
In Data Vault 2.0, we differentiate data by keys, relationships and description.
That said, an often underestimated point is the handling of relationships in Data Vault 2.0.
In the following we explain what to consider and how to deal with it:
There are different ways to handle the validation of relationships from source systems depending on how the data is delivered, (full-extract or CDC), and the way a delete is delivered by the source system, such as a soft delete or hard delete.
First, let us explain the different kinds of deletes in source systems:
- Hard delete – A record is hard deleted in the source system and no longer appears in the system.
- Soft delete – The deleted record still exists in the source systems database and is flagged as deleted.
Secondly, let’s explore how we find the data in the staging area:
- Full-extract – This can be the current status of the source system or a delta/incremental extract.
- CDC (Change Data Capture) – Only new, updated or deleted records to load data in an incremental/delta way.
To keep the following explanation as simple as possible, our assumption is that we want to mark relationships as deleted as soon as we get the delete information, even if there is no audit trail from the source system (data aging is another topic).
Delete detection for business keys, or Hubs, is straight-forward. Soft deletes are handled as descriptive attributes in the Satellite directly and do not take into account as to whether the data arrives from a full extract or CDC. For hard deletes in the source system, we have to distinguish between full-extract and CDC.
Here we introduce the Effectivity Satellite. In case of:
- Full-extract – Perform a lookup back into the staging area to check whether the business key still exists. If not, add a record with the delete information (i.e. a flag and a date) into the Effectivity Satellite.
- CDC – We receive a “Delete” information which is a new entry in the Effectivity Satellite.
Delete detection of relationships needs a bit more attention and is often forgotten. With a full-extract, we can follow the same approach as followed for business keys: Just check whether or not the Link Hash Key exists in the current staging load and insert a new entry accordingly into the Effectivity Satellite.
But nowadays, CDC is becoming more common. Though, as CDC delivers deltas only, the challenge now is to identify relationships that no longer exist. The example below shows a relationship between the business objects customer and company. This is a 1:n relationship:
