Im ersten Teil dieser Blogserie haben wir Ihnen das dbt vorgestellt. Jetzt schauen wir uns an, wie Sie dbt implementieren können Data Vault 2.0 mit dbt und welche Vorteile dies mit sich bringt. Wenn Sie den ersten Teil noch nicht kennen, können Sie ihn lesen hier:
dbt bietet die Möglichkeit, Modelle zu erstellen und aus diesen Modellen dynamisch SQL zu generieren und auszuführen. So können Sie Ihre Datentransformationen in Modellen mit SQL und wiederverwendbaren Makros auf Basis von Jinja2 schreiben, um Ihre Datenpipelines sauber und effizient auszuführen. Der wichtigste Teil für den Anwendungsfall Data Vault ist jedoch die Möglichkeit, diese Makros zu definieren und zu verwenden.
Doch zunächst sollten wir klären, wie Modelle im dbt funktionieren.
Dbt übernimmt die Kompilierung und Ausführung von Modellen, die mit SQL und der Makrosprache Jinja geschrieben wurden. Jedes Modell besteht aus genau einer SQL SELECT-Anweisung. Der Jinja-Code wird während der Kompilierung in SQL übersetzt.
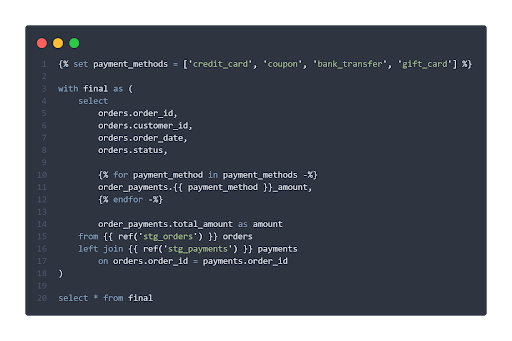
Diese Abbildung zeigt ein einfaches Modell in dbt. Ein großer Vorteil von Jinja ist die Möglichkeit, SQL programmatisch zu generieren, zum Beispiel mit Schleifen und Bedingungen. Außerdem versteht dbt durch die ref()-Funktionen die Beziehungen zwischen den Modellen und erstellt einen Abhängigkeitsgraph. Dadurch wird sichergestellt, dass die Modelle in der richtigen Reihenfolge erstellt werden und dass die Datenherkunft dokumentiert ist.
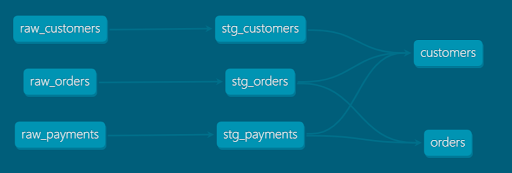
Ein Abstammungsdiagramm kann wie folgt aussehen:
Die Materialisierung von Modellen kann auf verschiedenen Konfigurationsebenen definiert werden. Dies ermöglicht ein schnelles Prototyping mit Ansichten und den Wechsel zu materialisierten Tabellen, wenn dies aus Leistungsgründen erforderlich ist.
Data Vault 2.0 und Makros
Aber wie kann Data Vault 2.0 in dbt implementiert werden? Der wichtigste Teil für die Verwendung von Data Vault 2.0 ist die Möglichkeit, Makros zu definieren und zu verwenden. Makros können in Modellen aufgerufen werden und dann in diesem Makro zusätzliches SQL oder sogar den gesamten SQL-Code erzeugen.
Sie könnten z. B. ein Makro erstellen, um einen Hub zu generieren, der das Quell-/Staging-Modell als Eingabeparameter sowie die Spezifikation der Spalten für den/die Geschäftsschlüssel, das Ladedatum und die Datensatzquelle erhält. Der Sql-Code für den Hub wird dann dynamisch daraus generiert. Dies hat den Vorteil, dass sich eine Änderung des Makros direkt auf jeden einzelnen Hub auswirkt, was die Wartungsfreundlichkeit erheblich verbessert.
An dieser Stelle profitieren Sie auch von der aktiven Open-Source-Gemeinschaft rund um dbt. Es gibt viele Open-Source-Pakete, mit denen dbt erweitert werden kann.
