Ensuring Data Quality
Poor data quality can lead to inaccurate insights, flawed decision-making, and ultimately, compromised business success. In the era of big data, organizations rely heavily on data warehouses to store, manage, and analyze vast amounts of information. However, the effectiveness of a data warehouse depends on the quality of the data it contains. How can high-quality data be ensured?
In this blog article, we will dive into the significance of data quality in an enterprise data warehouse and provide practical strategies to ensure accurate, reliable, and high-quality data with Data Vault 2.0.
You also might want check out the webinar recording about this exact topic. Watch it here for free!
Ensuring Data quality in your data warehouse
In today’s data-driven culture, organizations rely heavily on their data warehouses to make informed decisions. However, the effectiveness of a data warehouse depends on the quality of the data it contains. In this presentation, we will dive into the significance of data quality and provide practical strategies to ensure accurate, reliable, and high-quality data with Data Vault 2.0.
What are the reasons for bad data?
Data quality refers to the accuracy, completeness, consistency, and reliability of data. In the context of a data warehouse, maintaining high data quality is crucial to derive meaningful insights and make informed decisions. Several factors contribute to the presence of poor or bad data. Identifying and understanding these reasons is essential for implementing effective data quality management strategies. Here are some common reasons for bad data in a data warehouse:
- Incomplete or missing source data
- Lack of standardizations
- Data transformation issues
- Poor data governance
- Insufficient validation and quality checks
- Lack of user training and awareness
Data quality techniques
A variety of data quality techniques exist and there is no single best option for all issues. The difficulty lies in understanding the current situation and in understanding the strengths and weaknesses of the techniques available. In fact, the effectiveness of the techniques varies depending on the context. A given technique fits well in some situations and poorly in others. Scott Ambler developed five comparison factors appropriate to consider the effectiveness of a data quality technique. These factors, that are shown below, are intended to help you choose the right DQ technique for the situation you face:
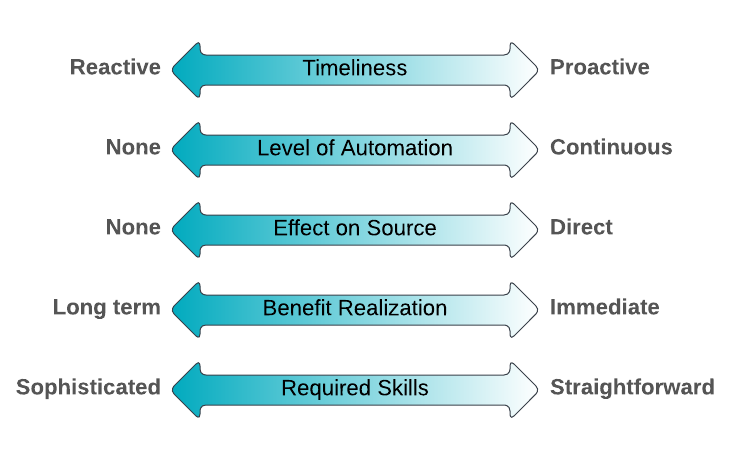
Source: https://agiledata.org/essays/dataqualitytechniquecomparison.html
- Timeliness: Are you reacting to a discovered DQ issue or are you applying it to proactively avoid or reduce DQ issues?
- Level of automation: To what extent is automation possible? A continuous technique would be automatically invoked as appropriate.
- Effect on source: Does the technique have any effect on the actual data source?
- Benefit realization: Will the benefit of the quality improvement be immediate or is a long-term benefit to be expected?
- Required skills: Does the technique require demanding skills that may need to be gained through training/experience or is the technique easy to learn?
The benefit of the Data Vault 2.0 approach
When bad data is detected, the first thing to do is perform a root cause analysis. What if the bad data originates from the source? The best approach would be to fix the errors directly in the source system. However, this method is often rejected as it is considered to be costly. Since the sources are out of the scope of a data warehousing team, we need to find a way to clean the bad data somewhere in our architecture. In Data Vault 2.0, we consider a data cleansing routine as a business rule (soft rule) whereby those rules are implemented in the Business Vault.