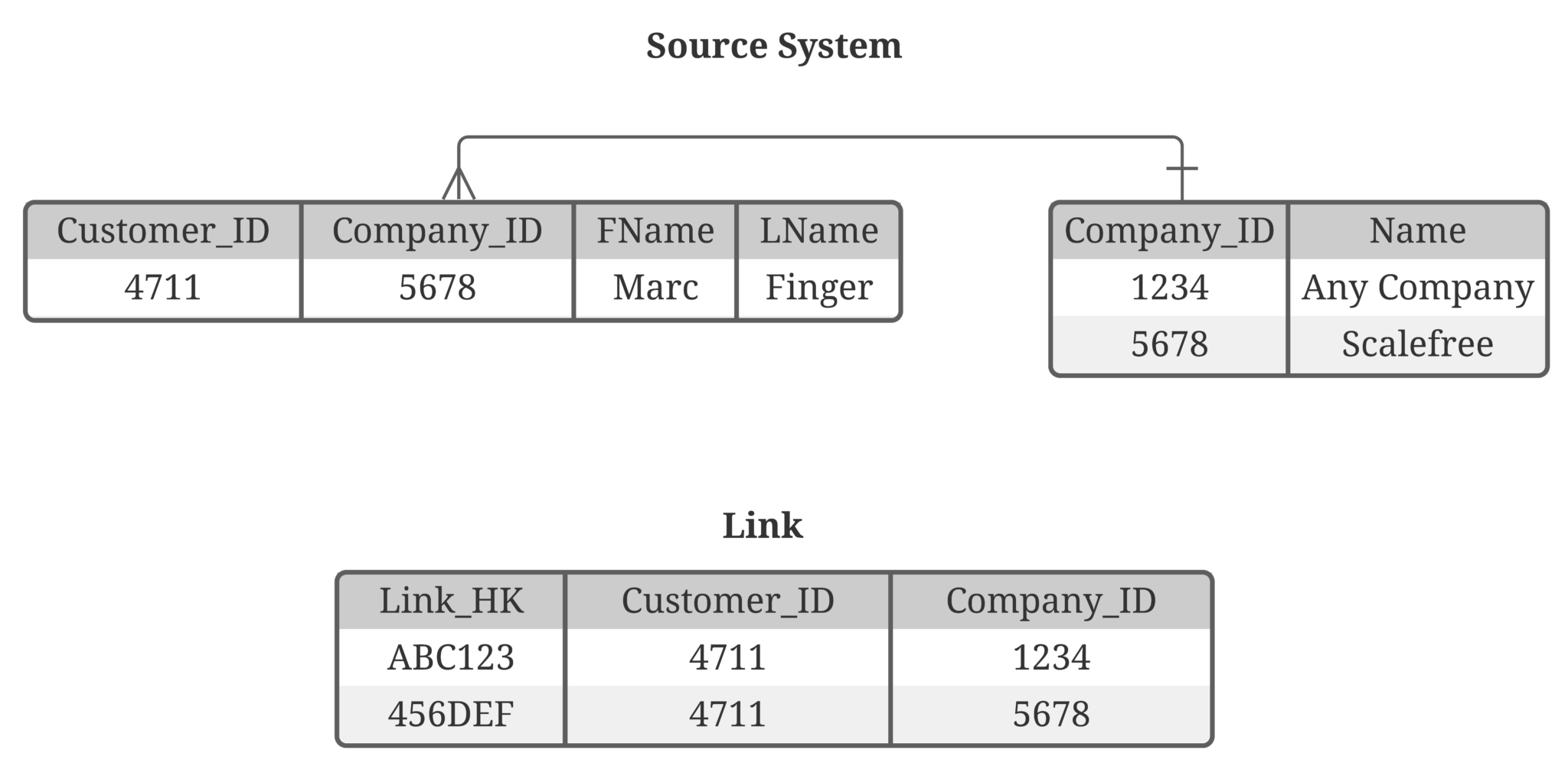
Image 1: Tables Customer and Company
The Link table in Data Vault looks like this:

Table 1: Customer Link
For better readability and simplification, we present the business keys instead of hash keys and don’t show system fields like the load date timestamp and record source.
So far so good, but what happens when the customer is starting to work for another company? This will result in a new record in the Link. The CDC mechanism will provide us the data as an update of the customer table.
Image 2: Source tables and Link after company change
From where do we get the information that the Customer 4711 no longer works for Company 1234 and where is that information stored? We need to soft-delete the old link entry in the data warehouse to make the data consistent again. At the moment, it looks like the customer works for both companies as both links are currently active.
There are two possible ways:
- You get the “from” and the “to” in your audit trail and you identify a difference for the company_id.
If that is the case, create 2 new entries in the Effectivity Satellite, one marks the old one (from) as deleted and the other one marks the new one (to) as not deleted. It is necessary to insert new relationships as “not deleted” that you can activate and deactivate Hash Keys forth and back.
Think about what happens when customer 4711 works for company 1234 again. - In case you don’t have the “from” and “to”, you either have to load the CDC data into a persistent staging area, where you keep the full history of data delivered by CDC, or a source replica, where you create a mirror of the of the source system by feeding it with the CDC data whereby you perform hard updates when an “Updated” comes from the CDC and hard deletes when a “Delete” comes from the CDC.
When using the source replica, you can follow the same approach as stated before when getting full loads: join into the replica and figure out whether the Hash Key still exists or not.
The biggest disadvantage here is that you have to scan more data, which means more IO. When using a persistent staging area, you can figure out a change in a relationship by using the window function lead() where you partition by the technical ID, Customer_ID in this case, and order by the load date timestamp.
As soon as the Link Hash Key is different, the relationship is changed and the old one no longer exists.
