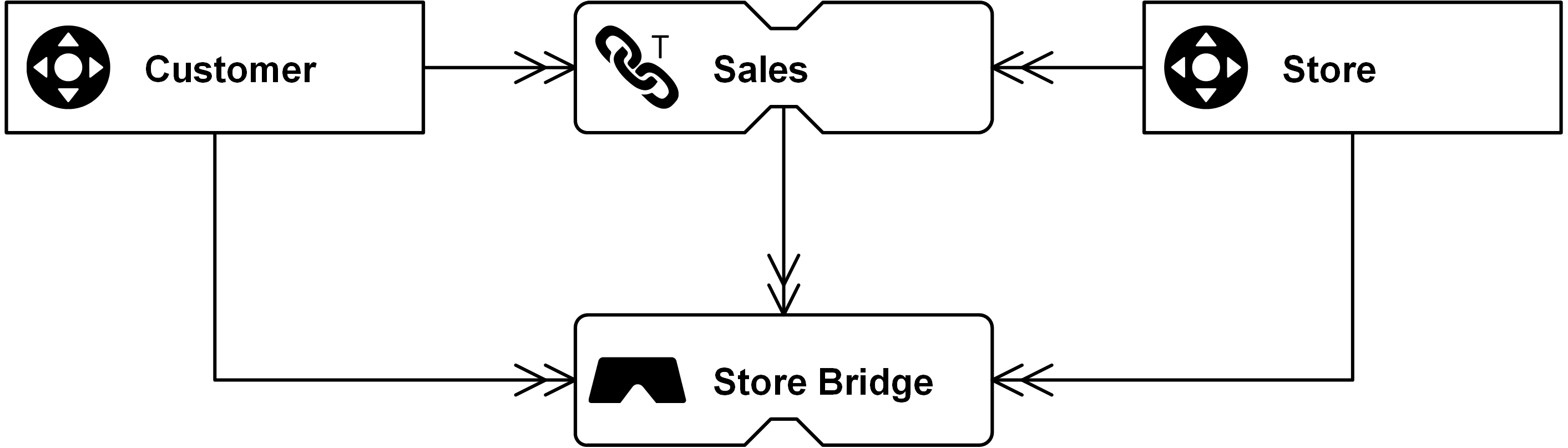
Abbildung: Virtuelle Bridge Table als Faktentabelle mit GROUP BY Store Hash Key



Was soll ich tun, wenn es keinen nützlichen zusätzlichen Schlüssel wie sales_id im Beispiel gibt?
Die Quelle liefert nur den Zeitstempel der Ladung?
Hallo Oliver,
unter der Annahme, dass die Transaktion selbst nicht mit einem Geschäftsprozess (wie einem Verkauf) zusammenhängt, sondern in Echtzeit von einer Maschine, einem Sensor oder ähnlichem kommt, können Sie eine Sequenz im NH-Link verwenden.
Mit freundlichen Grüßen,
Ihr Scalefree-Team
Da es keine Satelliten für NH-Link gibt und beschreibende Daten Teil davon sind, was ist, wenn irgendwelche Attribute hinzugefügt oder entfernt werden müssen, je nach Änderung der Quelldaten? Wird die Flexibilität dadurch nicht beeinträchtigt?
Hallo Siva,
Um einem nicht-historisierten Link beschreibende Daten hinzuzufügen, haben Sie zwei Möglichkeiten:
1. Lassen Sie die beschreibenden Attribute auf die Link-Entität denormalisieren
2. Ein "nicht-historisierter Satellit" (PK = HK des Elternteils, kein LDTS) muss mit einer 1:1-Beziehung an die Verbindung angeschlossen sein.
Wenn sich Ihre beschreibenden Daten ändern, verwandeln Sie sie in einen Standardsatelliten. Wenn sich die Attribute in der Verbindung im Laufe der Zeit ändern, verwenden Sie Gegentransaktionen.
Ich hoffe, das macht es ein bisschen klarer. Wir besprechen diese Themen in der Ausbildung viel ausführlicher (ich hoffe, Sie dort zu sehen 😉 )
Zum Wohl,
Mike
eine nicht-historisierte Verbindung unterstützt die Verwendung von "nicht-historisierten Satelliten" neben
Wenn ein Quellsystem Gegentransaktionen mit einem Verweis auf die ursprüngliche Transaktion enthält, die storniert wird, und wir sowohl die ursprüngliche Transaktion als auch die Gegentransaktionen in eine nicht-historisierte Verbindung laden, was wäre der bevorzugte Ansatz, um diesen Verweis zwischen der ursprünglichen und der vom Quellsystem erhaltenen Gegentransaktion zu erhalten?