In the shown architecture (Figure 1) there is a Quality Layer integrated into the Business Vault where the data cleansing routines are performed. The purpose is to make the cleansed data highly reusable for downstream business vault and information mart objects. If the data quality rules change, or new knowledge regarding the data is obtained, it is possible to adjust the rules without having to reload any previous raw data.
Now, the data is ready for use in any dashboarding or reporting tool. It is also possible to write the cleansed data back to the source. For this purpose, the data is provided to an Interface Mart which in turn sends the data back to the source system itself. In this way, business users can utilize the high-quality data inside their source applications as well. The next time when loading the raw data into the Raw Data Vault, the data is already cleansed.
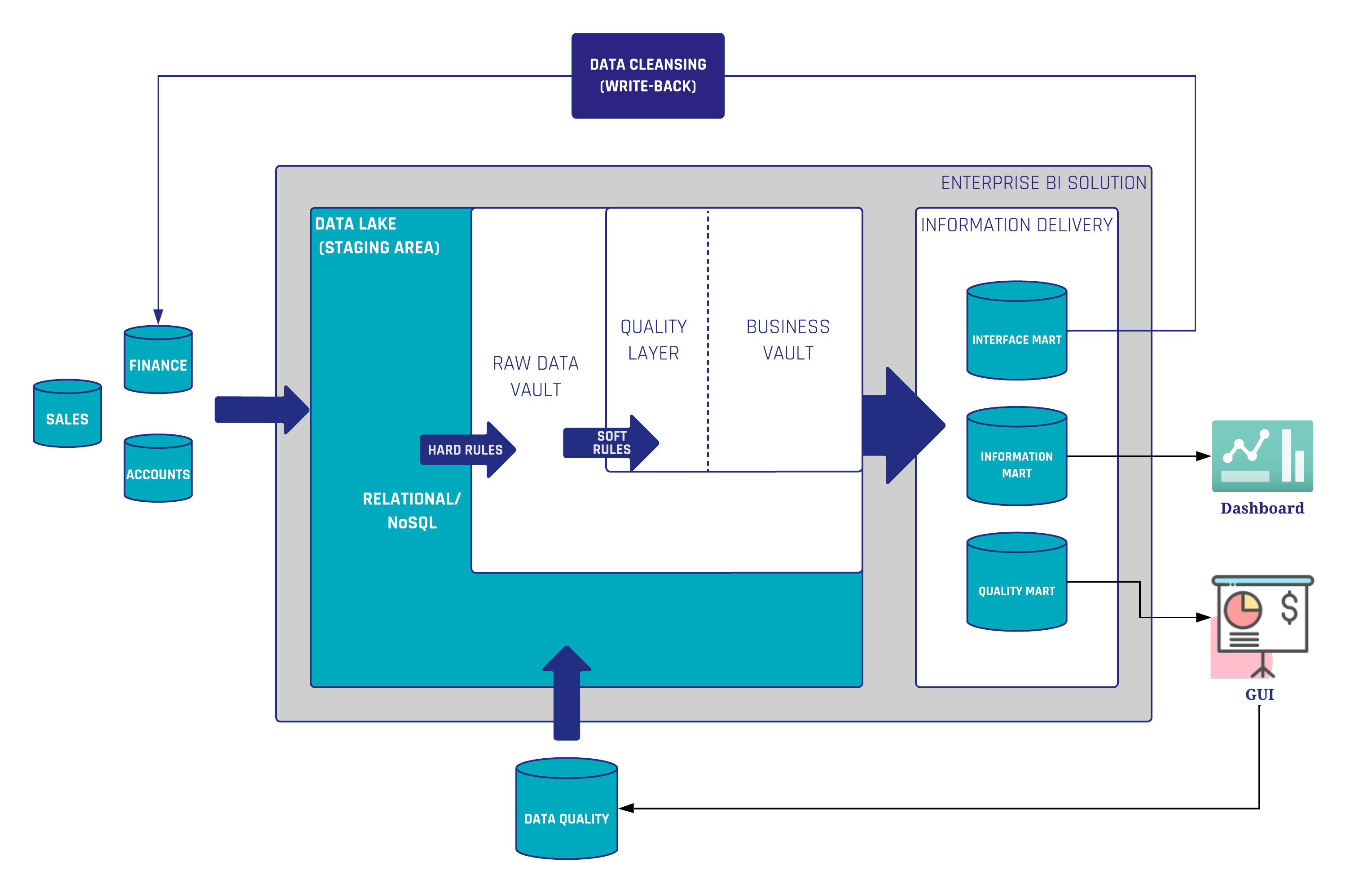
The second use case described in Figure 1 is the monitoring of bad data by a so-called quality mart. The quality mart is part of the information delivery layer and selects all the bad data instead of the cleansed data. Based on this, reports or graphical user interfaces can be created for the data steward. In addition, the data steward can leave comments on certain records that should not be considered bad data or are exceptions to the rules. This user interface stores all added data (comments, flags, etc.) in a database, which in turn serves as a source for the Data Vault. This data can be used to extend the business rules. In particular, to filter out the exceptions to the data cleansing rules.