The result is the following Effectivity Satellite (logical):
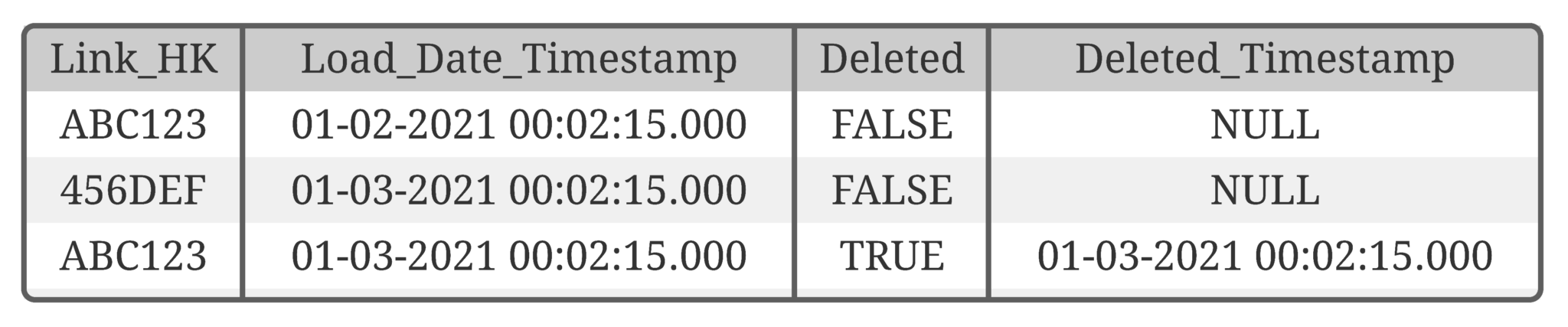
Table 2: Effectivity Satellite on the Link
We covered two major points in this article. The first one is that in Data Vault, we extract relationship information from the source tables and thus we have to pay more attention to the validation of those.
The second point is that the way you get the data (delta by CDC or full-extract) brings you different opportunities regarding the way to load the data. When you are dealing with a huge amount of data, CDC is definitely the way to go. In addition to that, with the CDC mechanism you will get all updates from the source, and you can easier load data in (near) real time.
Feel free to leave your questions and comments in the section below!
– by Marc Finger (Scalefree)
Updates und Support erhalten
Bitte senden Sie Anfragen und Funktionswünsche an [email protected].
Für Anfragen zu Data Vault-Schulungen und Schulungen vor Ort wenden Sie sich bitte an [email protected] oder registrieren Sie sich unter www.scalefree.com.
Um die Erstellung von Visual Data Vault-Zeichnungen in Microsoft Visio zu unterstützen, wurde eine Schablone implementiert, die zum Zeichnen von Data Vault-Modellen verwendet werden kann. Die Schablone ist erhältlich bei www.visualdatavault.com.
Newsletter
Jeden Monat neue Erkenntnisse über Data Vault




The structure of the Effectivity Satellite table makes me think of a Status Tracking Satellite, and they do the same thing: identify deleted links. Why not merge the same concepts of STS for Links instead of having Effectivity satellites.
The purpose of the Status Tracking Satellite is a bit different. The table is completely raw data driven and should be used when no audit trail is available. The Effectivity Satellite instead can be part of the Business Vault, i.e. when you let the data age or data comes from multiple source systems. Then you want to mark the Business Key (or the combination in the Link) as deleted, driven by business rules.
Let us know when you need further assistance here. This is also explained in the Data Vault 2.0 Boot Camps: https://www.scalefree.com/boot-camp-class/
If you have any questions, feel free to contact us or leave another comment.
Prost
Sandra
Hello how the satellite can identify the undeleted records, que consulta puedo hacer para poder identificar
Hi Yomar,
As long as no new Link Hash Key for a Driving Key appears and the Link Hash Key still exists (full load) or you don’t receive a delete information from CDC.
Herzliche Grüße,
Marc
The relationships we create between hub(s) and link, should be always identifying? This understanding is with respect to the fact that link should not have an entry if the respective keys are not present in connected HUB(s)..
Hi Rupa,
thanks for the question!
The Link itself is representing the relationship between Hubs. A Link can have as many Hubs as Business Keys are in relation with each other in your source systems. Imagine an Order: It has a “store”, a “customer”, on line-item level even a “product”. In case there is no key to one of the related Hubs, we still load the entry, otherwise we would lose data. But instead of a NULL key, we add the “Zero Key”.
You can read more about the Zero Key concept here:
– https://www.scalefree.com/blog/data-vault/implementing-data-vault-2-0-zero-keys/
– https://www.scalefree.com/knowledge/webinars/data-vault-friday/zero-key-concepts-in-data-vault/
We also offer trainings where we go through this and many other parts of the Data Vault methodology:
https://www.scalefree.com/trainings/boot-camp-class/
Mit freundlichen Grüßen,
Marc