
Data Lake Structure – Solution
The organization of data within a data lake can significantly impact downstream accessibility. While offloading data into the data lake is a straightforward process, the real challenge arises in efficiently retrieving this data. The efficiency of data retrieval becomes crucial for tasks such as the incremental or initial Enterprise Data Warehouse (EDW) load and for data science practitioners conducting independent queries. In practice, the ease of accessing data downstream depends on how well the data is organized within the data lake. A well-organized structure facilitates smoother retrieval processes, empowering both EDW loads and the independent querying needs of data scientists.
Within a hybrid data warehouse architecture, as promoted in the Data Vault 2.0 Boot Camp training, a data lake is used as a replacement for a relational staging area. Thus, to take full advantage of this architecture, the data lake is best organized in a way that allows efficient access within a persistent staging area pattern and better data virtualization.
The Data Lake in a Hybrid Data Vault Architecture
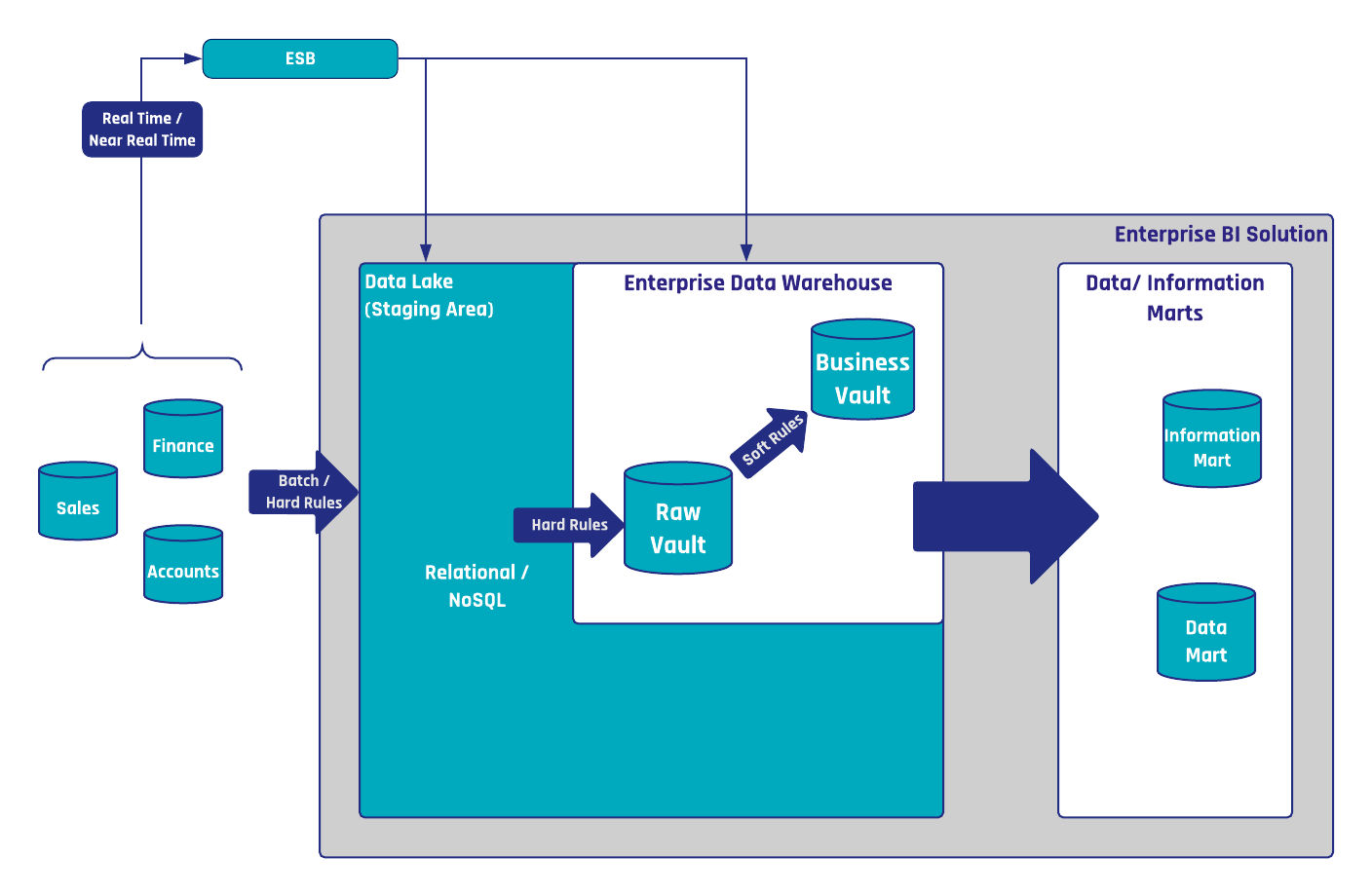
Figure 1: The Data Lake in a Hybrid Data Vault Architecture
The data lake, as shown in Figure 1, is used within the hybrid architecture as a persistent staging area (PSA). This is different to relational staging in which a persistent or transient staging area (TSA) is used. As a TSA has the advantage that the needed effort for data management is reduced: e.g. if the source structure is changing, the relational stage table must be adjusted. Thus, if the stage table is empty, data management doesn’t occur. However, if relational technology is used to create a PSA, the historical data within the table must be modified to match the new structure. This is different from a staging area on a data lake as in the instance that the source data changes, the historical data in other files is not affected. Therefore, no data management is necessary and with that in mind, PSAs on data lake are preferred over TSAs. A clear reasoning for this statement is illustrated as:
- It not only serves the data warehouse team in their loading jobs, but it also serves data scientists who directly access the data lake, potentially ignoring the EDW.
- Full loads can be used by the data warehouse team to initial load new Raw Data Vault entities with historical data.
- This pattern could be used to virtualize the data warehouse on top of the data lake.
Structuring the Data Lake for Efficient Data Access