Die einzigen Optionen, die mir einfallen, sind:
1) Ist dies einer der seltenen Fälle, in denen eine Verknüpfung gegen eine andere Verknüpfung verwendet wird, z. B. mit einer speziellen "Storno"-Verknüpfung, die die beiden nicht-historisierten Verknüpfungsdatensätze für ursprüngliche und gegenläufige Transaktionen miteinander verbindet - dies sollte das Laden der tatsächlichen Transaktionen in die nicht-historisierte Verknüpfung nicht verlangsamen, wenn sie nur dort geladen wird, wo sie in einem unabhängigen Prozess auftritt, führt aber zusätzliche Änderungsabhängigkeiten für die nicht-historisierte Verknüpfung ein, wenn auch ziemlich gezielt, da die zusätzliche Verknüpfung nur zweimal mit derselben nicht-historisierten Verknüpfung verbunden wird.
2) Dokumentieren Sie die Kennung der ursprünglichen Transaktion in einem nicht-historisierten Satelliten gegenüber dem nicht-historisierten Verknüpfungsdatensatz für die Gegentransaktion - dies erscheint mir ein wenig zu einfach, da eine echte Beziehung zwischen den beiden nicht-historisierten Transaktionen besteht, es sich nicht wirklich um eine rein beschreibende Information handelt und jeder Versuch, zwischen der ursprünglichen und der Gegentransaktion durch Verbrauchsprozesse zu navigieren, sehr ineffizient wäre.
Hallo Richard,
Die Empfehlung lautet hier, eine nicht historisierte Verknüpfung für beide Transaktionen zu verwenden, und der Prüfpfad wird in einer Same-As-Verknüpfung gespeichert. Wenn Ihr Quellsystem Zählertransaktionen mit Bezug auf die Originaltransaktion liefert, ist dies das beste Szenario, das Sie haben können, um das Laden so einfach wie möglich zu machen und gleichzeitig einen Prüfpfad zu haben. Dabei wird davon ausgegangen, dass jede Transaktion zusätzlich zur Originalreferenz eine konsistente singuläre ID (z. B. Transaktions-ID) hat. Verwenden Sie dieses Attribut als "abhängigen untergeordneten Schlüssel" (Teil des Links Hash Key, aber kein eigener Hub) und laden Sie die Zählertransaktion in denselben nicht-historisierten Link, wie sie von der Quelle kommt. Dabei wird davon ausgegangen, dass die Werte vom Quellsystem mit (-1) multipliziert werden, oder dass auf andere Weise erkannt wird, dass es sich um einen Gegenvorgang handelt. Laden Sie außerdem sowohl die Verknüpfung Hash Key aus dem ursprünglichen Datensatz als auch die Verknüpfung Hash Key aus dem Zählerdatensatz in eine Gleiche-als-Verknüpfung, um den Prüfpfad mit dem Gültigkeitsdatum zu erhalten.
Mit freundlichen Grüßen,
Ihr Scalefree-Team
Der SAL sollte sich in diesem Beispiel auf die Transaktions-ID beziehen, um Link-to-Link-Modelle zu vermeiden.
Ich habe einen Fall, in dem es keinen eindeutigen Schlüssel in den Quelldaten gibt. Bestimmte Stapelkorrekturen erzeugen mehrere identische Zeilen, die Gegenaktionen für Zeilen sind, die zu Beginn nicht identisch waren. Um es ein wenig zu vereinfachen, könnte es ein Gehalt geben, das im April und März gezahlt wurde, und dann eine Gehaltskorrektur im Mai, die 2 Zeilen erzeugt, die sagen wie: "Person A hat den falschen Betrag X erhalten" und 2 weitere Zeilen, die besagen: "Person A hätte den Betrag X erhalten müssen". Das Problem ist, dass der Stempel auf der Grundlage des Zeitpunkts der Korrektur und nicht des Zeitpunkts des korrigierten Ereignisses erfolgt, was diese Zeilen zu zwei Zeilenpaaren macht, die in jeder Spalte innerhalb des Paars identisch sind, einschließlich der Millisekunden des Stempels. Der Fall unterscheidet sich also von dem Beispiel Kunde - Produkt - Kauf und der ersten Frage in dem Sinne, dass es keine zeitliche Unterscheidung zwischen den gesetzlichen Vielfachen gibt. Wie gesagt, das ist eine starke Vereinfachung. Tatsächliche Daten haben im schlimmsten Fall Dutzende von identischen Zeilen, die als verschiedene Instanzen von Daten betrachtet werden müssen.
