Letztes Jahr veröffentlichte Scalefree DataVault4dbt, a Data Vault 2.0 Open-Source-Paket für dbt, das Ladevorlagen für die Erstellung und Data Vault 2.0 Modellierung Einheiten, die aktuellen Standards und bewährten Verfahren folgen. Wenn Sie mehr über den allgemeinen Inhalt des Pakets und seine Motivation erfahren möchten, können Sie dies tun hier.
Wir freuen uns, eine Reihe von aufschlussreichen Beiträgen und Webinaren starten zu können, in denen die praktische Umsetzung von DataVault4dbt. So können Sie das volle Potenzial des Programms bei Ihren data warehousing-Bemühungen nutzen. Heute werden wir seine Anwendung in den folgenden Bereichen beleuchten Bereitstellungsschicht.
Bevor wir anfangen...
Wir setzen einige Vorkenntnisse in Bezug auf Data Vault 2.0 und dbt voraus. Außerdem werden wir für die folgenden Beispiele Folgendes verwenden dbt Cloud IDE verbunden mit Snowflake. Eine aktuelle Liste der unterstützten Plattformen finden Sie auf der Github-Repository des Pakets.
Denken Sie auch daran, dass Sie für eine optimale Nutzung der Makros einige Voraussetzungen erfüllen müssen:
- Flache und breite Quelldaten, die in Ihrer Zieldatenbank zugänglich sind
- eine Spalte "Ladedatum", die den Zeitpunkt des Eintreffens im Quelldatenspeicher angibt
- Eine Datensatzquellenspalte, die den Ursprung der Quelldaten angibt, wie z. B. den Dateispeicherort innerhalb einer Data Lake
In unserem Fall haben wir die Daten aus dem jaffle_shop Beispielprojekt verfügbar im dbt.
Installation des DataVault4dbt-Pakets auf dbt
Die Installation von DataVault4dbt erfolgt wie die Installation jedes anderen Pakets in Ihrem Projekt. Sie müssen folgen zwei einfache Schritte:
1.Hinzufügen in Ihre Datei packages.yml aufnehmen
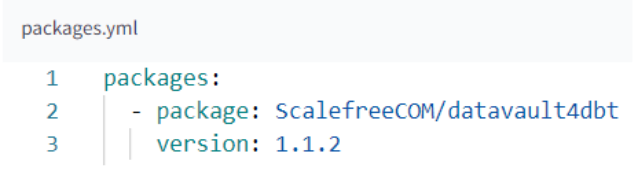
2. ausführen. dbt deps

Verwendung des Makros für die Bereitstellung unserer Quelldaten
Nach Angaben der Dokumentation für die Staging-Ebene von DataVault4dbt konzentriert sich diese Schicht hauptsächlich auf Hashing. Es bietet auch Funktionen wie die Erstellung abgeleiteter Spalten, die Durchführung von Prejoins und das Hinzufügen von NULL-Werten für fehlende Spalten. Anstatt tief in die technischen Aspekte jeder Makrokomponente einzutauchen, die in der Dokumentation ausführlich behandelt werden, lassen Sie uns direkt in ihre Anwendung eintauchen!
A. Grundlegende Informationen zur Quelle
Identifizierung des Quellmodells (source_model):
- Wenn Sie auf eine Quelle verweisen, verwenden Sie das Wörterbuchformat: 'quelle_name': 'quelle_tabelle'.
- Für Modelle innerhalb unseres dbt-Projekts verwenden Sie einfach den Modellnamen: "source_table".
Einstellung des Zeitstempels für das Ladedatum (ldts) & Quelle aufzeichnen (rsrc):
- Beide können auf eine Spalte aus der Quelltabelle oder einen detaillierteren SQL-Ausdruck verweisen.
- Außerdem können Sie für die Datensatzquelle eine statische Zeichenfolge verwenden, die mit '!' beginnt, z. B. '!my_source'.
