In Fortsetzung unserer fortlaufenden Serie wird dieser Teil der Blogserie die Grundlagen der Abfrage und Änderung von Daten in MongoDB mit Schwerpunkt auf den Grundlagen, die für die Data Vault-Last erforderlich sind, sowie auf Abfragemustern.
Im Gegensatz zu den von relationalen Datenbanken verwendeten Tabellen verwendet MongoDB ein JSON-basiertes Dokumentdatenmodell. Dokumente sind daher eine natürlichere Art, Daten als eine einzige Struktur darzustellen, in der verwandte Daten als Unterdokumente und Arrays eingebettet sind, was ansonsten in einer relationalen Datenbank in Eltern-Kind-Tabellen aufgeteilt ist, die durch Fremdschlüssel verknüpft sind. Sie können Daten auf jede beliebige Weise modellieren, die Ihre Anwendung erfordert - von umfangreichen, hierarchischen Dokumenten bis hin zu flachen, tabellenähnlichen Strukturen, einfachen Schlüssel-Wert-Paaren, Text, Geodaten und den bei der Graphenverarbeitung verwendeten Knoten und Kanten.
Um die Abfragen zu beschleunigen, können die in den Dokumenten gespeicherten Daten jedoch anhand beliebiger Attribute indiziert werden:
- Der Primärindex ist in jeder Sammlung vorhanden, das Attribut _id.
- Zusammengesetzte Indizes ermöglichen die Indizierung gegen mehrere Schlüssel im Dokument.
- MultiKey-Indizes werden für Array-Werte verwendet.
- Wildcard-Indizes indizieren automatisch alle übereinstimmenden Felder, einschließlich Unterdokumente und Arrays.
- Unterstützung von Textindizes für Textsuchen mit zusätzlichen Volltextsuchfunktionen auf der Grundlage von Lucene in MongoDB Atlas.
- GeoSpatial Indexes für räumliche Geometrien.
- Hash-Indizes für das Sharding, d.h. die horizontale Skalierung.
Indizes nutzen zusätzliche Funktionen, um entweder erweiterte Anwendungsfälle zu unterstützen oder die Indexgröße zu reduzieren:
- Einzigartige Indizes stellen sicher, dass ein Wert nicht doppelt vorhanden ist.
- Partielle Indizes ermöglichen Indizes auf Teilmengen von Daten auf der Grundlage von Ausdrücken.
- Sparse Indexes indizieren nur Dokumente, die das angegebene Feld enthalten.
- TTL-Indizes löschen ein Dokument, wenn es abgelaufen ist.
- Case Insensitive Indizes unterstützen die Suche nach Daten.
Da dies der Fall ist, erfordert die Fähigkeit, Daten in komplexen Strukturen zu modellieren, eine leistungsfähige Sprache für CRUD-Operationen.
Die MongoDB Query Language (MQL) ermöglicht es, aussagekräftige Abfragen für polystrukturierte Dokumente zu erstellen, z. B. "Finde alle Personen mit einer Telefonnummer, die mit '1-212*' beginnt" oder "Überprüfe, ob die Person mit der Nummer '555-444-333' auf der 'Nicht anrufen' Liste steht".
Es gibt auch Mittel zum Einfügen, Aktualisieren und Einfügen von Daten, d.h. wenn ein Dokument nicht vorhanden ist, wird es eingefügt, die in diesem Artikel nicht behandelt werden. Weitere Einzelheiten entnehmen Sie bitte der Dokumentation hier klicken.