Meine Frage ist. Gibt es in einer solchen Situation eine Rettung, vorausgesetzt, es werden keine Änderungen am Quellsystem vorgenommen?
Hallo Jarmo,
Sie müssen erkennen, dass ein Datensatz ein "Gegenstück" zu einem Originaldatensatz ist (es gibt keinen Weg daran vorbei). Wenn Sie diese Informationen haben, können Sie die Gegensätze in die nicht-historisierte Verknüpfung einfügen. Sie müssen 2 Dinge hinzufügen/ändern: 1. Fügen Sie eine Zählerspalte mit dem Wert "1" für Originaldatensätze und "-1" für Zählersätze hinzu. 2. Der Zählerwert (1 oder -1) sowie der Zeitstempel des Ladedatums müssen zur Berechnung der Verknüpfung Hash Key hinzugefügt werden (alternativ können Sie nur die Zählerspalte hinzufügen und den Zeitstempel des Ladedatums als zusätzliche PK verwenden). Hier können Sie einen anderen Blogbeitrag sehen, in dem wir diese Situation behandeln: https://www.scalefree.com/scalefree-newsletter/delete-and-change-handling-approaches-in-data-vault-without-a-trial/
Ich hoffe, das hilft.
Marc
Ich habe einen Fall, in dem die Transaktionen (Dienstplaneinträge) im Laufe der Zeit Korrekturen erfahren können. Sie schlagen vor, in einem solchen Fall den Link in einen Standardsatelliten umzuwandeln, um den Verlauf zu erfassen. Ich frage mich jedoch, ob Sie tatsächlich einen Link-Satelliten anstelle eines Hub-Satelliten meinen. Ich kann den Sinn eines Hub-Satelliten nicht erkennen, wenn die Dienstplaneinträge als zusammengesetzter Schlüssel andere Hub-Einträge haben. Vielen Dank im Voraus.
Hallo Edwina,
Das hängt davon ab, was die Daten beschreiben. Wenn es sich um die Beziehung zwischen allen verbundenen Hubs handelt, dann ist es ein Link-Satellit, wenn du einen Hub (z.B. roster_hub) erstellt hast, zu dem die Daten passen, dann macht ein Hub-Satellit mehr Sinn. Das wird übrigens auch in unserem Boot Camp besprochen 😉 .
Mit freundlichen Grüßen,
Marc
NHL-Anwendungsfälle betreffen meist die Transaktionen als Ganzes. Wenn ein Unternehmen Transaktionen als Ganzes nach einigen Datenumwandlungsregeln analysieren muss, ist die vorgeschlagene Option ein Satellit. Da Transaktionen als Ganzes nicht unter einem einzigen Hub zusammengefasst werden können, werden sie in den meisten Fällen unter einem Link zusammengefasst. Da es sich um business vault-Satelliten handelt, müssen sie Änderungen der Geschäftsregeln zulassen und sind daher veränderbar. Dies ist ziemlich einfach, solange die Transaktionen eindeutig mit einer Kombination von Hubs identifiziert werden können, die den normalisierten Link bilden.
Wenn die Transaktionen nicht mit einer Kombination von Hubs identifiziert werden können (auch nicht mit degenerierten Schlüsseln) und ein ganzer Satz von Spalten der NHL zur eindeutigen Identifizierung erforderlich ist, wird die business vault-Verknüpfung letztendlich die NHL selbst sein. In diesem Fall muss diese Business Vault NHL aktualisierbar sein, um Änderungen der Geschäftsregeln zu ermöglichen.
Hallo!
Ich habe einen Anwendungsfall, bei dem ich keine beschreibenden Attribute für den Link habe, aber ich möchte einen Verlauf der Beziehung zu diesem Link verfolgen.
Sollte ich Satellite ohne beschreibende Attribute verwenden, das nur Einfügungen und Löschungen verfolgt?
Hallo Daniil,
Hierfür sollten Sie einen Gültigkeits-Satelliten verwenden, der aufzeichnet, welche Beziehung zu welchem Zeitpunkt gültig ist/war (basierend auf den ldts). Ich glaube, das ist es, was Sie brauchen: https://www.scalefree.com/scalefree-newsletter/handling-validation-of-relationships-in-data-vault-2-0/. Ich hoffe, das hilft.