Beispiel
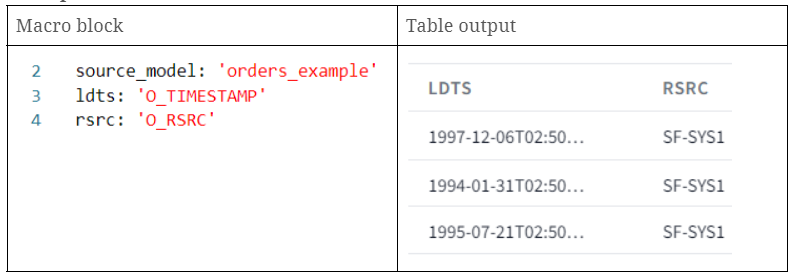
- source_model: Ruft eine bereits erstellte Tabelle auf dbt mit dem Namen "orders_example" auf.
- ldts: Ruft eine Zeitstempelspalte aus unserem Quellmodell auf.
- rsrc: Ruft eine Spalte auf, die eine Zeichenkette enthält, die sich auf den Namen unserer Datensatzquelle bezieht.
B. Hashing
In DataVault4dbt wird die hashed_columns gibt an, wie Hashkeys und Hashdiffs zu erzeugen sind. Für jede Hash-Spalte:
- Der Schlüssel stellt den Namen der Hash-Spalte dar.
- Bei Hashkeys ist der Wert eine Liste von Geschäftsschlüsseln.
- Bei Hashdiffs ist der Wert in der Regel eine Liste von beschreibenden Attributen.
Beispiel
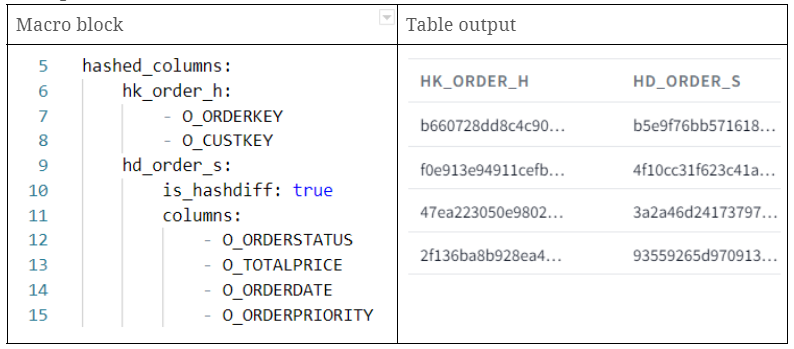
- hk_order_h: Hashkey, der unter Verwendung von zwei Eingangsspalten (O_ORDERKEY und O_CUSTKEY) erzeugt wird
- hd_order_s: mit mehreren beschreibenden Attributen erzeugter Hashdiff
C. Abgeleitete Spalten
Abgeleitete Spalten in DataVault4dbt-Stufenmodellen ermöglichen es Benutzern, bestimmte Transformationen direkt auf Daten anzuwenden. Sie fungieren als fliegende Anpassungen und ermöglichen sofortige Anpassungen der Daten in der Spalte selbst. Wenn Daten nicht im gewünschten Format vorliegen, können Sie mit DataVault4dbt eine neue Version direkt in der Spalte anhand einer bestimmten Regel ableiten.
Bei der Einstellung der abgeleitete_spalten Parameter enthält jede abgeleitete Spalte:
- Wert: Der Ausdruck der Transformation.
- Datentyp: Der Datentyp der Spalte.
- src_cols_required: Für die Transformation benötigte Quellspalten.
Je nachdem, wie Sie die abgeleitete Spalte und die Ausgangsspalten benennen, können Sie zwei Ergebnisse erzielen:
- Wenn der Name der abgeleiteten Spalte mit dem Namen der Quellspalte übereinstimmt, werden die Daten der ursprünglichen Spalte durch die umgewandelten Daten ersetzt. Dies bedeutet, dass Sie die ursprünglichen Daten überschreiben.
