Naming Conventions in Data Warehousing
Throughout this article, we will continue presenting our suggestions for naming conventions in a data warehouse solution, as well as sharing examples for naming standards, which both our team and our customers utilize internally. You can also find our previous blog post, where discussed the different aspects of a naming standard documentation – from letter case types to the consideration between using prefixes or suffixes in database object names.
Layer Schema
For layer schema names, we prefer using prefixes.
As discussed in the previous blog post, this convention boosts visibility in data exploration within the Enterprise Data Warehouse for developers and business users by grouping schemas of the same data warehouse layer together.
The following is a list of common Enterprise Data Warehouse layers and our associated recommendations regarding naming conventions:
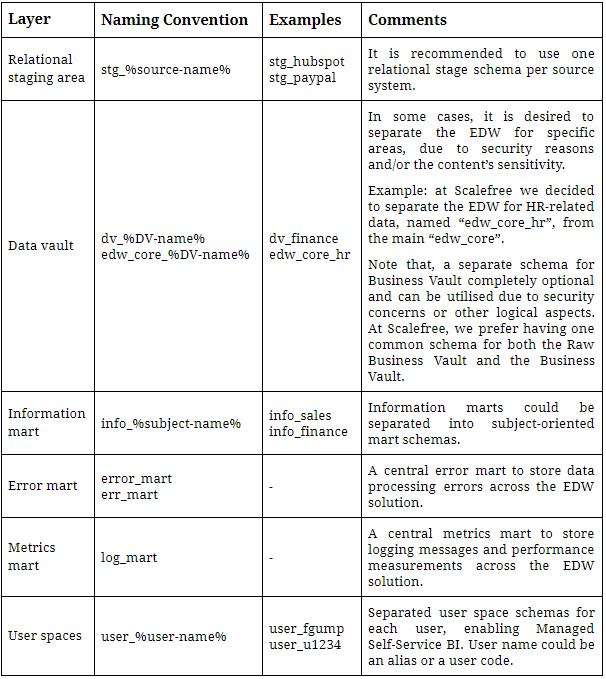
Figure 1: Recommended Naming Conventions for Common Enterprise Data Warehouse Layers
EDW/Data vault entities
As discussed in the previous section, we do not separate the Raw Data Vault and the Business Vault into different database schemas. Instead, users will be able to distinguish between a Raw Vault entity and a computed one via the entity name.
The following is a list of naming conventions for standard Data Vault 2.0 entities in addition to more advanced entity types.
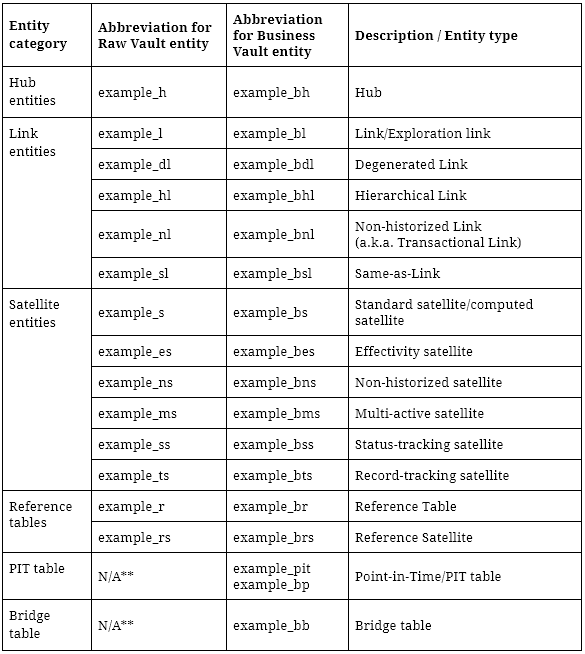
**Note: PIT and bridge tables are only available in Business Vault
Figure 2: Naming Conventions for Standard Data Vault Entities
More about naming conventions for satellite entities
Satellite splitting criteria play a vital role in the naming conventions for satellite structures. In fact, it is not recommended that all descriptive data of a business object be stored in a single satellite structure – instead, raw data should preferably be split by certain criteria. ( Linstedt, D., & Olschimke, M. (2016). Building a scalable Data Warehouse with Data Vault 2.0. P114-115)
At Scalefree, we have defined three types of satellite splits:
- split by source system
- technical split by rate of change, security level and privacy level
- and business-driven split
A satellite split by source system and the technical split by rate of change of data are common, recommended practices when it comes to splitting descriptive attributes. However, we have decided to split raw data even further, both technically and by business meaning.
As such, our full naming convention for satellite entities is as follows:
[parent-obj]_[biz-split]_[src]_[tech-split]_[satellite-type-suffix]
With:
[parent-obj] = the name of the satellite parent’s business object
[biz-split] = the business classification,
[src] = an abbreviation for the source system and
[tech-split] = a combination of technical satellite splitting criteria.
Please note that the split denoted by different security levels classifies data into security groups. Thus, end users are given access to only certain groups of tables corresponding to their clearance level.
As part of our process, the security levels range from:
- the lowest confidentiality level – level 0, 1: no security measure required, for public data,
- to limited access to certain internal parties – level A, R, C, F.
- to the highest confidentiality level – level S: top secret.
It is important to take note that the final technical satellite splitting criterion within Scalefree’s SOP is defined by the split in privacy level. This split is a necessary component of the process as it separates personal and non-personal information from each other.
Moving onwards, the business-driven satellite split distributes raw data into different satellite tables utilizing certain business meanings of data content.
We have defined several classifications for this purpose, to name a few: “contact” for contact data and “activity” for data that tracks the interactions users have made with the source record.
Additionally, data modelers can define custom business classifications for specified unique business meanings in business objects.
For example, all data attributes of an application installed on the CRM platform Salesforce are often stored within a single satellite structure. Thus, the business-driven satellite split aims to boost usability and accessibility of the EDW for end users. It does so by assisting users in finding the data they require within the DWH in a way that is both faster and easier by classifying data into groups that have actual meaning to business users.
Putting everything together, here’s an example of a satellite name in our internal EDW solution:
customer_contact_sfdc_lcp_s
The above is a satellite of business object Customer and holds customers’ contact information from the source system Salesforce. Thus, its content has a low rate of change, a security level of C and contains personal data.
Conclusion
In this article, we’ve presented our recommendations regarding naming conventions for different types of data warehouse objects and offered an in-depth look into our considerations for satellite naming.
Are you interested in other naming standard aspects? Let us know in the comments section!
– by Trung Ta
