
Data Vault 2.0 mit dbt
In diesem Artikel geht es um die Vorteile der Verwendung von Data Vault 2.0 mit dbt sowie um die Bedeutung der Wahl geeigneter Implementierungswerkzeuge. Daten sind ein zentraler Bestandteil fundierter Entscheidungsprozesse. Wie wir bereits in einem früheren Beitrag erläutert haben, ist Data Vault 2.0 die richtige Wahl, wenn ein Enterprise Data Warehouse vollständig historisierte und integrierte Daten bereitstellen soll. Darüber hinaus eignet sich Data Vault 2.0 besonders dann, wenn Daten aus einer Vielzahl von Quellsystemen zusammengeführt werden müssen. Den vorherigen Blogbeitrag finden Sie hier.
Während sich Data Vault 2.0 auf das „Was“ konzentriert, gibt es zahlreiche Möglichkeiten für das „Wie“ – also für die technische Umsetzung eines Data Vault-Modells in physische Tabellen und Views im Enterprise Data Warehouse sowie für die Orchestrierung und das Laden bzw. Verarbeiten der entsprechenden Prozesse. Und genau an diesem Punkt bietet die Kombination von Data Vault 2.0 mit dbt eine besonders effektive Lösung.
Über dbt
Dieses Data Build Tool transformiert Ihre Daten direkt im Data Warehouse. Zur Einordnung: dbt steht für das „T“ in ELT. Das bedeutet, dbt geht davon aus, dass die Daten bereits in eine Datenbank geladen wurden, auf die zugegriffen werden kann. Im Gegensatz dazu folgt ETL einem anderen Ablauf: Zuerst werden die Daten extrahiert, dann transformiert und schließlich in das Zielsystem geladen. Bei ELT hingegen erfolgt die Transformation erst nachdem die Daten im Data Warehouse angekommen sind.(mit „Transformation“ meinen wir in diesem Kontext die Anwendung von soft Business rules, also Regeln, die die Bedeutung der Daten verändern können. Natürlich muss auch bei ELT sichergestellt werden, dass die Daten in die Zieltabelle passen (z. B. durch Anpassung von Datentypen). Solche Anpassungen fallen unter sogenannte "Hard rules".)
Dbt eignet sich besonders gut für Cloud DWH-Lösungen wie Snowflake, Azure Synapse Analytics, BigQuery, und Redshift. Es führt Transformationen und Datenmodellierung direkt in der Datenbank aus und nutzt dabei gezielt die hohe Leistungsfähigkeit und Skalierbarkeit dieser Plattformen.
Wie dbt funktioniert
Modelle und SQL-Statements können direkt in dbt einfach erstellt, getestet und verwaltet werden. Eine leistungsstarke Kombination aus der Skriptsprache Jinja2 und klassischen SQL ermöglicht es Nutzern, Modelle flexibel aufzubauen. Dank der benutzerfreundlichen Oberfläche können auch Datenanalysten ohne tiefgehendes technisches Know-how Transformationen eigenständig anstoßen. Die Arbeitsabläufe im Datenteam werden dadurch effizienter und kostengünstiger. Hinter dbt steht eine aktive Open-Source-Community, die das Tool kontinuierlich und mit großer Leidenschaft weiterentwickelt. dbt ist sowohl als kostenlose, reduzierte Core Version als auch als umfassende, flexible Cloud Version verfügbar.
Wie funktioniert Data Vault 2.0 mit dbt?
Ein zentraler Bestandteil der Data Vault 2.0 Methodologie ist das Modell, das sich darauf konzentriert, wie sich das Kern-Data-Warehouse skalierbar gestalten lässt. Die Kernelemente von Data Vault sind Hubs, Links und Satelliten. Die Kombination von Data Vault 2.0 mit dbt bietet die Möglichkeit, Data Vault Modelle zu generieren und Transformationen mithilfe von SQL sowie wiederverwendbaren Makros – unterstützt durch Jinja2 – zu schreiben. So lassen sich Datenpipelines strukturiert und effizient ausführen.