- Wenn der Name der abgeleiteten Spalte jedoch nicht mit dem Namen der Ausgangsspalte übereinstimmt, führt die Umwandlung zu einer völlig neuen Spalte, wobei die Daten der ursprünglichen Spalte erhalten bleiben.
Beispiel
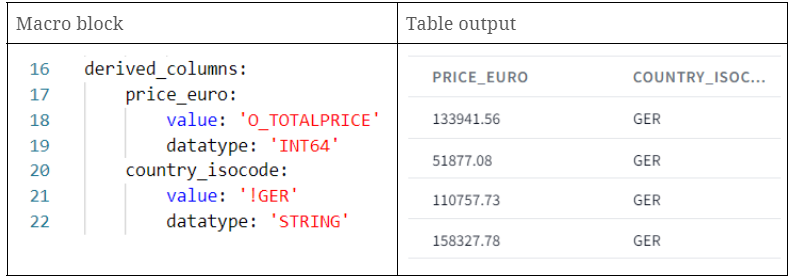
- price_euro: Erstellung einer neuen Spalte mit denselben Werten wie in der Spalte O_TOTALPRICE.
- country_isocode: Erstellung einer neuen Spalte mit einem statischen String 'GER'.
D. Vorverbindung
Warum Prejoin?
In bestimmten Szenarien verfügen Ihre Quelldaten möglicherweise nicht über den "Business Key", bei dem es sich häufig um einen von Menschen lesbaren Bezeichner handelt, z. B. eine E-Mail-Adresse oder einen Benutzernamen. Stattdessen können sie einen "technischen Schlüssel" haben, der ein intern generierter Bezeichner oder Code sein kann. Wenn Sie in Ihrer Verarbeitung den von Menschen lesbaren kaufmännischen Schlüssel verwenden müssen, aber nur über den technischen Schlüssel verfügen, würden Sie das Prejoining verwenden, um Ihre Daten mit einer anderen Tabelle zu kombinieren, die die technischen Schlüssel den kaufmännischen Schlüsseln zuordnet.
Wie definiert man Prejoins in DataVault4dbt?
Das DataVault4dbt-Paket bietet eine strukturierte Möglichkeit, diese Prejoins zu definieren (vorverbundene_spalten) unter Verwendung von Wörterbüchern.
Für jede Spalte, die Sie durch Prejoining hinzufügen, müssen Sie ein paar Angaben machen:
- src_name: Dies ist die Quelle der vorverknüpften Daten, wie sie in einer .yml-Datei definiert ist.
- src_table: Dies gibt an, mit welcher Tabelle Sie das Prejoining durchführen, wie in der .yml-Datei angegeben.
- bk: Dies ist der Name der Business Key-Spalte in der Prejoined-Tabelle oder die Spaltenwerte, die Sie in Ihre Tabelle einbringen.
- this_column_name: In Ihren Originaldaten ist dies die Spalte, die mit der vorverknüpften Tabelle übereinstimmt. Dies ist oft ein technischer Schlüssel.
- ref_column_name: In der Pre-Join-Tabelle ist dies die Spalte, auf die this_column_name zeigt. Sie sollte mit den Werten in this_column_name übereinstimmen.
Beachten Sie, dass sowohl "this_column_name" als auch "ref_column_name" entweder eine einzelne Spalte oder eine Liste von Spalten darstellen können, die als Grundlage für die Konstruktion der JOIN-Bedingungen dienen.
Beispiel

- c_name: Wir haben die Spalte "C_NAME" aus der Kundentabelle geholt und auf orders.o_custkey = customer.c_custkey verknüpft.
E. Multiaktive Konfiguration
Die multi_active_config wird verwendet, wenn es sich um Quelldaten handelt, die mehrere aktive Datensätze für denselben Geschäftsschlüssel enthalten. Im Wesentlichen müssen Sie angeben, welche Spalten die mehrfach aktiven Schlüssel und die primäre Hashkey-Spalte sind.