Es gibt auch bereits einige Pakete, die sich perfekt für die Verwendung von data vault 2.0 eignen.
Wir bei Scalefree entwickeln derzeit ein quelloffenes dbt-Paket, das Makros bereitstellt, um ein Data Vault-Modell "auf Papier" in tatsächliche Tabellen und Ansichten wie Hubs, Links, Satelliten und mehr zu übersetzen. Abonnieren Sie unseren Newsletter, um benachrichtigt zu werden, sobald er verfügbar ist.
Das Einzige, was Sie in Ihrem Modell brauchen, zum Beispiel für einen Hub, ist ein einziger Makroaufruf:
{%- hub(src_pk, src_nk, src_ldts, src_ource, source_model) -%}
Mit den Parametern des Makroaufrufs definieren Sie die Quelltabelle, in der die Spalten zu finden sind (source_model), und die Spaltennamen für den Hash-Schlüssel (src_pk), den/die Business-Schlüssel (src_nk), das Ladedatum (src_ldts) und die Datensatzquelle (src_source). Wenn das Modell und das/die im Modell definierte(n) Makro(s) ausgeführt werden, wird das SQL kompiliert und auf dem Datenbanksystem verarbeitet.
Die benötigten Metadaten können zum Beispiel in Variablen mit jinja direkt im Modell definiert werden:
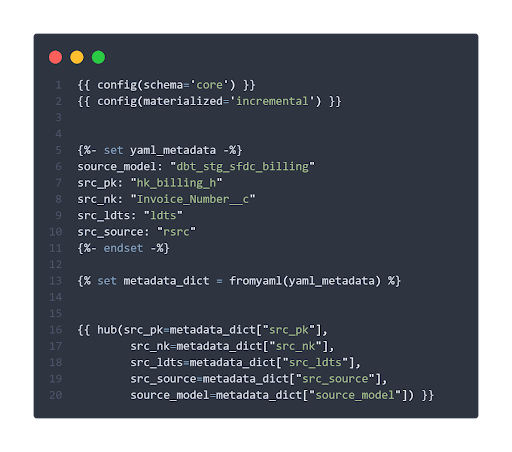
Sie können auch sehen, dass dbt verschiedene Optionen für die Materialisierung bietet. Die inkrementelle Materialisierung beispielsweise lädt eine Entität als Tabelle auf inkrementeller Basis.
Wenn das Modell ausgeführt wird, generiert dbt die gesamte Sql aus dem Makro und entscheidet, wie die Datensätze geladen werden. Wenn die Hub-Tabelle noch nicht existiert, wird sie erstellt und alle Datensätze werden geladen, wenn sie bereits existiert, wird die Tabelle inkrementell geladen.
Wer schon einmal versucht hat, eine Data Vault mit "Vanilla"-SQL zu implementieren, wird feststellen, dass dies eine echte Neuerung ist. Das Team kann sich nun voll und ganz auf das Data Vault-Design selbst konzentrieren. Sobald die Metadaten identifiziert sind, kann dbt zusammen mit Ihren Makros die gesamte Logik übernehmen.
Offen verfügbare Pakete können grundlegende Data Vault 2.0-Prinzipien zu dbt hinzufügen und ermöglichen so den schnellen Einstieg in die Data Vault-Implementierung. Die allgemeine Offenheit von dbt ermöglicht es Ihnen, alle Makros beispielsweise an Ihren unternehmens- oder projektspezifischen Data Vault-Geschmack anzupassen, um Ihre technischen und geschäftlichen Anforderungen zu erfüllen.
Es ist jedoch wichtig zu erwähnen, dass die bestehenden dbt-Pakete für Data Vault 2.0 die Data Vault 2.0-Standards nicht vollständig erfüllen und in Details von ihnen abweichen. Derzeit arbeiten wir bei Scalefree an einem Open-Source dbt-Paket, das alle wichtigen Data Vault 2.0-Entitäten sowie die neuesten Standards und Best Practices enthält und in Kürze veröffentlicht werden soll. Aber diese Details sind einen weiteren Blogbeitrag wert!
-von Ole Bause (Scalefree)
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.