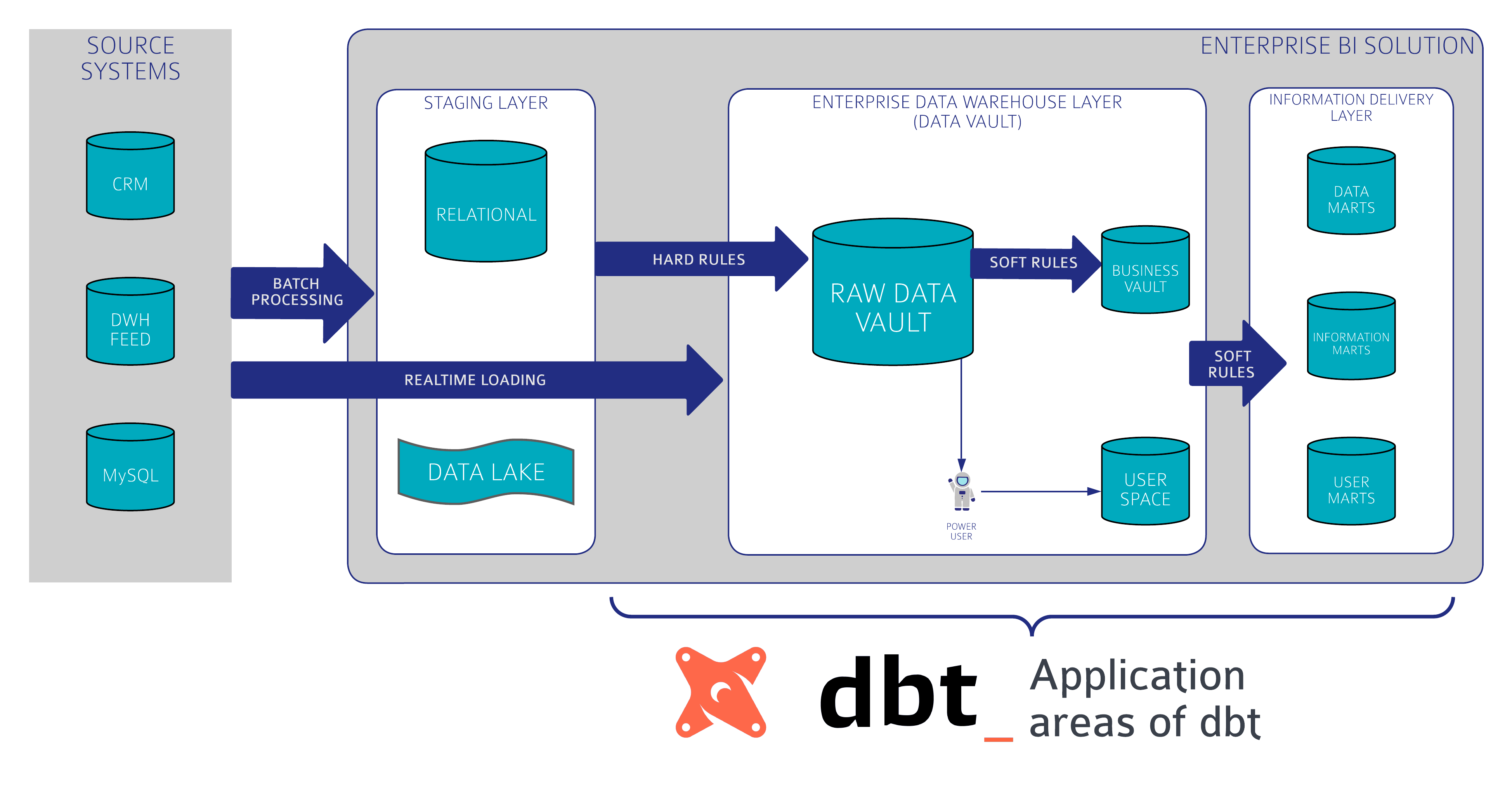
Fazit
Dbt erfindet das Rad nicht neu – aber wenn es darum geht, ein neues EDW aufzubauen, insbesondere in der Cloud, bietet es ein äußerst hilfreiches Grundgerüst. Viele wichtigen Funktionen für CI/CD sind bereits integriert und vorkonfiguriert. Dbt bringt bewährte Standards der Softwareentwicklung in die Welt der Datentransformation. So können sich Entwickler auf die wesentlichen Aufgaben der Datenmodellierung und der Umsetzung von Geschäftslogik konzentrieren. Gerade – aber nicht nur – für kleinere Projekte stellt dbt eine leichtgewichtige und äußerst kostengünstige Alternative zu anderen Data Warehouse Automatisierungstools.
- von Ole Bause (Scalefree)
Hi Ole,
since you mention dbt in the context of the Data Vault, it’s not clear whether you actually meant dbtvault, which supports the Raw Vault structures, but does not, for example, currently support Azure Synapse Analytics, or whether your intention was to recommend using the generic dbt for generating the Raw Vault structures. Could you clarify?
Thanks,
Gideon
Hi Gideon,
this article just describes how you can benefit from using dbt in your Data Vault project in general.
AutomateDV(formerly dbtvault) is currently not planning to support Synapse in the future and has also some drawbacks e.g. in loading patters that are not consistent with the Data Vault 2.0 standards.
We have released our own package datavault4dbt which is fully compliant with data vault 2.0 standards and also supports more entity types and we are currently working on Synapse support for our package. I can definetely recommend using this package.
If you can’t wait until the support is released you would need to implement everything by your own. Then you should definetely take use of macros to have repeatable patterns to generate your raw vault structures.