
Data Lake Struktur - Lösung
Die Organisation von Daten innerhalb eines Data Lake kann die nachgelagerte Zugänglichkeit erheblich beeinflussen. Während das Auslagern von Daten in den Data Lake ein unkomplizierter Prozess ist, besteht die eigentliche Herausforderung darin, diese Daten effizient abzurufen. Die Effizienz des Datenabrufs ist entscheidend für Aufgaben wie die inkrementelle oder erste Enterprise Data Warehouse (EDW) Last und für Data Science Praktiker, die unabhängige Abfragen durchführen. In der Praxis hängt der einfache Zugriff auf die Daten davon ab, wie gut die Daten im Data Lake organisiert sind. Eine gut organisierte Struktur erleichtert reibungslosere Abrufprozesse und unterstützt sowohl EDW-Lasten als auch die unabhängigen Abfrageanforderungen von Datenwissenschaftlern.
Innerhalb einer hybriden Data Warehouse-Architektur, wie sie in der Data Vault 2.0 Boot Camp Ausbildungwird ein Data Lake als Ersatz für einen relationalen Staging-Bereich verwendet. Um die Vorteile dieser Architektur voll ausschöpfen zu können, sollte der Data Lake daher so organisiert sein, dass ein effizienter Zugriff innerhalb eines persistenten Staging Area-Musters und eine bessere Datenvirtualisierung möglich sind.
Der Data Lake in einer hybriden Data Vault-Architektur
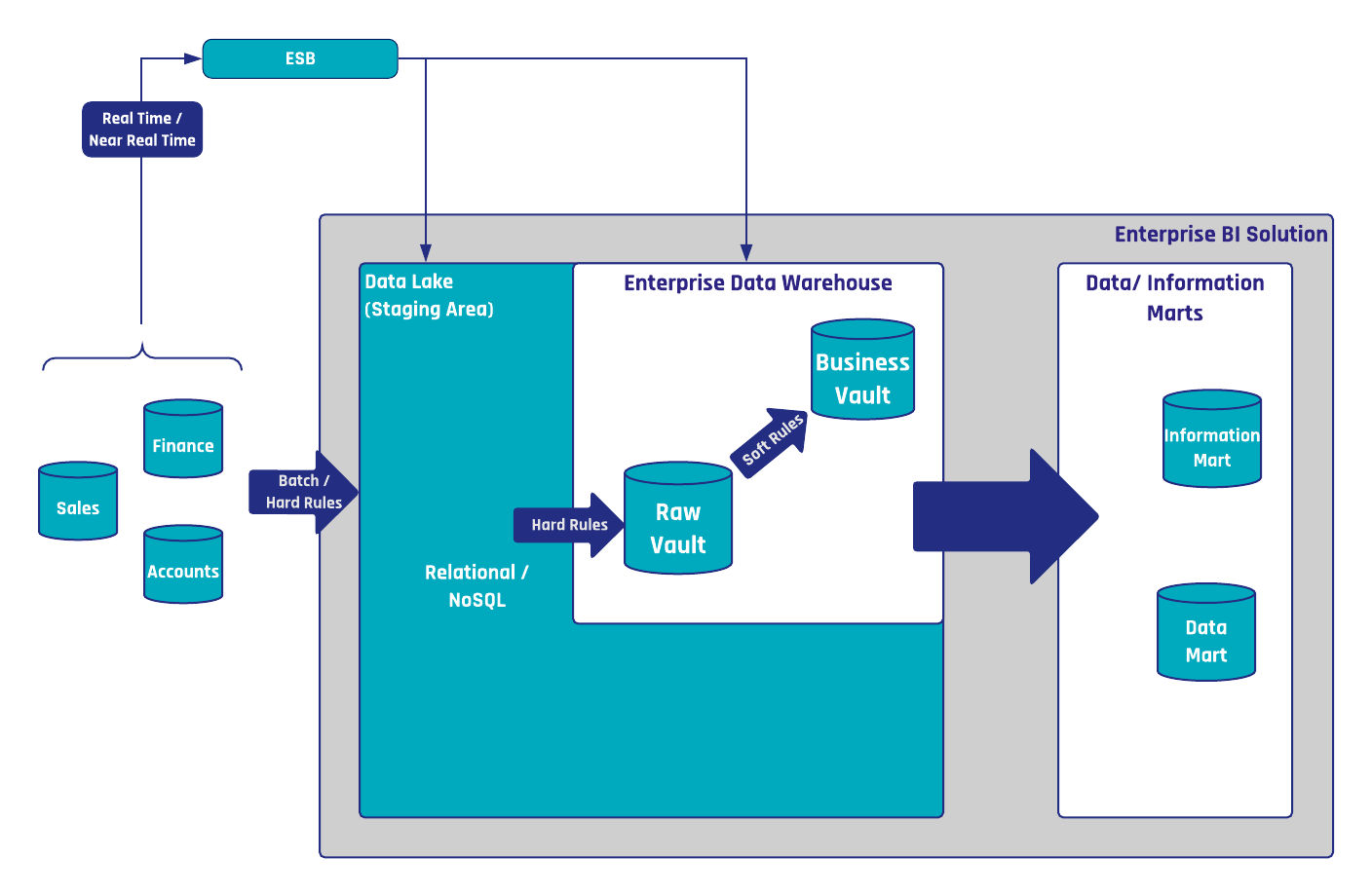
Abbildung 1: Der Data Lake in einer hybriden Data Vault-Architektur
Die Data Lake, wie in Abbildung 1 dargestellt, wird innerhalb der hybriden Architektur als persistente Staging Area (PSA) verwendet. Dies unterscheidet sich vom relationalen Staging, bei der ein persistenter oder transienter Bereitstellungsbereich (TSA) verwendet wird. Eine TSA hat den Vorteil, dass der Aufwand für die Datenverwaltung reduziert wird: Ändert sich z.B. die Quellstruktur, muss die relationale Staging-Tabelle angepasst werden. Ist die Staging-Tabelle also leer, entfällt diese Anpassung. Wird jedoch relationale Technologie zur Erstellung einer PSA verwendet, müssen die historischen Daten in der Tabelle an die neue Struktur angepasst werden. Dies unterscheidet sich von einem Staging-Bereich in einem Data Lake, da im Falle einer Änderung der Quelldaten die historischen Daten in anderen Dateien nicht betroffen sind. Daher ist kein Datenmanagement erforderlich, und in diesem Sinne sind PSAs auf Data Lake den TSAs vorzuziehen. Eine klare Begründung für diese Aussage wird wie folgt dargestellt:
- Es dient nicht nur dem Data Warehouse-Team bei seinen Ladevorgängen, sondern auch den Data Scientists, die direkt auf den Data Lake zugreifen und dabei möglicherweise das EDW ignorieren.