Depending on the organization of the data in the data lake, the data may be easy to access downstream or not. While it is always easy to offload data into the data lake, it’s typically a challenge to retrieve the data efficiently so it could be used by the incremental or initial EDW load and by data scientists for independent queries. To that effect, an efficient data lake is functionally structured which essentially means that the meta-data of the source systems drive the organization of the data lake. In our experience, it is always a better practice to have the following folder structure:
- Source system: The first folder is the type of source system (e.g. Oracle).
- Connection: The typical enterprise organization has multiple connections of the same source system, e.g. multiple Oracle databases, that need to be loaded into the data lake. Though please note to ensure that the identifier is unique as per each connection. This can be done using a number, a code or abbreviation.
- Schema name: Some source systems provide multiple schemas, or databases, per connection. This hierarchy should be reflected in this area and may actually consist of multiple folders.
- Collection/Relation name: This is the name of the entity or REST collection to be queried.
- Load date timestamp: The LDTS indicates the load date timestamp of the batch.
Within the last folder (load date timestamp) it is often an advantage to store the data in multiple buckets (instead of one large file or very small files). It generally improves the performance of query tools, especially when the data is stored in a distributed file system. It is also recommended to utilize Avro files, usually compressed using Snappy, though if downstream tools don’t support this file format, use unzipped JSON instead. The file itself should have the following attributes, in addition to the source attributes:
- Load Date Timestamp: many tools cannot retrieve the load date time stamp from the file’s key
- Sub sequence number
This structure can be used with multiple query engines (e.g. Apache Drill, Impala, Hive, etc.) and have proven to work in these scenarios well.
Conclusion
In summary, structuring a data lake effectively is crucial for enhancing data retrieval efficiency, which benefits both Enterprise Data Warehouse (EDW) processes and data scientists’ independent analyses. Implementing a well-organized data lake within a hybrid Data Vault 2.0 architecture serves as a persistent staging area, facilitating seamless data access and improved virtualization. This approach ensures that data is readily available and optimally structured to meet diverse analytical and operational needs.
– Marc Winkelmann (Scalefree)
the scale margin is very good
It’s in the simplicity and data update system upgrade to modernity