Die neueste Version, MongoDB 4.2, unterstützt auch die Verwendung von Aggregations-Pipeline-Stufen in Aktualisierungsanweisungen, wie in diesem Beispiel zu sehen Dokument. Aggregationspipelines sind fortschrittliche Datenverarbeitungspipelines, die für Datenumwandlungen und Analysen verwendet werden. In diesem Fall durchlaufen die Dokumente eine mehrstufige Pipeline, die die Dokumente in aggregierte Ergebnisse umwandelt. Das erfordert ein wenig Laufarbeit, und so besteht eine Aggregationspipeline aus mehreren Stufen, wobei jede Stufe die Dokumente umwandelt, während sie die Pipeline durchlaufen. Die einzelnen Phasen der Pipeline müssen nicht für jedes Eingabedokument ein Ausgabedokument erzeugen; z. B. können einige Phasen neue Dokumente erzeugen oder Dokumente vollständig herausfiltern.
Die folgende Abbildung zeigt ein Beispiel für eine Aggregationspipeline mit zwei Stufen für die Auftragssammlung. Die Stufe $match filtert die Dokumente nach dem Status und leitet diejenigen Dokumente an die nächste Stufe weiter, die ein Status gleich "A". Die Stufe $group gruppiert die Dokumente nach dem cust_id Feld, um die Summe der Betrag für jede einzelne cust_id.
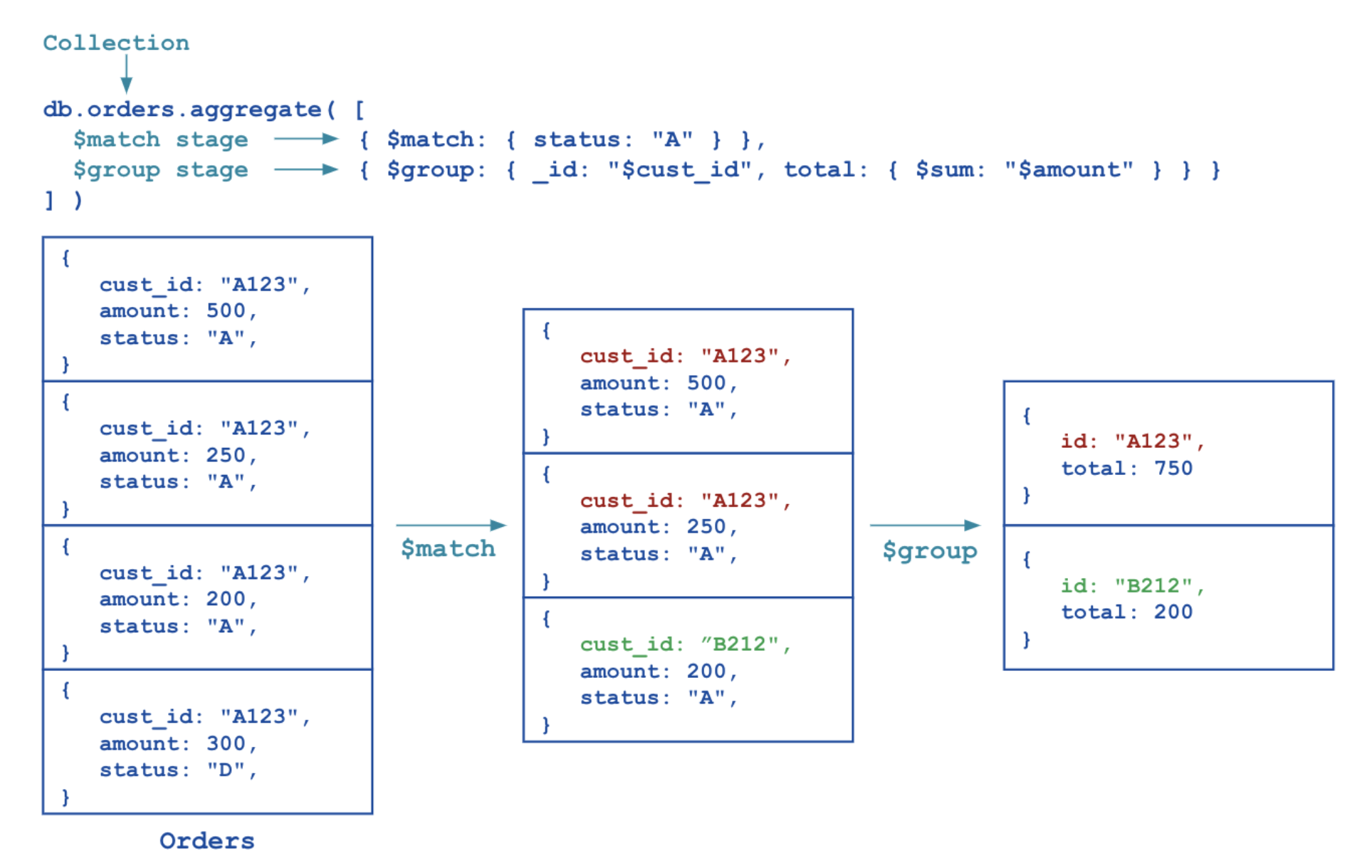
Bitte beachten Sie, dass Pipelinestufen mehrfach in einer einzigen Pipeline vorkommen können.