Wenn Ihre Quelldaten keine natürliche Multi-active-Key-Spalte haben, sollten Sie eine solche mit Funktionen wie row_number in einer vorhergehenden Ebene erstellen. Fügen Sie dann den Namen dieser neu erstellten Spalte zum Parameter multi-active-key hinzu. Es ist wichtig, dass die Kombination aus multiaktiven Schlüsseln, Haupt-Hashkey und der ldts-Spalte in der endgültigen Satellitenausgabe eindeutig ist. Wenn Sie diese Einstellung nicht verwenden, wird davon ausgegangen, dass die Stufe nur einzelne aktive Datensätze enthält.
Beispiel
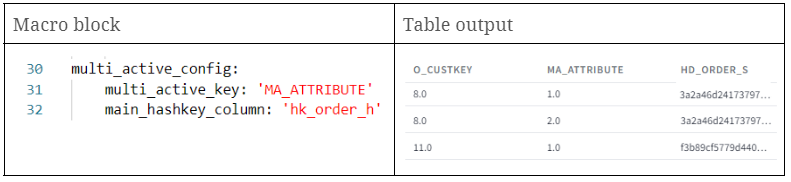
Wenn wir diesen Parameter setzen, werden wir konsistente Hashdiffs für identische Business Keys beobachten, was sich in den nachfolgenden Schichten als vorteilhaft erweist. Wenn Sie wissen wollen, warum, können Sie Folgendes überprüfen diese Stelle.
F. Fehlende Spalten
Mit DataVault4dbt kann die fehlende_Spalten hilft bei der Handhabung von Szenarien, in denen sich das Quellschema ändert und einige Spalten nicht mehr existieren. Mit diesem Parameter können Sie Platzhalterspalten erstellen, die mit NULL-Werten gefüllt werden, um die fehlenden Spalten zu ersetzen. Auf diese Weise wird sichergestellt, dass Hashdiff-Berechnungen und Satelliten-Payloads weiterhin funktionieren. Im Wesentlichen stellen Sie ein Wörterbuch zur Verfügung, in dem die Spaltennamen die Schlüssel und ihre jeweiligen SQL-Datentypen die Werte sind.
Beispiel
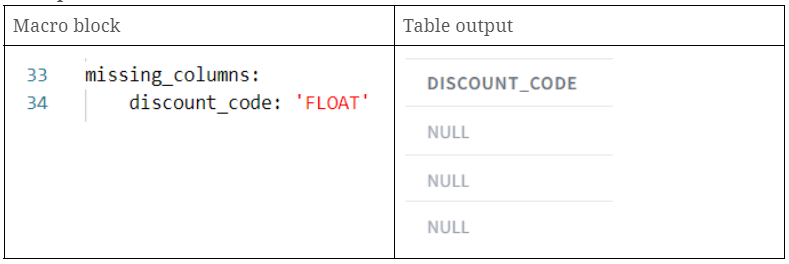
- discount_code: Erstellung einer neuen Spalte discount_code mit NULL-Werten.
Schlussbemerkungen
Scalefree's DataVault4dbt Paket stellt eine einfach zu bedienende und dennoch leistungsstarke Lösung für die Datenbankmodellierung vor. In unserem Fall gingen wir durch die Makro der Bereitstellungsschichtdas bewährte Verfahren mit der Flexibilität kombiniert, verschiedene Quelldatenanforderungen zu erfüllen. Von Hashing bis zu fliegenden Spaltenänderungen - dieses Data Vault 2.0-Open-Source-Paket für dbt rationalisiert komplexe Prozesse.
Da wir sein Potenzial weiter erforschen wollen, laden wir Sie ein, an unserer monatlichen Expertensitzung teilzunehmen, um tiefer in das Thema einzutauchen. Reservieren Sie Ihren Platz hier und bleiben Sie im Github-Repository des Pakets auf dem Laufenden, um die neuesten Updates und Unterstützung zu erhalten.
- Von Hernan Revale (Scalefree)
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Zur Unterstützung bei der Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio wurde eine Schablone entwickelt, mit der Data Vault-Modelle gezeichnet werden können. Die Schablone ist erhältlich bei www.visualdatavault.com.