Another advantage of Data Vault 2.0 are the high pattern-based and standardized entities. This enables a simple and automated development of technical tests. Once created for each Data Vault entity, these tests can be applied to both the Raw Data Vault entities and the Business Vault entities. This ensures a consistent and auditable data warehouse. Check out this blog article, if you need more in-depth information regarding technical tests in Data Vault.
Common data quality techniques
In the last section, we have already described a few techniques for ensuring high data quality in a Data Vault 2.0 architecture. Of course, there are a number of other techniques that are independent of which modeling approach is used. In addition, some techniques do not focus primarily on data quality, but they still have a positive influence on it. Let’s have a closer look on some of them below:
- Validation of business rules: At this point, we have to distinguish between data quality and information quality. Data quality focuses on the intrinsic characteristics of the data, addressing issues such as errors, inconsistencies, and completeness at the granular level. Information quality is a broader concept that encompasses not only the quality of individual data elements but also the overall value and usefulness of the information derived from those data. Beyond that, what is useful information for one business case may not be sufficient for another. For this reason, the business users must be heavily involved in this process, for example through user acceptance tests.
- Data Governance involves defining roles, responsibilities, and accountability for data quality, ensuring that data is treated as a valuable organizational asset. Develop and enforce data governance frameworks, including data quality standards, stewardship responsibilities, and documentation.
- Data Guidance and Standardization ensures uniformity in formats, units, and values across the data warehouse, reducing the risk of errors caused by variations in data representation. Establish and enforce standardized naming conventions, units of measure, formatting rules, and data security/privacy conventions. Moreover, Data Vault 2.0 is very helpful in this regard, as all entities are highly standardized and automatable.
- Data Steward: As part of the Data Governance practice, a data steward is an oversight/governance role within an organization and is responsible for ensuring the quality and fitness for purpose of the organization’s data.
- Continuous Integration (CI) is a development practice where developers integrate their work frequently. Successful tests should be an obligatory condition for introducing any new change to your EDW code base. That is achievable by using DevOp tools and enabling continuous integration in your development lifecycle. Running automated tests each time code is checked or merged ensures that any data consistency issues or bugs are detected early and fixed before they are put into production.
- A Review is a peer review of the implementation (source code, data models etc.). Developing a strong review process sets a foundation for continuous improvement and should become part of a development team’s workflow to improve quality and ensure that every piece of code has been looked at by another team member.
- User training and Awareness: Educate users on the importance of data quality and provide training on the necessary topics and skills. Foster a culture of data quality awareness within the organization to encourage proactive identification and resolution of data quality issues.
Conclusion
There is no question that high data quality is essential for a successful data warehousing project. The process towards high data quality is not a one-time effort but an ongoing commitment. It is a multifaceted process that involves a combination of techniques, collaboration across teams, and fostering a culture of data stewardship.
In this article, we have addressed the causes of bad data and discussed various techniques for dealing with these issues. More accurately, we described how to implement data quality techniques within a Data Vault 2.0 architecture.
If you want to dive deeper into Data Quality then remember to watch the free webinar recording.
– Julian Brunner (Scalefree)