Eine Liste aller verfügbaren Stufen finden Sie unter Stufen der Aggregationspipeline.
Die folgenden Stufen werden in den data vault-Mustern verwendet:
- $match: Filtert die Dokumente, um nur die Dokumente, die die angegebene(n) Bedingung(en) erfüllen, an die nächste Pipelinestufe weiterzuleiten.
- $Projekt: Leitet die Dokumente mit den angeforderten Feldern an die nächste Stufe der Pipeline weiter. Die angegebenen Felder können vorhandene Felder aus den Eingabedokumenten oder neu berechnete Felder sein.
- $unwind: Dekonstruiert ein Array-Feld aus den Eingabedokumenten, um für jedes Element ein Dokument auszugeben. Jedes Ausgabedokument ist das Eingabedokument, wobei der Wert des Array-Feldes durch das Element ersetzt wird.
- $Gruppe: Gruppiert Dokumente nach einem bestimmten Ausdruck und gibt in der nächsten Stufe ein Dokument für jede eindeutige Gruppierung aus. Die Ausgabedokumente enthalten ein _id-Feld, das die eindeutige Gruppierung nach Schlüssel enthält. Die Ausgabedokumente können auch berechnete Felder enthalten, die die Werte einiger Akkumulatorausdrücke wie min/max/avg/sum/etc enthalten, die alle durch das _id-Feld der $group gruppiert sind.
- $lookup: Führt eine linke äußere Verknüpfung mit einer nicht gesharten Sammlung in derselben Datenbank durch, um Dokumente aus der "verknüpften" Sammlung zur Verarbeitung herauszufiltern. Für jedes Eingabedokument fügt die Stufe $lookup ein neues Array-Feld hinzu, dessen Elemente die übereinstimmenden Dokumente aus der "joined"-Sammlung sind. Die $lookup-Stufe übergibt diese umgestalteten Dokumente an die nächste Stufe.
Darüber hinaus können die Stufen $out und $merge verwendet werden, um das Ergebnis einer Aggregationspipeline in neue oder bestehende Sammlungen zurückzuschreiben.
Es gibt eine Vielzahl von Operatoren, um Daten von Dokumenten zu verändern (https://docs.mongodb.com/manual/reference/operator/aggregation/): mathematische Operationen, Array-Modifikatoren, Bedingungen, Datumsoperationen, String-Modifikation, Typkonvertierungen, reguläre Ausdrücke und Trigonometrie.
Bleiben Sie dran - der nächste Beitrag in unserer Serie beschreibt, wie Sie Aggregationspipelines zum Laden von Hubs verwenden. Wenn Sie mehr über die Abfrage von Daten und die Verwendung von Aggregationspipelines in MongoDB erfahren möchten, besuchen Sie bitte die Kurse der MongoDB University: M001: MongoDB-Grundlagen und M121: Das MongoDB Aggregation Framework.
Fragen? Kommentare?
Wir würden uns freuen, von Ihnen im Kommentarbereich unten zu hören!
Wie Sie Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.