-Marc
Hallo zusammen,
Ich stehe vor dem folgenden Anwendungsfall, bei dem ich DataVault als Entwurfsmethodik verwenden möchte:
Ich habe eine Message Broker-Quelle (Solace) System, das Nachrichten über Broker in PPMP-Protokoll (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
Ich habe die eingehenden Daten in einem Staging-Bereich gespeichert, der ungefähr die folgende Struktur hat:
message_id---queue----message (Speicherung der Nachricht in json )--load_date---source_system---some_audit_cols
1 Warteschlange1 {"Gerät": {}, "Teil":{}, {"Messungen": [] usw}} 20220619010000 SRC1 audit vals
2 Warteschlange1 {"Gerät": {}, "Teil":{}, {"Messungen": [] usw}} 20220619010000 SRC1 audit vals
1 Warteschlange1 {"Gerät": {}, "Teil":{}, {"Messungen": [] usw}} 20220619020000 SRC1 audit vals
Das Unternehmen möchte ein Startschema in Information Marts haben, das dem Modell des PPMP-Protokolls (https://www.eclipse.org/unide/specification/v3/process-message#messageDetail).
Ist es ein guter Ansatz, diese Datennachrichten im Rohdatenspeicher zu entwerfen, indem nur ein nicht-historisierter Link verwendet wird? Der Link enthält: lnk_hk, hub_device_hk, hub_part_hk, message_id, message etc.
In diesem Link werden nämlich alle Daten gespeichert, auch die beschreibenden Felder (Nachricht, Warteschlange usw.). Es sind keine Link-Satelliten erforderlich, da es keine Historie für eingehende Nachrichten gibt.
Die identifizierten Hubs sind: hub_device, hub_part (mit ihren eigenen Satelliten)
Danach sollte ich auch einige business vault-Entitäten erstellen, die anderen Information Marts helfen können, die KPIs einfach und schnell zu berechnen.
Ich freue mich auf Ihr Feedback.
Herzliche Grüße,
Laurentiu
Hallo Laurentiu,
das klingt alles gut 🙂
-Marc
Ich habe einen Fall, in dem das Quellsystem 2 Datensätze sendet. Der erste Datensatz enthält den Schlüssel und sein Attribut. Der zweite Datensatz enthält verschiedene Transaktionen für einen bestimmten Schlüssel. Der zweite Datensatz kann den Schlüssel enthalten oder auch nicht. Zum Beispiel enthält der erste Datensatz die Kontonummer und der zweite Datensatz die mit einer bestimmten Kontonummer verbundenen Transaktionen. Nun kann es vorkommen, dass der zweite Datensatz keine Kontonummer enthält, weil keine Meldung aufgetreten ist. Und schließlich können die vorhandenen txns auch aus der Quelle aktualisiert werden. Das zweite Dataset hat auch eine Reihe von Attributen zusammen mit der txn id. Jetzt habe ich einen Hub (Hub-Konto) erstellt, aber ich stehe vor dem Problem, wie ich den zweiten Datensatz modellieren kann.
- Nach meinem Verständnis kann der zweite Datensatz nicht direkt mit dem Hub verbunden sein, da die Körnung unterschiedlich ist.
- Ein anderer Ansatz, den ich in Erwägung ziehe, ist ein Transaktions-Link (mit Kontonummer und txn id) und dann ein txn-Link-Sat (aber dieses Sat wird als normales Sat für den Link fungieren, da eine bestimmte txn später aktualisiert werden kann. Der Satellit enthält also mehrere Datensätze für eine Transaktion, von denen jedoch nur einer aktiv oder aktuell ist.)
Können Sie mir bitte mitteilen, ob dieser Ansatz in Ordnung ist, oder ob es einen besseren Ansatz gibt? Vielen Dank im Voraus
Hallo Kapil,
Unterschiedliche Körnung bedeutet unterschiedlichen Hub, oder in Ihrem Fall einen anderen nicht-historisierten Link, der die Transaktionsnummer als zusätzlichen Schlüssel enthält. Ihr zweiter Ansatz klingt plausibel. Eine andere Möglichkeit wäre, die Transaktion als eigenen Hub zu modellieren und den Standard-Satelliten daran zu hängen.
Ich hoffe, das hilft.