- Full Loads können vom Data Warehouse-Team verwendet werden, um neue Raw Data Vault-Entitäten mit historischen Daten zu initialisieren.
- Dieses Muster könnte verwendet werden, um ein Data Warehouse auf dem Data Lake zu virtualisieren.
Strukturierung des Data Lake für effizienten Datenzugriff
Je nachdem, wie die Daten im Data Lake organisiert sind, kann der Zugriff auf die Daten in Downstream-Prozessen einfach oder schwierig sein. Während es immer einfach ist, Daten in den Data Lake zu verlagern, ist es in der Regel eine Herausforderung, die Daten effizient abzurufen, damit sie von der inkrementellen oder anfänglichen EDW-Beladung und von Data Scientists für unabhängige Abfragen verwendet werden können. Um dies zu bewirken, sollte ein effizienter Data Lake funktional strukturiert sein, was im Wesentlichen bedeutet, dass die Metadaten der Quellsysteme die Organisation des Data Lake bestimmen. Nach unserer Erfahrung ist es immer besser, die folgende Ordnerstruktur zu verwenden:
- Quellsystem: Der erste Ordner enthält den Typ des Quellsystems (z. B. Oracle).
- Verbindung: Ein typisches Unternehmen hat mehrere Verbindungen desselben Quellsystems, z. B. mehrere Oracle-Datenbanken, die in den Data Lake geladen werden müssen. Es ist jedoch darauf zu achten, dass die Bezeichnung für jede Verbindung eindeutig ist. Dies kann durch eine Nummer, einen Code oder eine Abkürzung geschehen.
- Schemaname: Einige Quellsysteme bieten mehrere Schemata oder Datenbanken pro Verbindung. Diese Hierarchie sollte sich in diesem Bereich widerspiegeln und kann tatsächlich aus mehreren Ordnern bestehen.
- Name der Sammlung/Beziehung: Dies ist der Name der Entität oder der REST-Sammlung, die abgefragt werden soll.
- Zeitstempel des Ladedatums: Der LDTS gibt den Zeitstempel des Ladedatums (load date timestamp) der Charge an.
Innerhalb des letzten Ordners (Zeitstempel des Ladedatums) ist es oft von Vorteil, die Daten in mehreren Buckets zu speichern (anstelle einer großen Datei oder sehr kleiner Dateien). Dies verbessert im Allgemeinen die Leistung von Abfragetools, insbesondere wenn die Daten in einem verteilten Dateisystem gespeichert sind. Es wird auch empfohlen, Avro-Dateien zu verwenden, die in der Regel mit Snappy komprimiert werden. Wenn Downstream-Tools dieses Dateiformat nicht unterstützen, können Sie stattdessen entpacktes JSON verwenden. Die Datei selbst sollte zusätzlich zu den Quellattributen die folgenden Attribute aufweisen:
- Zeitstempel des Ladedatums: Viele Tools können den Zeitstempel des Ladedatums nicht aus dem Schlüssel der Datei abrufen.
- Untersequenznummer
Diese Struktur kann mit mehreren Abfrage-Engines verwendet werden (z. B. Apache Drill, Impala, Bienenstockusw.) und haben sich in diesen Szenarien als gut funktionierend erwiesen.
Fazit
Zusammenfassend lässt sich sagen, dass die effektive Strukturierung eines Data Lake von entscheidender Bedeutung ist, um die Effizienz der Datenabfrage zu verbessern, was sowohl den Enterprise Data Warehouse-Prozessen (EDW) als auch den unabhängigen Analysen der Datenwissenschaftler zugute kommt. Die Implementierung eines gut organisierten Data Lake innerhalb einer hybriden Data Vault 2.0, Architektur dient als beständiger Staging-Bereich, der einen nahtlosen Datenzugriff und eine verbesserte Virtualisierung ermöglicht. Dieser Ansatz stellt sicher, dass die Daten sofort verfügbar und optimal strukturiert sind, um die verschiedenen analytischen und betrieblichen Anforderungen zu erfüllen.
- Marc Winkelmann (Scalefree)
the scale margin is very good
It’s in the simplicity and data update system upgrade to modernity