A common requirement for enterprise data warehousing is to provide an analytical model for information delivery, for example in a dashboard or reporting solution. One challenge in this scenario is that the required target model, often a dimensional star or snowflake schema or just a denormalized flat-and-wide entity, doesn’t match the source data structure. Instead the end-user of the analytical data will directly or indirectly define the target structure according to the information requirements.
Another challenge is the data itself, regardless of its structure.
In many, if not most, cases, the source data doesn’t meet the information requirements of the user regarding its content. In many cases, the data needs cleansing and transformation before it can be presented to the user.
Instead of just loading the data into a MongoDB collection and wrangling it until it fits the needs of the end user, the Data Vault 2.0 architecture proposes an approach that allows data as well as business rules, which are used for data cleansing in addition to transformation, to be re-used by many users. To achieve this, it is made up of a multi-layered architecture that contains the following layers:
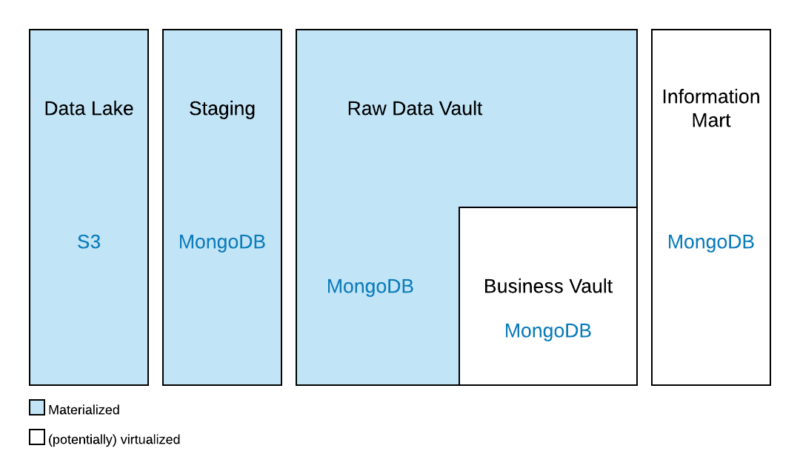
This architecture follows the hybrid architecture in Data Vault 2.0 as it integrates as well as is based upon a data lake where source data is first staged and unstructured data is warehoused.
All layers discussed below will be implemented in only one MongoDB database therefore the whole Enterprise Document Warehouse is utilizing only one database. The reason for this design decision is the fact that it is not possible to perform lookups across databases, which is required for efficiently processing the documents. Therefore, additional importance must be given to the naming conventions of document collections in the individual EDW layers. As an alternative to lookups, the integration process can perform the necessary joins between data sets.
The first layer in MongoDB replicates the data from the data lake that is required for information delivery. Once an information requirement for a dashboard or report has been selected for development, the source data is identified in the data lake and sourced into the staging collection without further modification of the incoming data. The recently released MongoDB Data Lake allows the query of S3-based data lakes directly via the MongoDB Query Language. After the data has been directly made available to MongoDB, the data is then processed further downstream.
The second layer in MongoDB is the enterprise document warehouse (EDW) layer that is built by following Data Vault concepts. When loading the EDW layer, a distinction is made between unmodified raw data from the source collection and implementing business logic. The unmodified raw data is sourced into the Raw Data Vault layer and once the incoming data has been warehoused, business rules are applied in a subsequent step when loading as well as implementing the Business Vault.
Once the business rules have been applied to the raw data in the Raw Data Vault, the target schema is derived from the Data Vault model, Raw Data Vault and Business Vault, into the information mart layer in the architecture.
Due to the architecture of MongoDB, all layers consist of sets of document collections. Therefore, Data Vault entities in the Raw Data Vault and Business Vault as well as information mart entities, often dimensions and facts, must be modelled in document collections.

However, many business intelligence tools for dashboard or reports prefer a relational structure instead of document collections as many business intelligence tools don’t understand document collections. To overcome this issue, MongoDB provides a BI connector that is able to turn the document collection into relational structures. This will become handy later on in the process but should be taken into consideration when designing the documents in the information mart.
There are many advantages of this architecture, first, it separates data warehousing from information processing. This simplifies the process of building an auditable enterprise document warehouse that can be extended and modified in an agile fashion.
It also helps us to re-use the data in MongoDB for many information requirements, thus serving various information subscribers. In addition, one of the advantages of the Data Vault model is there are patterns to derive any target model directly from a Data Vault model, including the original structure, if need be, star schemas, snowflake schemas, fully denormalized schemas, normalized schemas, which are often used for ad-hoc reporting, and any other structure.
Documents are loaded from layer to layer using MongoDBs aggregation pipelines, which is the preferred document processing method in MongoDB. Subsequent articles in our series will discuss the modelling decisions to be made per layer and the appropriate aggregation pipelines to load the collections of each layer.
Comments? Suggestions? Questions?
We’d love to hear from you in the comment section below!